学习笔记Kafka—— Kafka 与Spark集成 —— 原理介绍与开发环境配置实战
Posted 别呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学习笔记Kafka—— Kafka 与Spark集成 —— 原理介绍与开发环境配置实战相关的知识,希望对你有一定的参考价值。
一、环境
1.1、Hadoop环境

1.2、Spark环境
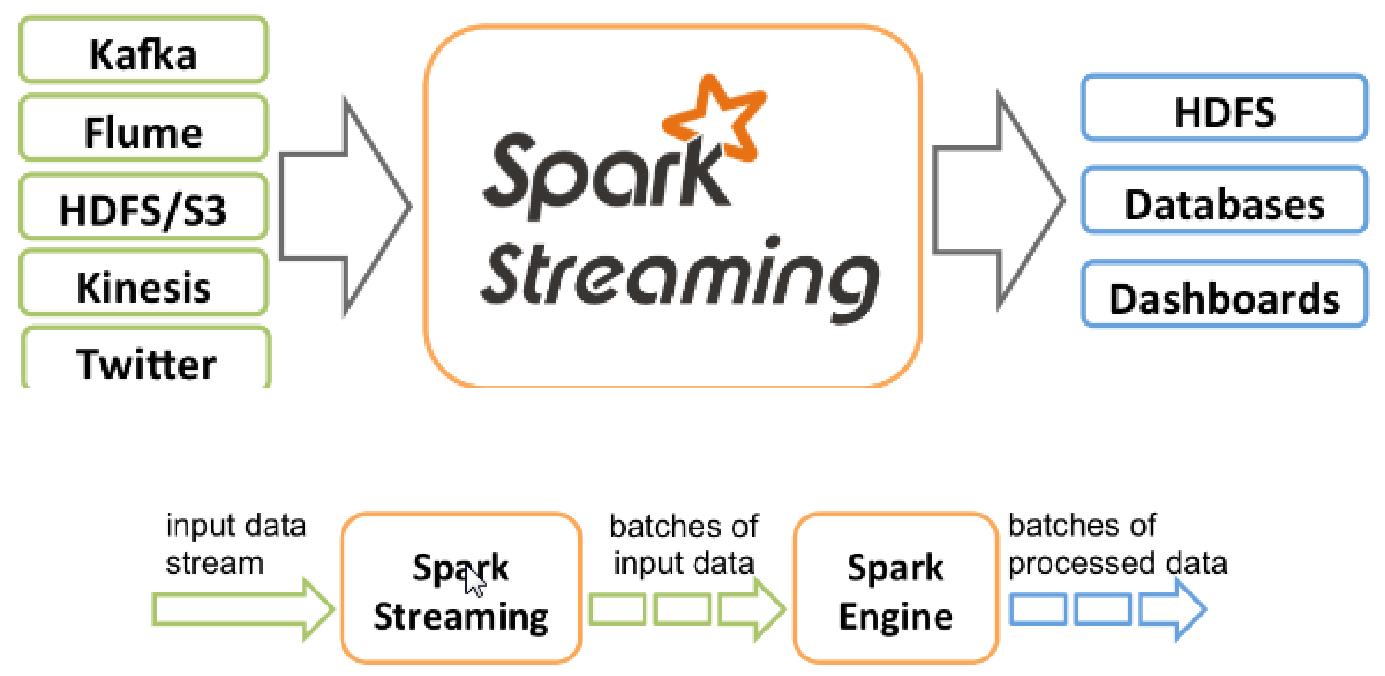
1.3、Spark Streaming

1.4、Add Maven Dependencies & 开发流程
Add Scala Framework Support
添加依赖(在pom.xml添加)
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.4.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-8_2.11</artifactId>
<version>2.4.3</version>
</dependency>
开发流程

二、实战
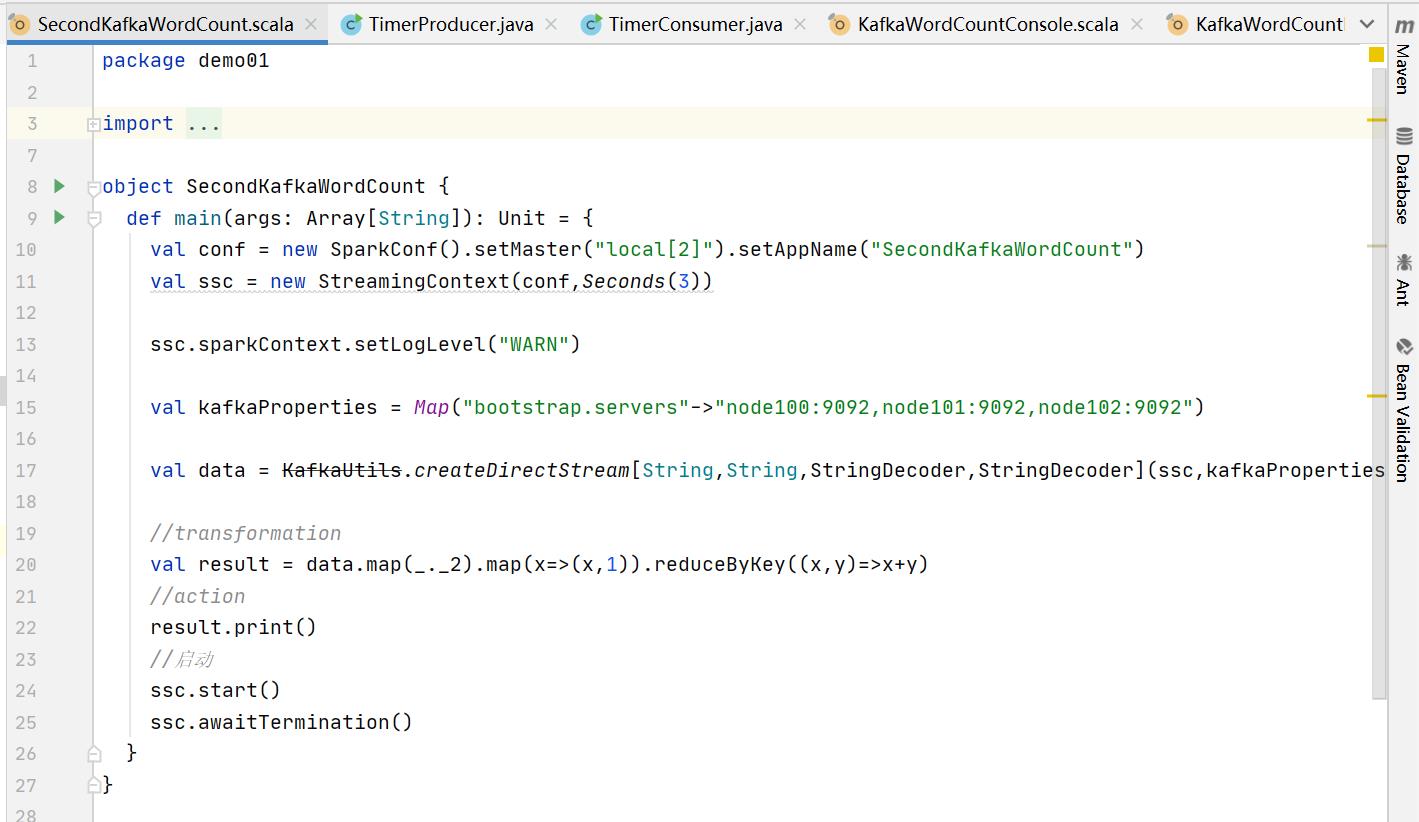
实战一:Kafka消息输出到Console|本地测试|集群测试
package demo01
import kafka.serializer.StringDecoder
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SecondKafkaWordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("SecondKafkaWordCount")
val ssc = new StreamingContext(conf,Seconds(3))
ssc.sparkContext.setLogLevel("WARN")
val kafkaProperties = Map("bootstrap.servers"->"node100:9092,node101:9092,node102:9092")
val data = KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder](ssc,kafkaProperties,Set("test_02_02"))
//transformation
val result = data.map(_._2).map(x=>(x,1)).reduceByKey((x,y)=>x+y)
//action
result.print()
//启动
ssc.start()
ssc.awaitTermination()
}
}
编译打包,并上传jar文件

执行TimerProducer.java
结果:

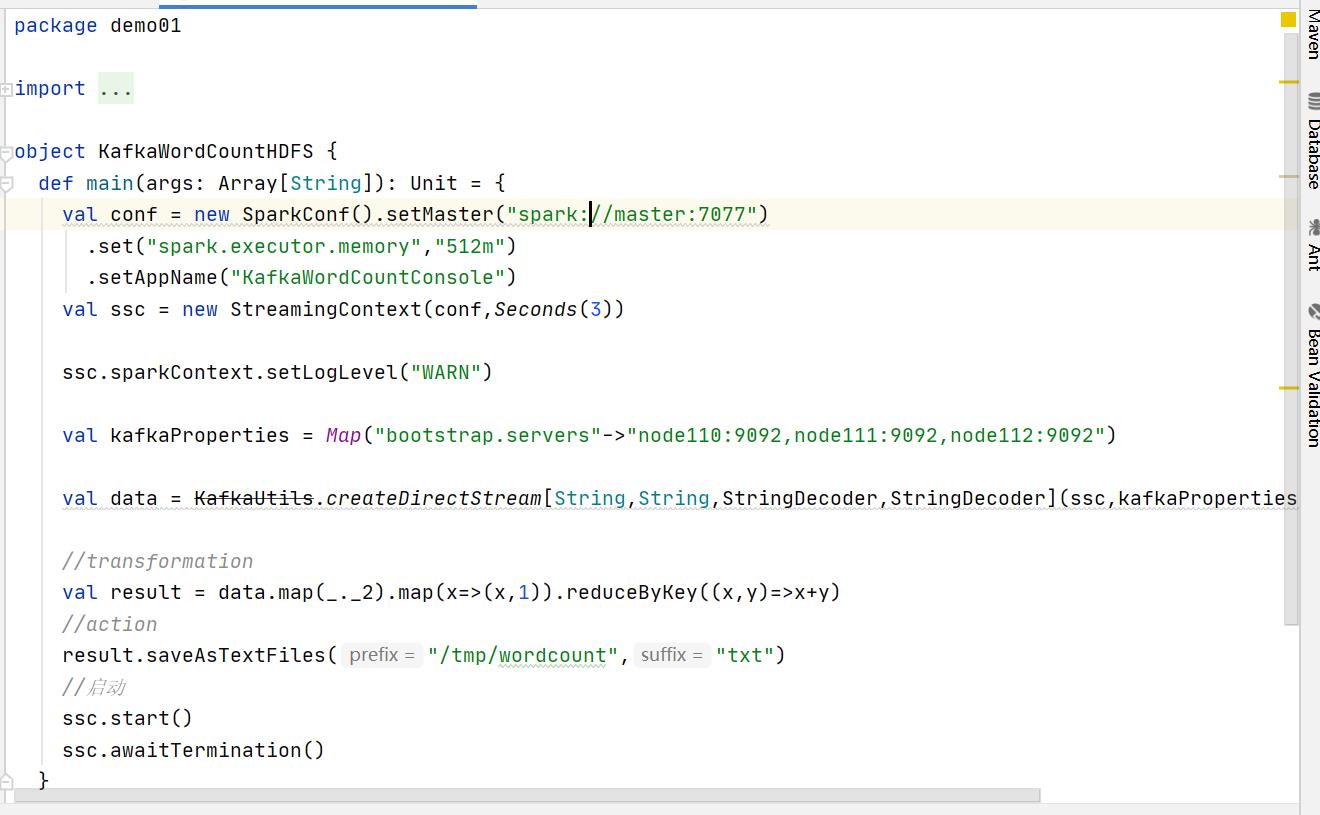
实战二:Kafka消息输出到HDFS|本地测试|集群测试
package demo01
import kafka.serializer.StringDecoder
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
object KafkaWordCountHDFS {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("spark://master:7077")
.set("spark.executor.memory","512m")
.setAppName("KafkaWordCountConsole")
val ssc = new StreamingContext(conf,Seconds(3))
ssc.sparkContext.setLogLevel("WARN")
val kafkaProperties = Map("bootstrap.servers"->"node110:9092,node111:9092,node112:9092")
val data = KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder](ssc,kafkaProperties,Set("test_02_02"))
//transformation
val result = data.map(_._2).map(x=>(x,1)).reduceByKey((x,y)=>x+y)
//action
result.saveAsTextFiles("/tmp/wordcount","txt")
//启动
ssc.start()
ssc.awaitTermination()
}
}
编译打包,上传jar文件
spark提交

运行TimerProducer.java文件
结果:

以上是关于学习笔记Kafka—— Kafka 与Spark集成 —— 原理介绍与开发环境配置实战的主要内容,如果未能解决你的问题,请参考以下文章