阿里云天池算法挑战赛零基础入门NLP - 新闻文本分类-Day2-数据读取与数据分析
Posted 202xxx
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿里云天池算法挑战赛零基础入门NLP - 新闻文本分类-Day2-数据读取与数据分析相关的知识,希望对你有一定的参考价值。
一、赛题解析
【阿里云天池算法挑战赛】零基础入门NLP - 新闻文本分类-Day1-赛题理解_202xxx的博客-CSDN博客
二、数据读取
下载完成数据后推荐使用anaconda,python3.8进行数据读取与模型训练
首先安装需要用到的模块包:
pip版本:
pip添加国内源,增加下载速度_202xxx的博客-CSDN博客
pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
conda版本:
新建conda虚拟环境:
conda create --name py38 python=3.8
conda activate py38conda install pandas用读取数据,train_dir为训练集的存储路径,nrows为读取数据的行数
import pandas as pd
train_dir = '../data/train_set.csv'
nrows=None
train_df = pd.read_csv(train_dir, sep='\\t', nrows=nrows)查看前5条新闻数据
train_df.head()| label | text | |
|---|---|---|
| 0 | 2 | 2967 6758 339 2021 1854 3731 4109 3792 4149 15... |
| 1 | 11 | 4464 486 6352 5619 2465 4802 1452 3137 5778 54... |
| 2 | 3 | 7346 4068 5074 3747 5681 6093 1777 2226 7354 6... |
| 3 | 2 | 7159 948 4866 2109 5520 2490 211 3956 5520 549... |
| 4 | 3 | 3646 3055 3055 2490 4659 6065 3370 5814 2465 5... |
三、数据分析
句子长度分布
统计每篇新闻的长度(词的数量)
import matplotlib.pyplot as plt
train_df['text_len'] = train_df['text'].apply(lambda x: len(x.split(' ')))
print(train_df['text_len'].describe())用describe()函数得到新闻长度的统计特征值
count 200000.000000
mean 907.207110
std 996.029036
min 2.000000
25% 374.000000
50% 676.000000
75% 1131.000000
max 57921.000000
Name: text_len, dtype: float64得到训练数据新闻总数为200000篇,其中最短的新闻字数为2,最长的新闻字数为57921,平均紫薯为907.2
绘制句子长度的直方图:
_ = plt.hist(train_df['text_len'], bins=200)
plt.xlabel('Text char count')
plt.title("Histogram of char count") 可见大部分句子长度都在6000以内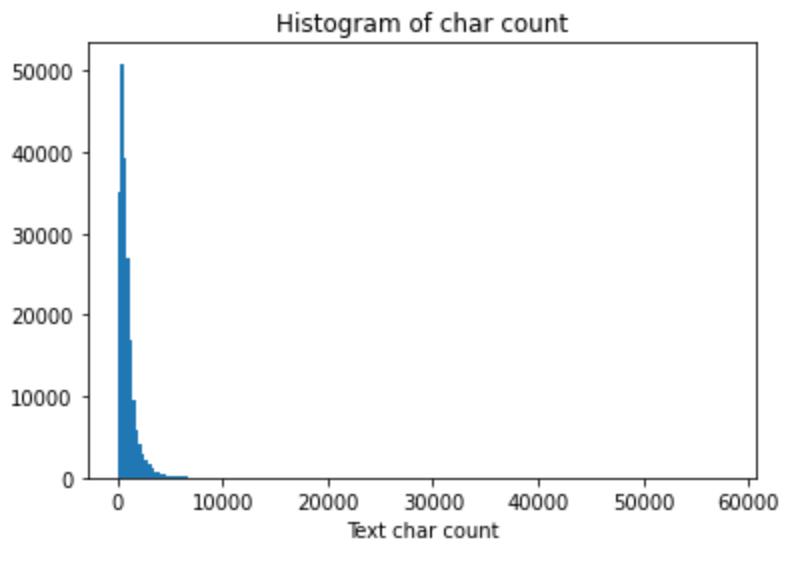
新闻类别分布
绘制新闻类别标签的统计直方图
train_df['label'].value_counts().astype("object").plot(kind='bar')
plt.title('News class count')
plt.xlabel("category")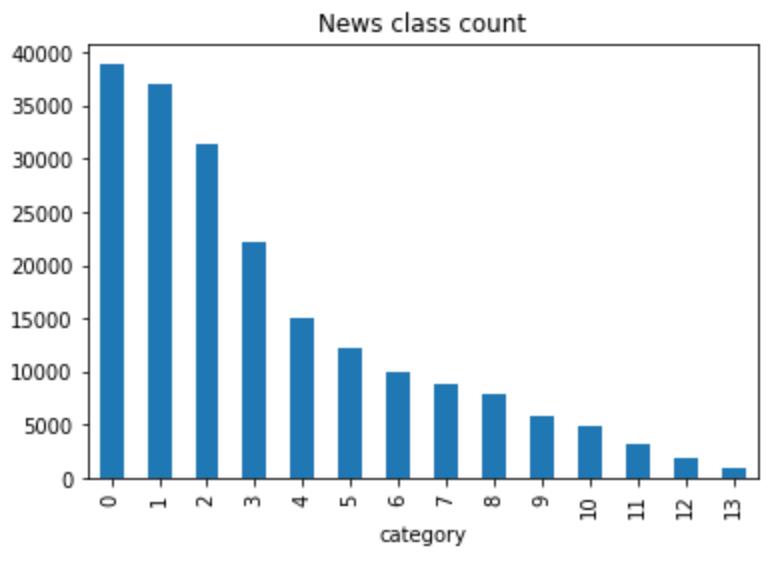
在数据集中标签的对应的关系如下:{'科技': 0, '股票': 1, '体育': 2, '娱乐': 3, '时政': 4, '社会': 5, '教育': 6, '财经': 7, '家居': 8, '游戏': 9, '房产': 10, '时尚': 11, '彩票': 12, '星座': 13}
可以看出数量最多的新闻为科技类,最少的为星座类。
字符分布统计
将训练数据所有字符进行合并,统计出每个字符出现的频数
from collections import Counter
all_lines = ' '.join(list(train_df['text']))
word_count = Counter(all_lines.split(" "))
word_count = sorted(word_count.items(), key=lambda d:d[1], reverse = True)
print(len(word_count))
print(word_count[0])
print(word_count[-1])可以得到,训练数据用到的字符数为6869个,其中用的最多的字符编号为“3750”,用了748万次,最少字符编号为“3133”,用了2次:
6869
('3750', 7482224)
('3133', 1)现对每篇文章字符进行去重再统计
from collections import Counter
train_df['text_unique'] = train_df['text'].apply(lambda x: ' '.join(list(set(x.split(' ')))))
all_lines = ' '.join(list(train_df['text_unique']))
word_count = Counter(all_lines.split(" "))
word_count = sorted(word_count.items(), key=lambda d:int(d[1]), reverse = True)
print(word_count[0])
print(word_count[1])
print(word_count[2])可以得到用到编号“3750”的文章数量有197997篇,总文章数量为200000篇,因此可以猜测其为标点符号。
('3750', 197997)
('900', 197653)
('648', 191975)四、作业思路
1. 假设字符3750,字符900和字符648是句子的标点符号,请分析赛题每篇新闻平均由多少个句子构成?
答:分别统计每篇新闻中包含有字符3750,字符900和字符648的数量,每篇新闻的句子数量=标点符号出现的数量,因此求平均可以得到每篇新闻平均由多少个句子构成。等价于已知道200000篇新闻中出现字符3750的数量为7482224次,字符900的数量为3262544,字符648的数量为4924890。求平均得到每篇新闻的句子数量为78.
#作业1
from collections import Counter
all_lines = ' '.join(list(train_df['text']))
word_count = Counter(all_lines.split(" "))
print(word_count["3750"])
print(word_count["900"])
print(word_count["648"])
print((word_count["3750"] + word_count["900"] + word_count["648"])/train_df.shape[0])2.统计每类新闻中出现次数最多的字符?
答:根据label对df中的text新闻进行分组拼接,分别计算每个label中的新闻最大字符和数量
train_df_label = train_df[["label", "text"]].groupby("label").apply(lambda x:" ".join(x["text"])).reset_index()
train_df_label.columns = [["label", "text"]]
from collections import Counter
train_df_label['text_max'] = train_df_label["text"].apply(lambda x:sorted(Counter(x["text"].split(" ")).items(), key=lambda d:int(d[1]), reverse = True)[0], axis = 1)
train_df_label| label | text | text_max | |
|---|---|---|---|
| 0 | 0 | 3659 3659 1903 1866 4326 4744 7239 3479 4261 4... | (3750, 1267331) |
| 1 | 1 | 4412 5988 5036 4216 7539 5644 1906 2380 2252 6... | (3750, 1200686) |
| 2 | 2 | 2967 6758 339 2021 1854 3731 4109 3792 4149 15... | (3750, 1458331) |
| 3 | 3 | 7346 4068 5074 3747 5681 6093 1777 2226 7354 6... | (3750, 774668) |
| 4 | 4 | 3772 4269 3433 6122 2035 4531 465 6565 498 358... | (3750, 360839) |
| 5 | 5 | 2827 2444 7399 3528 2260 6127 1871 119 3615 57... | (3750, 715740) |
| 6 | 6 | 5284 1779 2109 6248 7039 5677 1816 5430 3154 1... | (3750, 469540) |
| 7 | 7 | 6469 1066 1623 1018 3694 4089 3809 4516 6656 3... | (3750, 428638) |
| 8 | 8 | 2087 730 5166 3300 7539 1722 5305 913 4326 669... | (3750, 242367) |
| 9 | 9 | 3819 4525 1129 6725 6485 2109 3800 5264 1006 4... | (3750, 178783) |
| 10 | 10 | 26 4270 1866 5977 3523 3764 4464 3659 4853 517... | (3750, 180259) |
| 11 | 11 | 4464 486 6352 5619 2465 4802 1452 3137 5778 54... | (3750, 83834) |
| 12 | 12 | 2708 2218 5915 4559 886 1241 4819 314 4261 166... | (3750, 87412) |
| 13 | 13 | 1903 2112 3019 3607 7539 3864 4939 4768 3420 2... | (3750, 33796) |
五、总结
根据不同的维度,分别提取新闻的特征,为模型训练作准备。
六、Reference
tianchi_competition/零基础入门NLP - 新闻文本分类 at main · RxxxxR/tianchi_competition · GitHub
Datawhale零基础入门NLP赛事 - Task2 数据读取与数据分析-天池实验室-实时在线的数据分析协作工具,享受免费计算资源
以上是关于阿里云天池算法挑战赛零基础入门NLP - 新闻文本分类-Day2-数据读取与数据分析的主要内容,如果未能解决你的问题,请参考以下文章