用树莓派3B+实现智能语音识别
Posted So istes immer
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用树莓派3B+实现智能语音识别相关的知识,希望对你有一定的参考价值。
1.前期准备
①在百度智能云平台注册账号并进行身份认证,领取短语音识别的免费资源
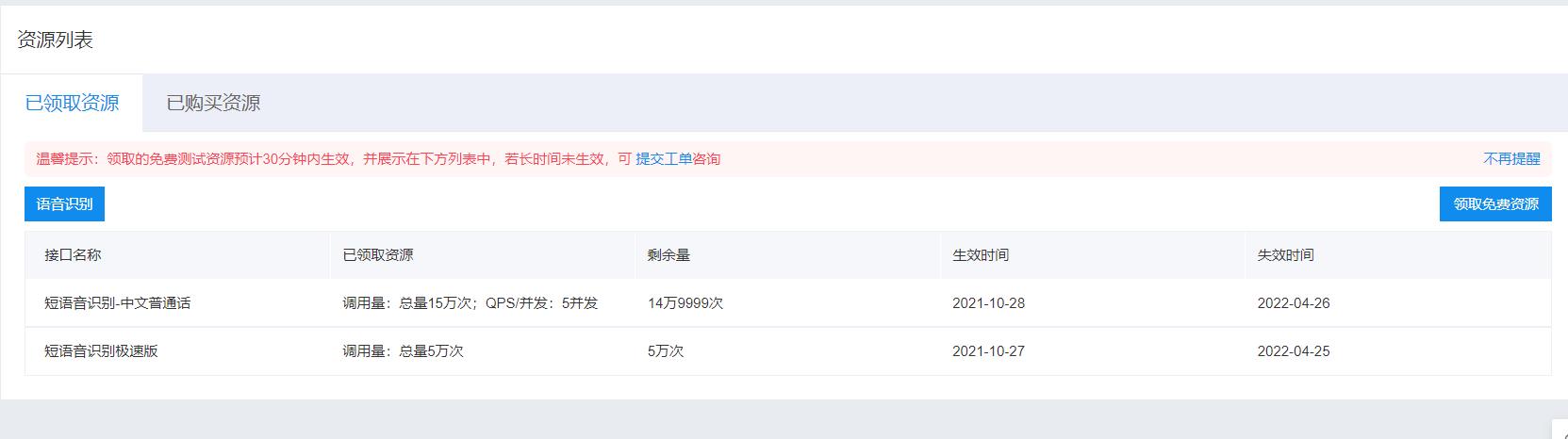
②查看官方文档,我们可以得到一些关键信息(我用的是百度短语音识别标准版-普通话)
百度短语音识别可以将 60 秒以下的音频识别为文字
支持音频格式:pcm、wav、amr、m4a
音频编码要求:采样率 16000、8000,16 bit 位深,单声道
③创建应用,拿到API Key和Secret Key,用于生成Access Token(用户身份验证和授权的凭证)
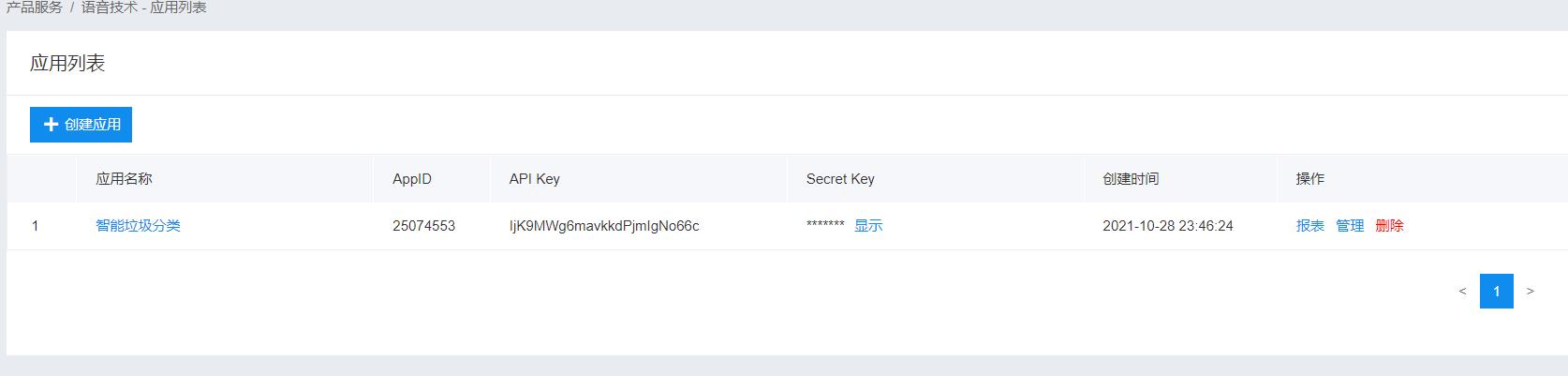
④先拿到官方的demo代码跑起来看看
demo代码地址,github上不了,就去镜像网站看看喽
我这里拿的是python代码,将上面拿到的API Key和Secret Key填到下面代码对应位置即可
我在64位windows操作系统上跑的,python版本是3.8.5
# coding=utf-8
import json
import time
from urllib.request import urlopen
from urllib.request import Request
from urllib.error import URLError
from urllib.parse import urlencode
timer = time.time
API_KEY = 'IjK9MWg6mavkkdPjmIgNo66c'
SECRET_KEY = 'u0aS89j2d9rqNO5GRnUVQ1nhraT4qURQ'
# 需要识别的文件
AUDIO_FILE = './audio/16k.pcm' # 只支持 pcm/wav/amr 格式,极速版额外支持m4a 格式
# 文件格式
FORMAT = AUDIO_FILE[-3:] # 文件后缀只支持 pcm/wav/amr 格式,极速版额外支持m4a 格式
CUID = '123456PYTHON'
# 采样率
RATE = 16000 # 固定值
# 普通版
DEV_PID = 1537 # 1537 表示识别普通话,使用输入法模型。根据文档填写PID,选择语言及识别模型
ASR_URL = 'http://vop.baidu.com/server_api'
SCOPE = 'audio_voice_assistant_get' # 有此scope表示有asr能力,没有请在网页里勾选,非常旧的应用可能没有
# 极速版
class DemoError(Exception):
pass
""" TOKEN start """
TOKEN_URL = 'http://openapi.baidu.com/oauth/2.0/token'
def fetch_token():
params = {'grant_type': 'client_credentials',
'client_id': API_KEY,
'client_secret': SECRET_KEY}
post_data = urlencode(params)
post_data = post_data.encode('utf-8')
req = Request(TOKEN_URL, post_data)
try:
f = urlopen(req)
result_str = f.read()
except URLError as err:
print('token http response http code : ' + str(err.code))
result_str = err.read()
result_str = result_str.decode()
print(result_str)
result = json.loads(result_str)
print(result)
if 'access_token' in result.keys() and 'scope' in result.keys():
if SCOPE and (SCOPE not in result['scope'].split(' ')): # SCOPE = False 忽略检查
raise DemoError('scope is not correct')
print('SUCCESS WITH TOKEN: %s ; EXPIRES IN SECONDS: %s' % (result['access_token'], result['expires_in']))
return result['access_token']
else:
raise DemoError('MAYBE API_KEY or SECRET_KEY not correct: access_token or scope not found in token response')
""" TOKEN end """
if __name__ == '__main__':
token = fetch_token()
speech_data = []
with open(AUDIO_FILE, 'rb') as speech_file:
speech_data = speech_file.read()
length = len(speech_data)
if length == 0:
raise DemoError('file %s length read 0 bytes' % AUDIO_FILE)
params = {'cuid': CUID, 'token': token, 'dev_pid': DEV_PID}
params_query = urlencode(params)
headers = {
'Content-Type': 'audio/' + FORMAT + '; rate=' + str(RATE),
'Content-Length': length
}
url = ASR_URL + "?" + params_query
print("url is", url)
print("header is", headers)
# print post_data
req = Request(ASR_URL + "?" + params_query, speech_data, headers)
try:
begin = timer()
f = urlopen(req)
result_str = f.read()
print("Request time cost %f" % (timer() - begin))
except URLError as err:
print('asr http response http code : ' + str(err.code))
result_str = err.read()
result_str = str(result_str, 'utf-8')
print(result_str)
with open("result.txt", "w") as of:
of.write(result_str)
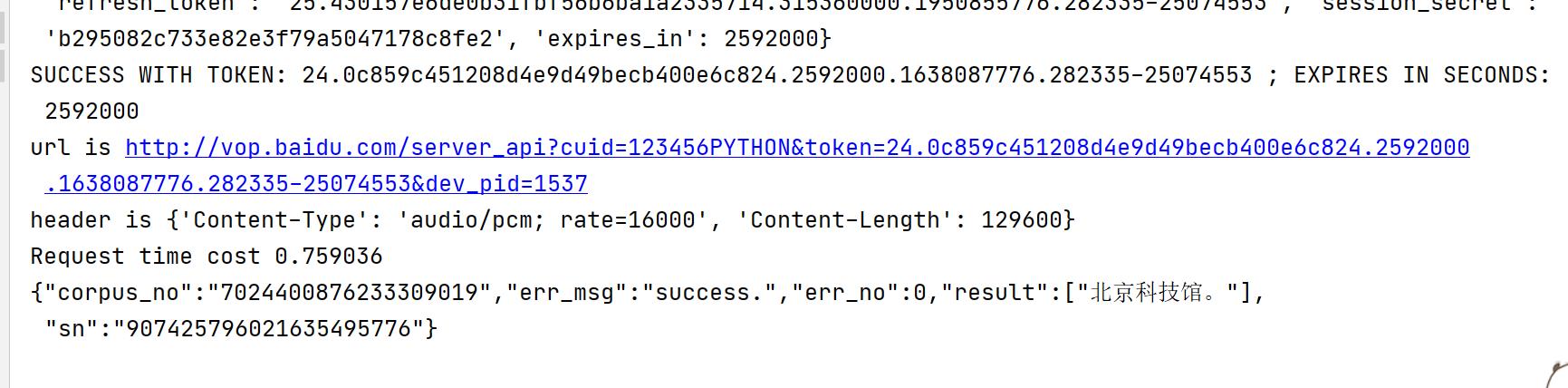
2.在树莓派上实现语言识别功能
以上是关于用树莓派3B+实现智能语音识别的主要内容,如果未能解决你的问题,请参考以下文章