Python爬虫速度很慢?并发编程了解一下吧
Posted Dream丶Killer
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫速度很慢?并发编程了解一下吧相关的知识,希望对你有一定的参考价值。
前言
网络爬虫程序是一种 IO 密集型(页面请求,文件读取)程序,会阻塞程序的运行消耗大量时间,而 Python 提供多种并发编程方式,能够在一定程度上提升 IO 密集型程序的执行效率。再开始之前你要先了解以下概念!
基础知识
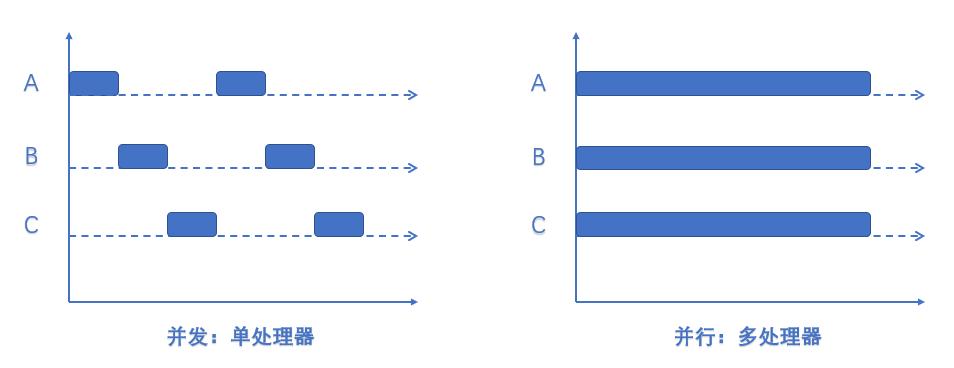
并发:一段时间内发生某些事情。在单核 CPU 中,执行多个任务是以并发的方式运行的,由于只有一个核心处理器,CPU 把一个时间段划分成几个时间区间,各个任务只会在自己的时间区间执行,如果在自己的时间阶段没有完成任务,就会切换到下一个任务,由于各个时间段很短,切换频繁,所以给人的感觉是“同时”运行。
并行:同一时刻进行发生某些事情。在多核 CPU 中,是能够实现真正“同时”运行的,当一个 CPU 执行某个进程时,其他的 CPU 可以执行其他进程,两个进程互不抢占 CPU 资源。
同步:同步中各个任务不是独自运行的,任务之间有交替顺序,只有前一个任务完成后,后面的任务才能够开始运行。
异步:异步中各个任务可以独自运行,任务之间不会互相影响。
在爬虫过程中,异步相当于打开一个网页之后,不需要等待页面加载完成,继续打开新的网页。同步相当于打开一个网页,要等待它完全加载完才打开下一个网页。
提高爬虫速度的三种方式:多线程、多进程、协程。先来了解一下什么是进程,线程,协程?
进程:进程是一个可以独立运行的程序单位。 它是线程的集合,是由一个或多个线程构成的。
线程:是操作系统进行运算调度的最小单位,也是进程中的一个最小运行单元。
协程:协程是比线程更小的执行单元,可以说是一种轻量级的线程,线程的调度是在操作系统中进行的,而协程调度则是在用户空间进行的。它相对于线程的优点是切换成本更低。
GIL
GIL 全称(Global Interpreter Lock,全局解释器锁)在 Python 多线程下,每个线程的执行方式如下:
获取 GIL >>> 执行对应线程的代码 >>> 释放 GIL
一个线程想要执行,先要拿到 GIL,可以把 GIL 看作是许可证,并且在一个 Python 进程中,GIL 只有一个。拿到许可证才能够执行线程,这样就会导致,即使是多核条件下,一个 Python 进程下的多个线程,同一时刻也只能执行一个线程。
对于 IO 密集型(页面请求等) 任务来说,这个问题影响并不大;而对于 CPU密集型 任务来说,由于 GIL 的存在,多线程总体的运行效率相比可能反而比单线程更低。
多线程
多线程的应用场景: I/O 密集型 的程序。如
- 数据库请求
- 页面请求
- 读写文件
由于 GIL 的原因,全局只允许同一时间执行一个线程意味着: 为了保证各个线程都能完成自身的任务,需要频繁的进行 线程切换 操作。
Python 中实现多线程编程需要用到 threading 模块,我们每创建一个 Thread 对象就代表一个线程,每个线程可以去处理不同的任务。
创建 Thread 对象有 2 种方式。
- 将回调函数作为参数,直接创建
Thread对象。 - 从
threading.Thread继承创建一个新的子类,复写run()方法,实例化后调用start()方法启动新线程。
创建Thread 对象
threading.Thread(target=None, name=None, args=(), kwargs=None, *, daemon=None)
- target:指定要被
run()方法调用的可调用对象。默认为None,表示不调用任何函数。 - name:线程名。默认情况下,单一名称以
“Thread-N”的形式构造,其中 N 是十进制数。 - args:目标调用的参数元组(
target的固定参数)。默认为()。 - kwargs:目标调用的关键字参数字典(
target的可变参数)。默认值为None。 - daemon:是否开启守护线程,默认
MainThread(主线程)需要等待其他线程结束后才会结束,默认值为None.
import threading
import time
def block(second):
print(threading.current_thread().name, '线程正在运行')
# 休眠 second 秒
time.sleep(second)
print(threading.current_thread().name, '线程结束')
print(threading.current_thread().name, '线程正在运行')
for i in [1, 3]:
# 创建thread对象并指定回调函数block,name,以及固定参数i
thread = threading.Thread(target=block, name=f'thread test {i}', args=[i])
# 开启线程
thread.start()
print(threading.current_thread().name, '线程结束')

threading.current_thread().name 获取当前线程的名称。先简单说一下上面代码的逻辑,先定义函数 block,输出当前线程信息,循环两次创建 thread 对象,然后开启线程,最后输出线程结束信息。注意各个信息的输出顺序,在 test1、test3 线程结束前主线程就已经结束了。
自定义类继承 Thread
现在直接在上面的例子上进行修改,使用自定义类来继承 Thread 实现多线程。
import threading
import time
class TestThread(threading.Thread):
def __init__(self, name=None, second=0):
threading.Thread.__init__(self, name=name)
self.second = second
def run(self):
print(threading.current_thread().name, '线程正在运行')
time.sleep(self.second)
print(threading.current_thread().name, '线程结束')
print(threading.current_thread().name, '线程正在运行')
for i in [1, 3]:
thread = TestThread(name=f'thread test {i}', second=i)
# 开启线程
thread.start()
print(threading.current_thread().name, '线程结束')

本篇只是简单的开头,后续将持续分享,直至掌握 Python并发爬虫。
对于刚入门 Python 或是想要入门 Python 的小伙伴,可以通过下方小卡片联系作者,一起交流学习,都是从新手走过来的,有时候一个简单的问题卡很久,但可能别人的一点拨就会恍然大悟,由衷的希望大家能够共同进步。
以上是关于Python爬虫速度很慢?并发编程了解一下吧的主要内容,如果未能解决你的问题,请参考以下文章