Kafka核心概念详解二
Posted 踩踩踩从踩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka核心概念详解二相关的知识,希望对你有一定的参考价值。
前言
本篇文章承接上篇文章的核心概念topic、kafka的集群分片、持久化消息存储机制,leader选举机制;本篇文章继续解析topic ,消息存储机制、以及produce生产者、消费者 Consumer、及事务模式的原理详解
消息存储机制
消息序号

消费者的offset, 序号偏移量,每一个消费者进行消费的时候,都有个序号,和偏移量。并不需要消息确认,因为有个序号,判断消费者访问到哪里了。
TimeIndex 时间索引
- 消息要有时间戳
-
建立时间索引 .timeindex 数据结构 { 时间戳,序号 }

可以根据 配置创建时间 还是 日志写入时间,默认是消息创建时间

在消费者中怎么找到分片的偏移量,通过下面的方法。

返回的 得到分片,以及分片的起始号 最后就可以根据这个能拿到消费的服务

Topic的配置参数
官方文档 参数配置: Apache Kafka
参数修改
> bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic my-topic
-- partitions 1 --replication-factor 1 --config max.message.bytes=64000 --config flush.messages=1也可以在使用alter confifigs命令稍后更改或设置覆盖值. 本示例重置my-topic
> bin/kafka-configs.sh --zookeeper localhost:2181 --entity-type topics
--entity- name my-topic --alter --add-config max.message.bytes=128000bin/kafka-configs.sh --zookeeper localhost:2181 --entity-type topics --entity- name my-topic --describe> bin/kafka-configs.sh --zookeeper localhost:2181 --entity-type topics
-- entity-name my-topic --alter --delete-config max.message.bytes删除Topic
[root@node4 latest]# bin/kafka-topics.sh --create --bootstrap-server
localhost:9092 --replication-factor 1 --partitions 1 --topic test-1# 发送一下消息 [root@node4 latest]# bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test-1[root@node4 latest]# bin/kafka-topics.sh --delete --bootstrap-server
localhost:9092 --topic test-1drwxr-xr-x. 2 root root 141 8月 26 20:49 test-1- 0.20bb2388c6f04c34b79419411bc1bda6-deleteProducer
public static void main(String[] args) throws Exception {
// Producer的配置参数含义说明:http://kafka.apachecn.org/documentation.html#configuration
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.120.41:9092");
// 客户端标识,让Broker可以更好地区分客户端,非必需。
props.put(CommonClientConfigs.CLIENT_ID_CONFIG, "client-1");
// broker回复发布确认的方式
props.put("acks", "all");
// 当发送失败时重试几次
props.put("retries", 0);
// Producer是采用批量的方式来提高发送的吞吐量量的,这里指定批大小,单位字节
props.put("batch.size", 16384);
// 批量发送的等待时长(即有一条数据后等待多长时间接受其他要发送的数据组成一批发送),这个是对上面大小的补充。
props.put("linger.ms", 1);
// 存放数据的buffer的大小
props.put("buffer.memory", 33554432);
// key的序列化器
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 消息数据的序列化器
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
try (Producer<String, String> producer = new KafkaProducer<>(props);) {
for (int i = 0; i < 100; i++) {
String message = "message-" + i;
// producer采用异步批量的方式来发送消息,send方法会立即返回。
Future<RecordMetadata> resultFuture = producer.send(new ProducerRecord<String, String>("test", Integer.toString(i), message));
// 如果你想要同步阻塞等待结果
RecordMetadata rm = resultFuture.get();
System.out.println("发送:" + message + " hasOffset: " + rm.hasOffset() + " partition: " + rm.partition() + " offset: " + rm.offset());
TimeUnit.SECONDS.sleep(1L);
}
}
}生产者消息发布确认机制
// broker回复发布确认的方式
props.put("acks", "all");在produceconfig中有配置参数的含义。

- 0: producer不会等待broker发送ack
- 1: 当leader接收到消息之后发送ack
- all:leader接收到消息后,等待所有in-sync的副本同步完成之后 发送ack。这样可以提供最好的 可靠性。This means the leader will wait for the full set of in-sync replicas to acknowledge the record. This guarantees that the record will not be lost as long as at least one in-sync replica remains alive. This is the strongest available guarantee. This is equivalent to the acks=-1 setting.
- -1: 等价于 all
Callback异步处理的确认结果
异步的方式获得确认结果。


在RecordMetadata 中是没有我们需要消息数据的。属性能看出来

需要做记录的关联才知道数据是那条消息。
想要知道异常 ,包括什么超时异常, 找不到server异常等等。

在spring中使用
发送消息 直接使用 Kafkatemple ,也是通过
/*** Set a {@link ProducerListener} which will be invoked when Kafka acknowledges
* a send operation. By default a {@link LoggingProducerListener} is configured
* which logs errors only.
* @param producerListener the listener; may be {@code null}.
*/
public void setProducerListener(@Nullable ProducerListener<K, V> producerListener) {
this.producerListener = producerListener;
}可以将对应的记录等给我们

ProducerInterceptor拦截器
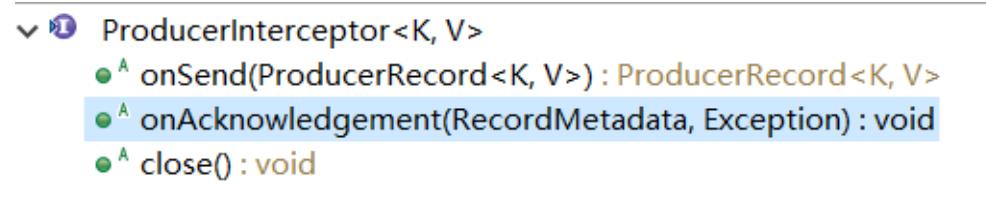
拦截的顺序这个没有什么优先级什么的,只有设置添加的顺序
使用方式
通过interceptor.classes指定实现类名:
//配置 ProducerInterceptor
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, "com.study.xxx.MyProducerInterceptor1,com.study.xxx.MyProducerInterceptor2");幂等模式
也就是消息如何只发送一次, 防止重复发送消息
事务模式
- 要使用事务模式和对应的api,必须设置 transactional.id 属性。 transactional.id 配置 后,将自动启用幂等性,同时启用幂等性所依赖的生成器配置。transactional.id 是事务标识,用于跨单个生产者实例的多个会话启用事务恢复。对于分区应用程序中运行的每个生成器实例,它应该是惟一的。
- Kafka集群需要有至少3个节点
- 为了从端到端实现事务保证,还必须将消费者配置为只读取提交的消息。

配置 隔离级别的,包括读提交等。
Consumer
消费者,Kafka中消费者是采用 poll 拉模式来获取消息,数据不删除是会一直存在的。
public static void main(String[] args) {
// 消费者参数详见:http://kafka.apachecn.org/documentation.html#newconsumerconfigs
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put(CommonClientConfigs.CLIENT_ID_CONFIG, "client-1");
// 设置消费组
props.put("group.id", "test");
// 开启自动消费offset提交
// 如果此值设置为true,consumer会周期性的把当前消费的offset值保存到zookeeper。当consumer失败重启之后将会使用此值作为新开始消费的值。
props.put("enable.auto.commit", "true");
// 自动消费offset提交的间隔时间
props.put("auto.commit.interval.ms", "1000");
// key 的反序列化器
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// 消息的反序列化器
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
String topic = "test";
try (KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);) {
// 订阅topics
consumer.subscribe(Arrays.asList(topic));
while (true) {
// kafka中是拉模式,poll的时间参数是告诉Kafka:如果当前没有数据,等待多久再响应
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1L));
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
// 设定从哪里开始拉取消息 (需要时设置)
// consumer.seek(new TopicPartition(topic, 0), 0);
}
}
}Consumer是非线程安全的。 多线程中的情况下,一个线程一个Consumer。
消费组
消费组的概念,为什么要这个概念,达到消费负载均衡的概念。
- 消费者使用一个 消费组 名称来进行标识,发布到topic中的每条记录被分配给订阅消费组中的一个消费者实例.消费者实例可以分布在多个进程中或者多个机器上。
- 如果所有的消费者实例在同一消费组中,消息记录会负载平衡到每一个消费者实例.
- 如果所有的消费者实例在不同的消费组中,每条消息记录会广播到所有的消费者进程.

- 通常情况下,每个 topic 都会有一些消费组,一个消费组对应一个"逻辑订阅者"。一个消费组由许多消 费者实例组成,便于扩展和容错。这就是发布和订阅的概念,只不过订阅者是一组消费者而不是单个的 进程。
- 在Kafka中实现消费的方式是将日志中的分片划分到每一个消费者实例上,以便在任何时间,每个实例都是分片唯一的消费者。维护消费组中的消费关系由Kafka协议动态处理。如果新的实例加入组,他们将从组中其他成员处接管一些 partition 分区;如果一个实例消失,拥有的分区将被分发到剩余的实例。
- Kafka 只保证分区内的记录是有序的,而不保证主题中不同分区的顺序。如果你希望所有消息都有序消费,可使用仅有一个分区的主题来实现,这意味着每个消费者组只有一个消费者进程。
group rebalance
这里组重平衡,消费组的重平衡延时参数设置

触发重平衡的事件:
- 消费者数量变化
- 分片的增减
都会导致这个重平衡开始,重平衡产生的原因都是这个原因。
在spring中如何指定消费组id
直接就是我们设置的默认id,也就是消费组id.
Kafka怎么知道消费者离线了,需要rebalance了?
也是来源于心跳和session的。
Beatheart Session
心跳和session heartbeat.interval.ms ,session.timeout.ms ,max.poll.interval.ms
这里都有默认值的。 有心跳去监听的。 会话超时的时间,都会使得消费者状态的更新

消费offffset
在中没有初始偏移时该怎么办ZooKeeper或如果偏移量超出范围;
- smallest:自动将偏移重置为最小偏移;
- largest:自动将偏移重置为最大
- offffset:向消费者抛出异常
//设置创建的消费者从何处开始消费消息
props.put("auto.offset.reset", "smallest");自动提交 手动提交
自动提交
// 开启自动消费offset提交
// 如果此值设置为true,consumer会周期性的把当前消费的offset值保存到zookeeper。当 consumer失败重启之后将会使用此值作为新开始消费的值。 props.put("enable.auto.commit", "true");
// 自动消费offset提交的间隔时间
props.put("auto.commit.interval.ms", "1000");- 重复消费
- 丢数据(丢消息)
这是自动提交会产生的问题,只有判断 ,重新在拉。
手动提交
使用代码
//设置手动提交 props.put("enable.auto.commit", "false");
...
//手动同步提交消费者offset到zookeeper
consumer.commitSync();这里抛异常的时候可以捕获异常的。


Consumer 的提交方法

灵活按分片提交消费offffset值

控制消费的位置
- 消费者程序在某个时刻停止了运行,重启后继续消费从那个时刻以来的消息。从某个时间指定消费者的位置
- 消费者在本地可能存储了消费的消息,但这份本地存储坏了,想重新取一份到本地。重新拉取
String topic = "foo";
TopicPartition partition0 = new TopicPartition(topic, 0);
TopicPartition partition1 = new TopicPartition(topic, 1); consumer.assign(Arrays.asList(partition0, partition1));

根据某一个时刻去获取数据

subscribe vs assign
订阅 和指派 这两个在使用上的区别
- subscribe :该消费者消费的是哪些分片是由Kafka根据消费组动态指定,并可以动态rebalance
- assign :则是由用户指定要消费哪些分片,不受rebalance影响
// 不是订阅Topic
// consumer.subscribe(Arrays.asList("test", "test-group"));
// 而是直接分配该消费者读取某些分片 subscribe 和 assign 只能用其一,assign 时不受 rebalance影响。
TopicPartition partition = new TopicPartition("test", 0);
consumer.assign(Arrays.asList(partition));可以通过 consumerRebalanceListener 去感知平衡。

poll设置
拉取数据的时候,一次拉取,返回多少数据?
这是返回所有数据,还是一部分数据,这个都可以设置的。
- fetch.min.bytes 服务器应为获取请求返回的最小数据量。如果没有足够的可用数据,请求将在响应请求之前等待积累足够的数据。默认设置为1字节意味着获取只要有一个字节的数据可用,或者提取请求在等待数据到达时超时,请求就会得到响应。将该值设置为大于1的值将导致服务器等待更大数量的数据累积,这可以同时稍微提高服务器吞吐量额外延迟的成本。
-
max.partition.fetch.bytes 服务器将返回的每个分区的最大数据量。记录由使用者分批获取。如果获取的第一个非空分区中的第一个记录批大于此限制,则仍将返回该批,以确保使用者能够取得进展。代理接受的最大记录批量大小通过message.max.bytes(代理)定义配置)或max.message.bytes(主题配置)。有关限制使用者请求大小的信息,请参阅fetch.max.bytes。
-
fetch.max.byte 服务器应为获取请求返回的最大数据量。记录由使用者分批获取,如果第一批记录位于获取的第一个非空分区中大于此值时,仍将返回记录批,以确保使用者能够取得进展。因此,这不是一个绝对最大值。代理接受的最大记录批量大小是通过message.max.bytes(代理配置)或max.message.bytes(主题配置)定义的。请注意使用者并行执行多个回迁。
- max.poll.records 对poll()的单个调用中返回的最大记录数。
这里都可以在官网中可以看到参数配置。
通过这个参数控制到防止重复一直取某个分片的值。
消费的流速控制 Flow Control
- 在流式处理中,程序要对两个Topic中的流数据执行join操作,而一个Topic的生产速度快与另一个,此时就需要降低快的topic的消费速度来匹配慢的。
- 另一个场景:启动消费者时,已经有大量消息堆积在这些指定的Topic中,程序需要优先处理包含最新数据的topic,再处理老旧数据的topic。
- pause(Collection partitions) 暂停一个子集的拉取
- resume(Collection partitions) 恢复子集的拉取
事务

Spring 中API
- @KafkaListener
- @TopicPartition
- @PartitionOffffset
- KafkaListenerErrorHandler

以上是关于Kafka核心概念详解二的主要内容,如果未能解决你的问题,请参考以下文章