Kafka的简介
Posted 踩踩踩从踩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka的简介相关的知识,希望对你有一定的参考价值。
前言
本篇文章会介绍Kafka,了解kafka是什么,主要用途是什么,了解kafka的特性,以及kafka集群安装,kafka核心概念、工作原理 ;做一个kafka。
简介

这上面都描述了kafka是一个什么框架;
- 一个分布式的流式数据处理平台。
- 可以用它来发布和订阅流式的记录。这一方面与消息队列或者企业消息系统类似
- 它将流式的数据安全地存储在分布式、有副本备份、容错的集群上
- 可以用来做流式计算
强调一个点是流式的计算,流处理,流存储,都强调一个流。
Kafka® 用于构建实时的数据管道和流式的app.它可以水平扩展,高可用,速度快,并且已经运行在数千家公司的生产环境。
通过消息中间件kafka给我们达到流式计算的场景 。
kafka是为了做了分布式流式安全存储数据的平台,水平的扩展集群,天生就是存储,就算数据消费完了也不会删除。
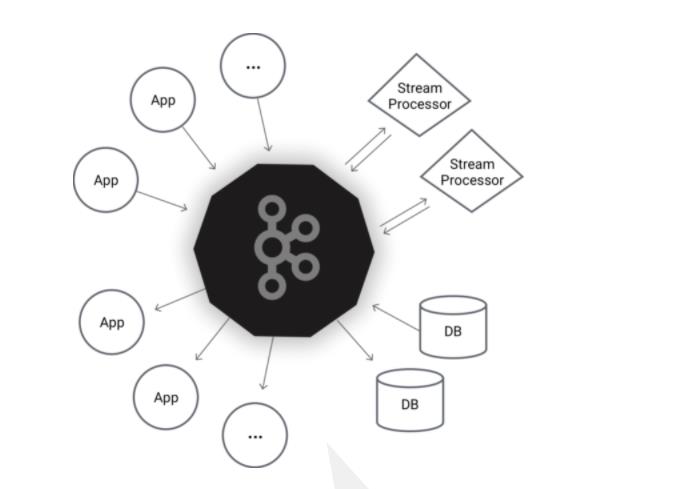
上图体现在kafka集群 可以高可用,达到送数据的效果,以及推送数据的效果。
Kafka® 用于构建实时的数据管道和流式的app.它可以水平扩展,高可用,速度快,并且已经运行在数千家公司的生产环境。
所谓的流式处理,把kafka的数据取过去,有序的处理完了在传送过去,也可以把db里面的数据拿到并处理传送回去。
- 构造实时流数据管道,它可以在系统或应用之间可靠地获取数据。 (相当于message queue)
- 构建实时流式应用程序,对这些流数据进行转换或者影响。 (就是流处理,通过kafka stream topic和topic之间内部进行变化)
kafka体系结构
有五大组件,生产者 、消费者、 流式处理、连接器、消息中间件。
Kafka有四个核心的API:
- The Producer API 允许一个应用程序发布一串流式的数据到一个或者多个Kafka topic。
- The Consumer API 允许一个应用程序订阅一个或多个 topic ,并且对发布给他们的流式数据进行处理。
- The Streams API 允许一个应用程序作为一个流处理器,消费一个或者多个topic产生的输入流,然后生产一个输出流到一个或多个topic中去,在输入输出流中进行有效的转换。
- The Connector API 允许构建并运行可重用的生产者或者消费者,将Kafka topics连接到已存在的应用程序或者数据系统。比如,连接到一个关系型数据库,捕捉表(table)的所有变更内容。
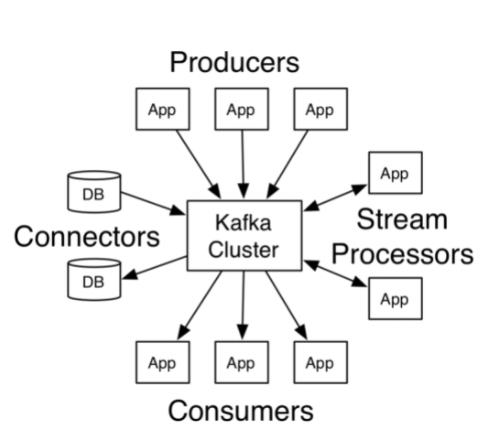
在Kafka中,客户端和服务器使用一个简单、高性能、支持多语言的 TCP 协议.此协议版本化并且向下兼容老版本, 我们为Kafka提供了Java客户端,也支持许多其他语言的客户端。
安装
环境要求
- 生产环境linux
- java1.8 及以上
kafka是scala开发的。但是需要java虚拟机上运行,所以需要java1.8以上
安装
- 下载安装包:https://www.apache.org/dyn/closer.cgi?path=/kafka/2.3.0/kafka_2.12-2.3.0.tgz windows 和 linux都是同一个安装包,window命令在 bin/windows/ 下。
- 安装
[root@node4 ~]# mkdir /usr/kafka
[root@node4 ~]#
[root@node4 ~]# tar -xzf kafka_2.12-2.3.0.tgz -C /usr/kafka/
[root@node4 ~]# ln -s /usr/kafka/kafka_2.12-2.3.0 /usr/kafka/latest- 了解目录结构
[root@node4 ~]# ll /usr/kafka/latest
drwxr-xr-x. 3 root root 4096 6月 20 04:44 bin
drwxr-xr-x. 2 root root 4096 6月 20 04:44 config
drwxr-xr-x. 2 root root 4096 8月 24 17:32 libs
-rw-r--r--. 1 root root 32216 6月 20 04:43 LICENSE
-rw-r--r--. 1 root root 337 6月 20 04:43 NOTICE
drwxr-xr-x. 2 root root 44 6月 20 04:44 site-docs包括下面的 启动程序
kafka安装包全在windows里面的。
配置目录 server.properties 的 kafka配置文件 ,以及zookeeper.properties zk配置文件
在 server.properties配置文件中 包含 节点的唯一编号
服务端口 并可以指定 ip地址, 默认采用主机名。 默认就是9092 ;
以及 advertised.listeners 发布 给 生产者和消费者连接地址 没有配置 这个会发布到zk上去
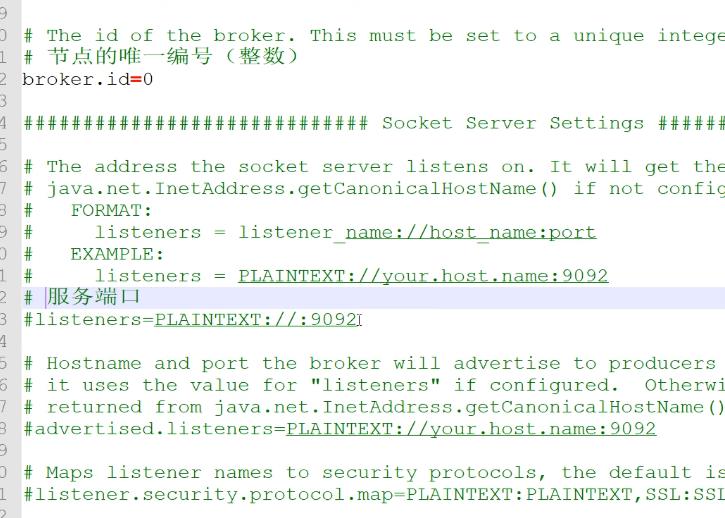

下面其他的 包括数据目录 这里并不是日志目录。 以及主题 元数据存放的zookeeper目录

启动
- 首先要启动zookeeper 。
[root@node4 ~]# cd /usr/kafka/latest/
[root@node4 latest]# bin/zookeeper-server-start.sh config/zookeeper.properties &- 启动Kafka
[root@node4 latest]# bin/kafka-server-start.sh config/server.properties &集群搭建
本身是分布式的
- 拷贝配置文件
[root@node4 latest]# cp config/server.properties config/server-1.properties
[root@node4 latest]# cp config/server.properties config/server-2.properties- 修改配置文件:confifig/server-1.properties:
broker.id=1
listeners=PLAINTEXT://:9093
log.dirs=/var/kafka-logs-1broker.id=2
listeners=PLAINTEXT://:9094
log.dirs=/var/kafka-logs-2- 启动这两个broker实例
[root@node4 latest]# bin/kafka-server-start.sh config/server-1.properties &
[root@node4 latest]# bin/kafka-server-start.sh config/server-2.properties &- 调大你的虚拟机的内存(1G 或更多)
- 调小Kafka的堆大小,默认是1G,生产用时可以调大。可以调为256M(不能太小 了,启动时会heap OOM)
[root@node4 latest]# vi bin/kafka-server-start.sh[root@node4 latest]# bin/kafka-topics.sh --create --bootstrap-server 192.168.100.12:9092 --replication-factor 3 --partitions 1 --topic my-13-topic
[root@node4 latest]#
[root@node4 latest]#
[root@node4 latest]# bin/kafka-topics.sh --describe --bootstrap-server 192.168.100.12:9092 --topic my-13-topic
Topic:my-13-topic PartitionCount:1 ReplicationFactor:3 Configs:segment.bytes=1073741824 Topic: my-13-topic Partition: 0 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1
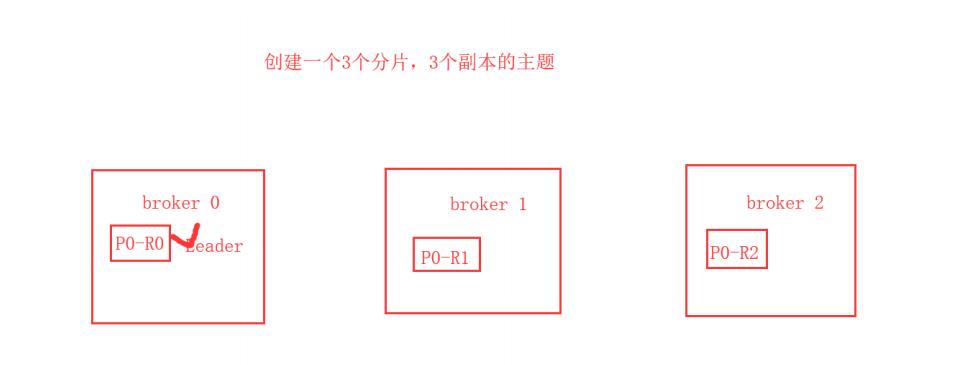
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic my-replicated-topic
监控管理工具
- Kafka集群状态
- Topic、Consumer Group列表
- bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning
- --topic my-replicated-topic图形化展示topic和consumer之间的关系
- 图形化展示consumer的Offffset、Lag等信息
java -cp KafkaOffsetMonitor-assembly-0.2.1.jar \\ com.quantifind.kafka.offsetapp.OffsetGetterWeb \\
--offsetStorage kafka --zk zk-server1,zk-server2 \\
--port 8080 \\
--refresh 10.seconds \\
--retain 2.days0.2.0 版本启动命令
java -cp KafkaOffsetMonitor-assembly-0.2.0.jar \\ com.quantifind.kafka.offsetapp.OffsetGetterWeb \\
--zk zk-server1,zk-server2 \\
--port 8088 \\
--refresh 10.seconds \\
--retain 2.daysspring中使用
SpringforApacheKafka(SpringKafka)项目将核心Spring概念应用于基于Kafka的消息传递解决方案的开发。它提供了一个“模板”,作为发送消息的高级抽象。它还支持带有@KafkaListener注释和“侦听器容器”的消息驱动POJO。
这些库促进了依赖项注入和声明性的使用。在所有这些情况下,您将看到与Spring框架中的JMS支持和Spring AMQP中的RabbitMQ支持的相似之处。
-
KafkaTemplate -
KafkaMessageListenerContainer -
@KafkaListener -
KafkaTransactionManager -
spring-kafka-test
在maven项目中引用
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.8.0-RC1</version>
</dependency>添加配置,包括序列化器

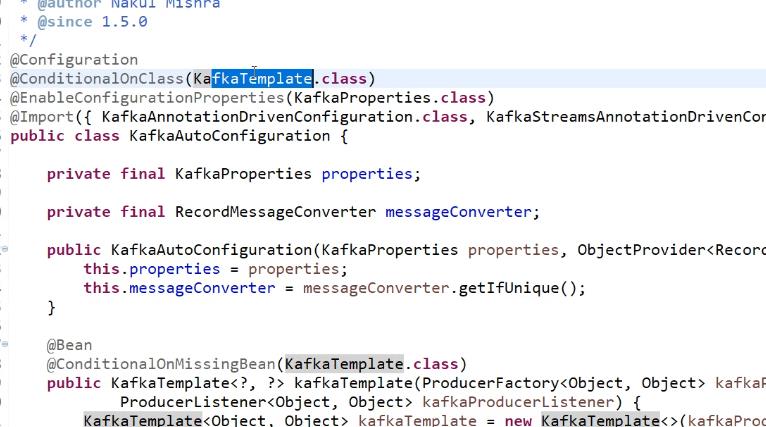
在spring中配置 kafka配置类。包括提前配置好的 一些事务等等。
数据消费 创建主题等。
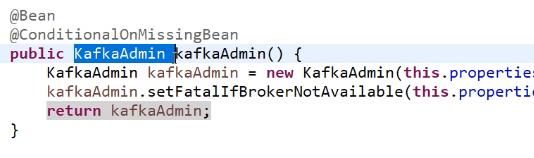
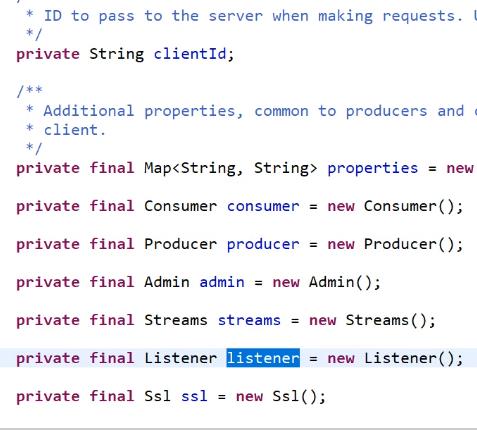
配置一个消费消费消息 重试三次还不成功,将消息发送到死信队列。

public class Sender {
public static void main(String[] args) {
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(Config.class);
context.getBean(Sender.class).send("test", 42);
}
private final KafkaTemplate<Integer, String> template;
public Sender(KafkaTemplate<Integer, String> template) {
this.template = template;
}
public void send(String toSend, int key) {
this.template.send("topic1", key, toSend);
}
}
public class Listener {
@KafkaListener(id = "listen1", topics = "topic1")
public void listen1(String in) {
System.out.println(in);
}
}
@Configuration
@EnableKafka
public class Config {
@Bean
ConcurrentKafkaListenerContainerFactory<Integer, String>
kafkaListenerContainerFactory(ConsumerFactory<Integer, String> consumerFactory) {
ConcurrentKafkaListenerContainerFactory<Integer, String> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory);
return factory;
}
@Bean
public ConsumerFactory<Integer, String> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerProps());
}
private Map<String, Object> consumerProps() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "group");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, IntegerDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// ...
return props;
}
@Bean
public Sender sender(KafkaTemplate<Integer, String> template) {
return new Sender(template);
}
@Bean
public Listener listener() {
return new Listener();
}
@Bean
public ProducerFactory<Integer, String> producerFactory() {
return new DefaultKafkaProducerFactory<>(senderProps());
}
private Map<String, Object> senderProps() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ProducerConfig.LINGER_MS_CONFIG, 10);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, IntegerSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
//...
return props;
}
@Bean
public KafkaTemplate<Integer, String> kafkaTemplate(ProducerFactory<Integer, String> producerFactory) {
return new KafkaTemplate<Integer, String>(producerFactory);
}
}监控数据都是 使用KafkaListener 注解 监听收到消息
@KafkaListener(id = "multiGroup", topics = { "foos", "bars" })在运行的时候

通过spring的思想,都是配置得到。
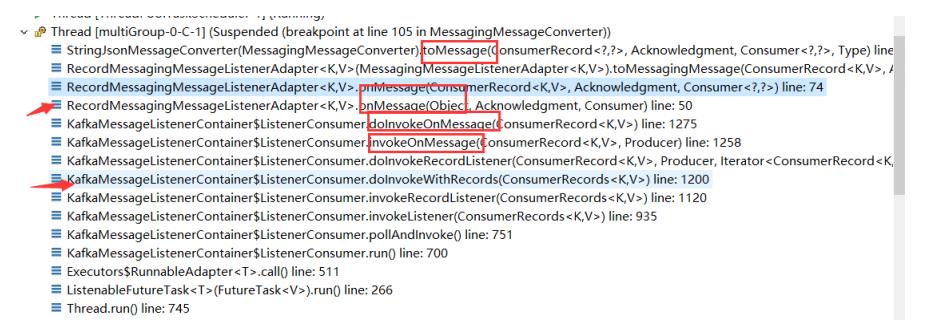
MessageConverter的调用
以上是关于Kafka的简介的主要内容,如果未能解决你的问题,请参考以下文章