高可用 hadoop HA 搭建教程
Posted 啊陈姐啊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了高可用 hadoop HA 搭建教程相关的知识,希望对你有一定的参考价值。
高可用 hadoop HA 搭建教程
1、基础环境配置
基础环境配置
2、文件配置
配置java路径和hadoop_conf_dir
(1)hadoop.env.sh:
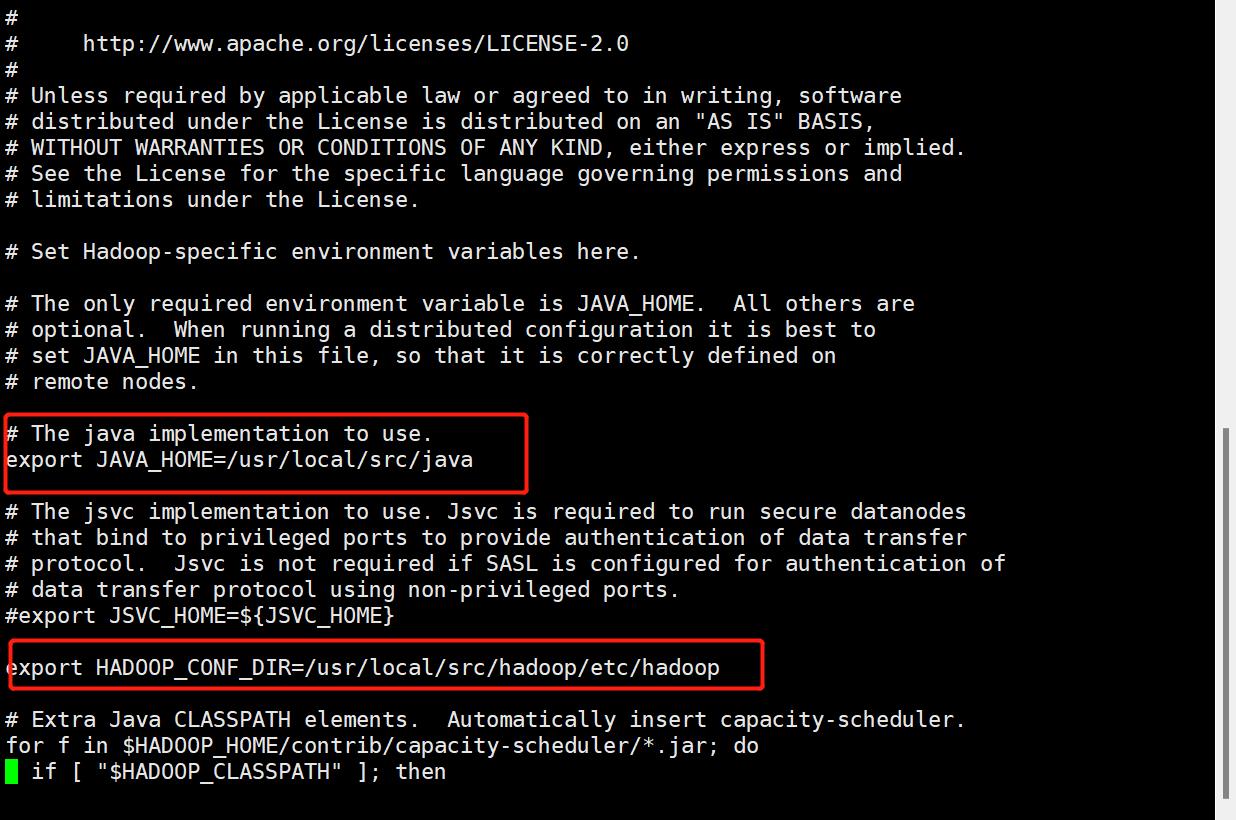
=========================================================
(2)mapred-env.sh
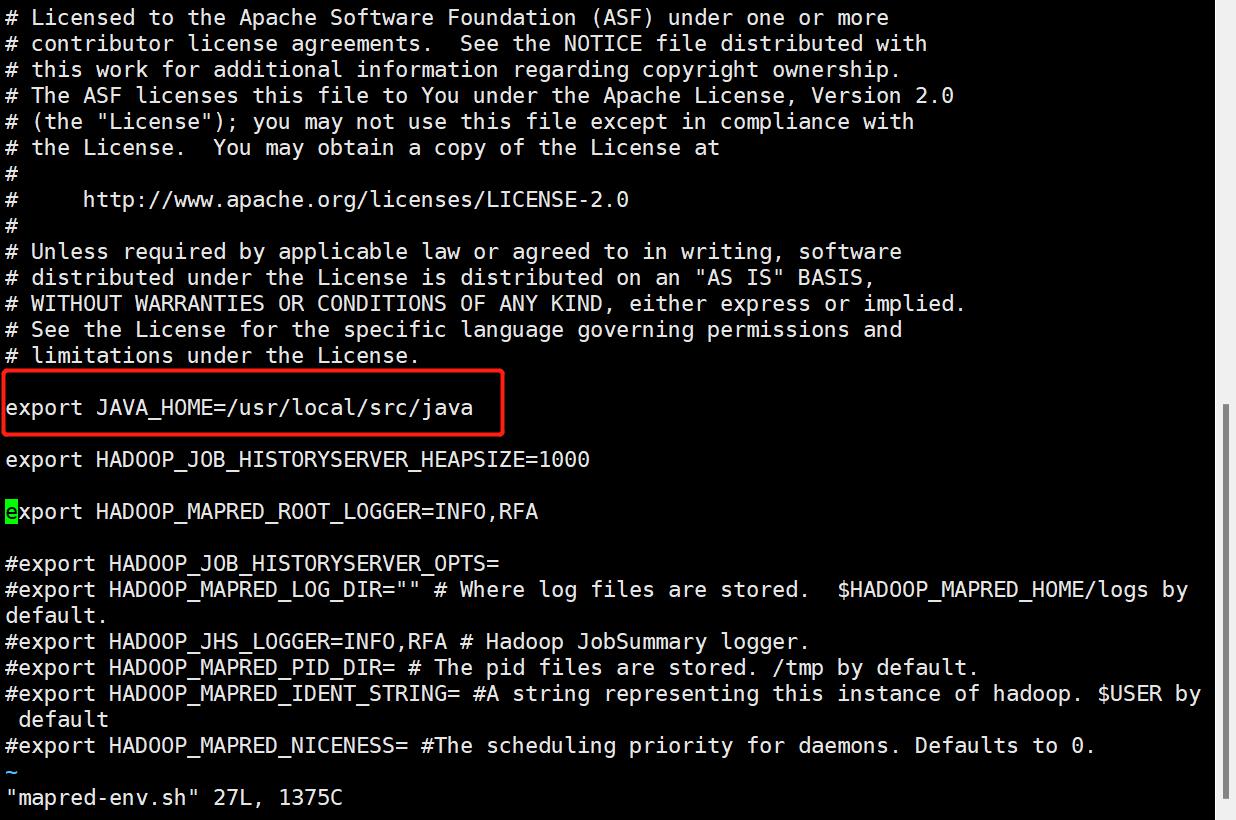
=========================================================
(3)yarn-env.sh
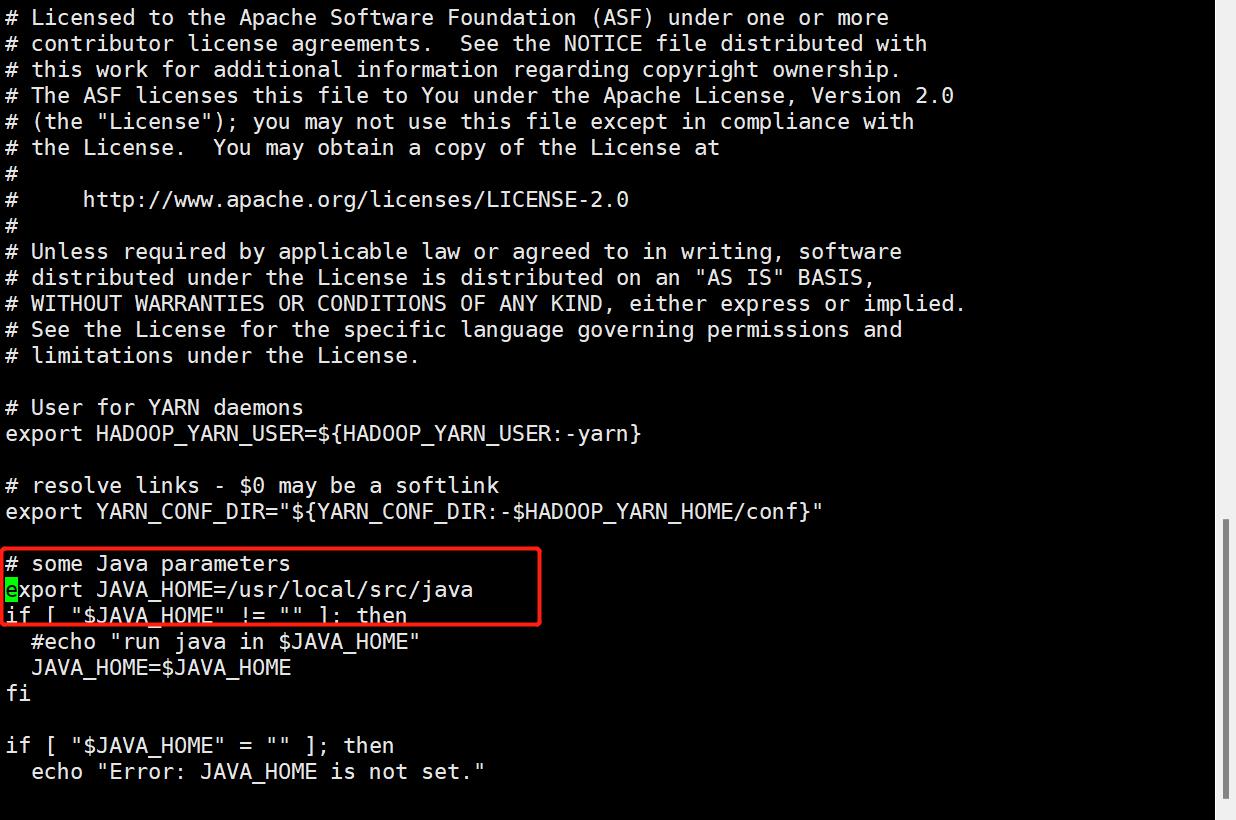
=========================================================
(4)core-site.xml
<!-- 指定zookeeper的存放地址-->
<property>
<name>ha.zookeeper.quorum</name>
<value>192.168.120.150:2181,192.168.120.151:2181,192.168.120.152:2181</value>
</property>
<!-- 指定hadoop集群在zookeeper上注册的节点名-->
<property>
<name>fs.defauFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 用来指定hadoop运行时产生的存放目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop01/tmp</value>
</property>
<!--设置缓存大小,默认4kb-->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
=========================================================
(5)hdfs-site.xml
<!--数据块默认大小128m-->
<property>
<name>dfs.block.size</name>
<value>134217728</value>
</property>
<!--副本数量,不配置默认为3-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--namenode 数据存放位置-->
<property>
<name>dfs.name.dir</name>
<value>/hadoop01/namenode_data</value>
</property>
<!--datanode 数据存放位置-->
<property>
<name>dfs.data.dir</name>
<value>/hadoop01/datanode_data</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>192.168.120.150:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>192.168.120.150:50070</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>192.168.120.151:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>192.168.120.151:50070</value>
</property>
<!-- 指定namenode的元数据在Journalnode上的存放数据-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://192.168.120.150:8485;192.168.120.151:8485;192.168.120.152:8485/mycluster</value>
</property>
<!-- 指定Journalnode本地磁盘的存放数据位置-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/hadoop01/journalnode</value>
</property>
<!-- 开启namenode故障转移自动切换-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--配置失败自动切换实现方式-->
<property>
<name>dfs.client.filover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--hdfs文件操作权限,false为不验证-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<!--配置隔离机制-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!--使用隔离机制需要ssh免密登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
=========================================================
(6)mapred-site.xml
<!--指定mapreduce运行在yarn上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--配置任务历史服务器地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.120.150:10020</value>
</property>
<!--配置任务历史服务器web-ui地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.120.150:19888</value>
</property>
<!--开启uber模式-->
<property>
<name>mapreduce.job.ubertark.enabled</name>
<value>true</value>
</property>
=========================================================
(7)yarn-site.xml
<!--开启yarn高可用-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--指定yarn集群在zookeeper上注册的节点名-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>hayarn</value>
</property>
<!--指定俩个ResourceManager的名称-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!--指定rm1的主机 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>192.168.120.151</value>
</property>
<!-- 指定rm2的主机-->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>192.168.120.152</value>
</property>
<!-- 开始yarn恢复机制-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 配置zookeeper的地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>192.168.120.150:2181,192.168.120.151:2181,192.168.120.152:2181</value>
</property>
<!-- nodemanager获取数据的方法方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 配置执行ResourceManager恢复机制实现类-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- 指定主resourcemanager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.120.152</value>
</property>
=========================================================
3、 解释说明
前提必须要有zookeeper
hadoop2.6.0
zookeeper3.4.5
192.168.120.150 ===> master 或者 hadoop(文章里面可能带有相关字眼)
192.168.120.151 ===> slave1
192.168.120.152 ===> slave2
4、相关命令:
启动zookeeper(初始化工作)
zkServer.sh start 三台机子都要启动
zkServer.sh status 查看zk状态
hadoop-daemon.sh start journalnode 启动journalnode,三台都要使用
hdfs namenode -format 格式化(仅master)
hdfs namenode -bootstrapStandby 同步namenode数据,slave1使用
或者把
hadoop01目录下的namenode_data发送到slave1
scp /hadoop01/namenode_data slave1:/hadoop/namenode_data
hdfs zkfc -formatZK 复制Namenode节点后(在master或者slave1)格式化zkfc
start-dfs.sh 在master中启动hdfs相关服务
start-yarn.sh 在slave2上启动yarn相关服务
启动master的历史任务服务器
mr-jobhistory-daemon.sh start historyserver
启动slave1中的ResourceManager
yarn-daemon.sh start resourcemanager
jps查看端口号,把active的kill
kill -9 端口号
登录web-ui,查看
hdfs haadmin -getServiceState nn1 查看状态
yarn rmadmin -getServiceState rm1 查看状态
启动完成后会看到
master:
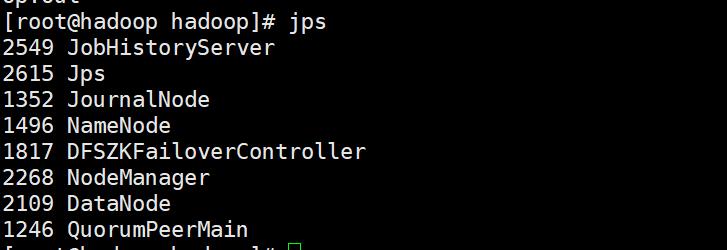
slave1:
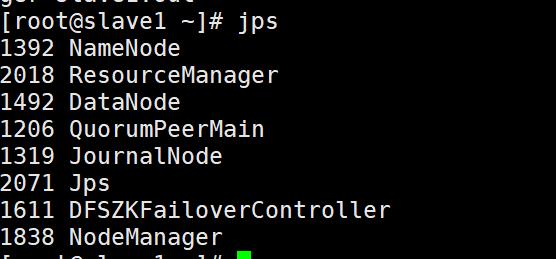
slave2:
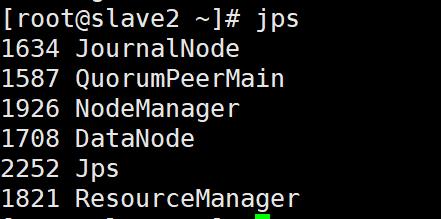
看一下namenode状态

看一下datanode状态

5、资源
链接:https://pan.baidu.com/s/1ffrub7pu_zc1SYX-6yBE_w
点击跳转
提取码:6666
以上是关于高可用 hadoop HA 搭建教程的主要内容,如果未能解决你的问题,请参考以下文章