如何使用python3爬取1000页百度百科条目
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何使用python3爬取1000页百度百科条目相关的知识,希望对你有一定的参考价值。
参考技术A1 问题描述
起始页面 ython 包含许多指向其他词条的页面。通过页面之间的链接访问1000条百科词条。
对每个词条,获取其标题和简介。

2 讨论
首先获取页面源码,然后解析得到自己要的数据。
这里我们通过urllib或者requests库获取到页面源码,然后通过beautifulsoup解析。
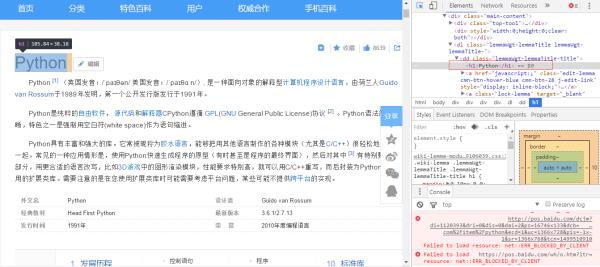
可以看到,标题是在<h1></h1>标签下的。
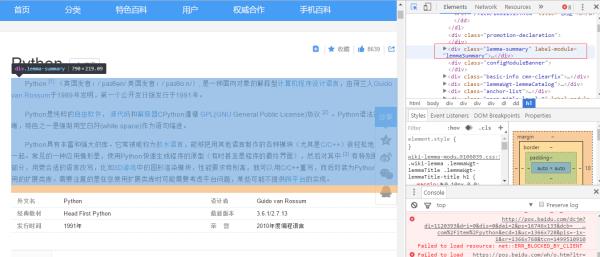
可以看出,简介是在class为lemma-summary的div下的。

可以看出,其他词条的格式都遵循hcom/item/xxx的形式
3 实现
# coding=utf-8from urllib import requestfrom bs4 import BeautifulSoupimport reimport tracebackimport time
url_new = set()
url_old = set()
start_url = 'httpm/item/python'max_url = 1000def add_url(url):
if len(url_new) + len(url_old) > 1000: return
if url not in url_old and url not in url_new:
url_new.add(url)def get_url():
url = url_new.pop()
url_old.add(url) return urldef parse_title_summary(page):
soup = BeautifulSoup(page, 'html.parser')
node = soup.find('h1')
title = node.text
node = soup.find('div', class_='lemma-summary')
summary = node.text return title, summarydef parse_url(page):
soup = BeautifulSoup(page, 'html.parser')
links = soup.findAll('a', href=re.compile(r'/item/'))
res = set()
baikeprefix = 'htt.baidu.com'
for i in links:
res.add(baikeprefix + i['href']) return resdef write2log(text, name='d:/baike-urllib.log'):
with open(name, 'a+', encoding='utf-8') as fp:
fp.write('\\n')
fp.write(text)if __name__ == '__main__':
url_new.add(start_url) print('working')
time_begin=time.time()
count = 1
while url_new:
url = get_url() try:
resp = request.urlopen(url)
text = resp.read().decode()
write2log('.'.join(parse_title_summary(text)))
urls = parse_url(text) for i in urls:
add_url(i) print(str(count), 'ok')
count += 1
except:
traceback.print_exc() print(url)
time_end=time.time() print('time elapsed: ', time_end - time_begin) print('the end.')
输出结果
working1 ok
略983 ok984 ok
time elapsed: 556.4766345024109the end.
将urllib替换为第三方库requests:
pip install requests
略if __name__ == '__main__':
url_new.add(start_url) print('working')
time_begin = time.time()
count = 1
while url_new:
url = get_url() try: with requests.Session() as s:
resp = s.get(url)
text = resp.content.decode() # 默认'utf-8'
write2log('.'.join(parse_title_summary(text)))
urls = parse_url(text) for i in urls:
add_url(i) print(str(count), 'ok')
count += 1
except:
traceback.print_exc() print(url)
time_end = time.time() print('time elapsed: ', time_end - time_begin) print('the end.')
输出
略986 ok987 ok988 ok989 ok
time elapsed: 492.8088216781616the end.
一个通用的爬虫架构包括如下四部分:
调度器
URL管理器
网页下载器
网页解析器
从以上函数式的写法也可以看出了。
下面是面向对象的写法。
$ ls html_downloader.py html_outputer.py html_parser.py spider_main.py url_manager.py1、spider main
# coding=utf-8from ex.url_manager import UrlManagerfrom ex.html_downloader import HtmlDownloaderfrom ex.html_parser import HtmlParserfrom ex.html_outputer import HtmlOutputerimport traceback, timeclass SpiderMain():def __init__(self):
self.urls = UrlManager() self.downloader = HtmlDownloader() self.parser = HtmlParser() self.outputer = HtmlOutputer() def crawl(self, url):
self.urls.add_url(url)
count = 1
while self.urls.is_has_url():
url = self.urls.get_url() try:
page = self.downloader.download(url)
data, newurls = self.parser.parse(page) self.urls.add_urls(newurls) self.outputer.write2log(data) print(str(count), 'ok') except:
traceback.print_exc() print(str(count), 'failed')
count += 1if __name__ == '__main__':
spider = SpiderMain()
start_url = 'htidu.com/item/python'
print('crawling')
time_begin = time.time()
spider.crawl(start_url)
time_end = time.time() print('time elapsed:', time_end - time_begin)
2、URL manager
# coding=utf-8class UrlManager():def __init__(self, maxurl=1000):
self.url_new = set() self.url_old = set() self.max_url = maxurl def add_url(self, url):
assert isinstance(url, str) if len(self.url_new) + len(self.url_old) > self.max_url: return
if url not in self.url_new and url not in self.url_old: self.url_new.add(url) def add_urls(self, urls):
if len(self.url_new) + len(self.url_old) > self.max_url: return
for u in urls: self.add_url(u) def get_url(self):
t = self.url_new.pop() self.url_old.add(t) return t def is_has_url(self):
return self.url_new
3、html downloder
# coding=utf-8import requestsclass HtmlDownloader():def download(self, url):
resp = requests.get(url) return resp.content.decode()
4、html parser
# coding=utf-8from bs4 import BeautifulSoupimport reclass HtmlParser():def __init__(self, baikeprefix = 'httidu.com'):
self.baikeprefix = baikeprefix def parse(self, page):
soup = BeautifulSoup(page, 'html.parser')
node = soup.find('h1')
title = node.text
node = soup.find('div', class_='lemma-summary')
summary = node.text
data = title + summary
nodes = soup.findAll('a', href=re.compile(r'/item/'))
urls = set() for i in nodes:
urls.add(self.baikeprefix + i['href']) return data, urls
5、 html outputer
# coding=utf-8class HtmlOutputer():def write2log(self, text, name='d:/baike-oop.log'):
with open(name, 'a+', encoding='utf-8') as fp:
fp.write('\\n')
fp.write(text)
以上是关于如何使用python3爬取1000页百度百科条目的主要内容,如果未能解决你的问题,请参考以下文章