基于人体骨架序列的单步动作时序定位策略(原创)
Posted 诸葛弩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于人体骨架序列的单步动作时序定位策略(原创)相关的知识,希望对你有一定的参考价值。
13个月,终于见刊,经历了大修后再大修,然后编后重投。好在重投后主编效率高,估计是看我也不容易……

这张图是算法思路,关键在于通过SPP改造了经典的卷积神经网络,使之能够接受任意时长的动作序列。在训练过程中,将数据集中的样本归一化到多个不同的时间尺寸,是神经网络能够学习到多尺度特征。然后,在预测过程中,直接输入不经“缩放和裁剪”的信息,提高动作的识别准确率。再结合之前发的文章当中的数据增强策略,效果奇好。实验图为证:
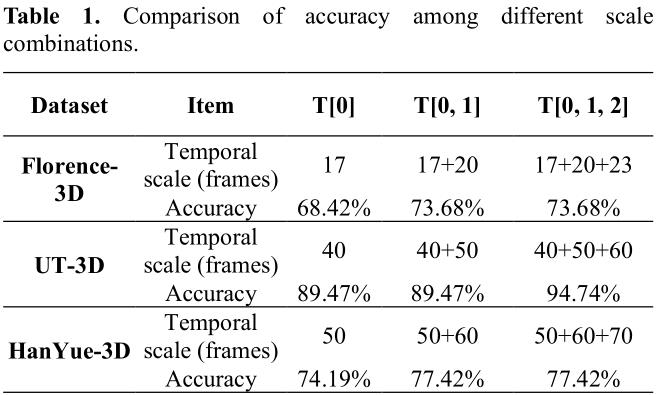
上图是没有加数据增强策略前的效果,加上数据增强后,在改进的ZF-NET上,效果又更进了一步:

动作能够准确识别后,就是做时序定位的活了,下图算法感觉自己有点创新。

这是基于中文分词中“长词逆序”思路改进而来的算法,我取名为:基于大尺度时间窗口优先的探进定位策略。具体思路为:
先将一个可能包含所有动作的窗口作为探测基准,一旦predict出来的概率超过一定阈值,则认定这一段是一个动作。如果预测出来的概率小于阈值,则对当前窗口进行拆分,并结合上一次的探测结果进行判断。这个有点受启发于毛毛虫走路,一开始是最大可能的跨一步,但如果碰到火或其他刺激性的阻碍,就缩回来,尝试着小小走一步,过了阻碍,再一大步,如此循环……这样做的好处是不需要在视频的时间纬度进行锚点和窗口的proposal,一个视频的检测从头到尾一次可过。
在算法思考过程中发现:动作在连续行为中的时序定位和中文分词有很多的共同之处。首先,一段中文的长文中包含有许多中文的单词,而一段复杂行为视频中包含有许多基本动作;其次,中文单词在句子中没有明确的边界,而一段复杂行为视频中每个动作也没有明确的边界;最后,不同中文单词按照顺序组成了语义相异的句子,不同的基本动作按照时序的不同排列组成了不同的复杂行为。鉴于上述三点,“长词逆序优先分词策略”对动作在复杂行为中的时序定位研究,就具备了非常有价值的参考意义。再结合我称之为“探进”的策略,很好地实现了动作的时序定位,特别是持续时间较短的“微小”动作在连续行为视频中的识别。放一张极具说服力的实验结果:
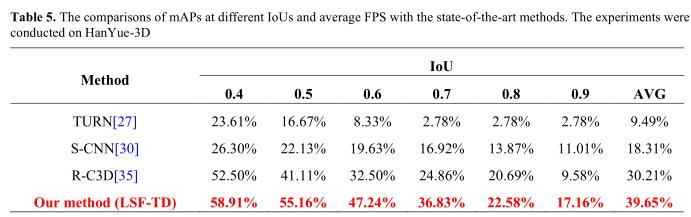
map@IOU=0.5能够在55%左右,估计是state-of-the-art了,其实用多尺度窗口的话会更好,不过实验数据集是自己收集的(没有多少时序定位是做小动作且基于骨架的,只有自己创建了个数据集,哎……公信力不够,不然可以投更好的刊物了)
这篇文章的最大贡献点:
1、提出了一种探进的时序定位算法,无需遍历视频。大大提高了时序定位的效率;
2、收集了一个基于人体骨架序列的数据集,小型,但具备代表性。应该是目前唯一一个既包含动作样本,又包含复杂行为样本的数据集了。数据集下载地址:http://121.43.57.87:7777/HanYue-Action3D.html
如有帮助,请各位大大写论文的时候引用一下本文:
Yao L, Yang W, Huang W, Jiang N, Zhou B. Multi‐scale feature learning and temporal probing strategy for one‐stage temporal action localization. International Journal of Intelligent Systems. 2021;1‐21. https://doi.org/10.1002/int.22713
以上是关于基于人体骨架序列的单步动作时序定位策略(原创)的主要内容,如果未能解决你的问题,请参考以下文章