强化学习笔记:Q-learning :temporal difference 方法
Posted UQI-LIUWJ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了强化学习笔记:Q-learning :temporal difference 方法相关的知识,希望对你有一定的参考价值。
强化学习笔记:马尔可夫过程 &马尔可夫奖励过程_UQI-LIUWJ的博客-CSDN博客
和MC方法(强化学习笔记:Q-learning_UQI-LIUWJ的博客-CSDN博客)类似,时分TD方法也是 model-free 的,不需要 MDP 的转移矩阵和奖励函数。
TD 可以从不完整的 episode 中学习,同时也结合了Policy evaluation 中bootstrapping 的思想。
1 TD(0)算法
最简单的算法是 TD(0),每往前走一步,就做一步 bootstrapping,用得到的估计回报(estimated return)来更新上一时刻的值。
估计回报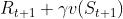 被称为
被称为 TD target,TD target 是带衰减的未来收益的总和。
TD error(误差) 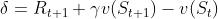 。
。
可以类比于 Incremental Monte-Carlo 的方法,写出如下的更新方法:
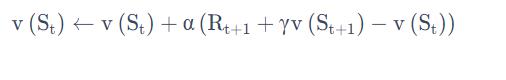
1.1 TD(0)和MC的比较
在 MC 里面Gi,t 是实际得到的值(可以看成 target),因为它已经把一条轨迹跑完了,可以算每个状态实际的 return。
TD(0) 没有等轨迹结束,往前走了一步,就可以更新价值函数。

例如,你想获得开车去公司的时间,每天上班开车的经历就是一次采样。假设今天在路口 A 遇到了堵车,
- TD 会在路口 A 就开始更新预计到达路口 B、路口 C ⋯⋯,以及到达公司的时间;
- 而 MC 并不会立即更新时间,而是在到达公司后,再修改到达每个路口和公司的时间。
TD 能够在知道结果之前就开始学习,相比 MC,其更快速、灵活。
1.2 TD(0)相比于MC的优势
| TD 可以在线学习(online learning),每走一步就可以更新,效率高 | MC 必须等游戏结束才可以学习 |
| TD 可以从不完整序列上进行学习 | MC 只能从完整的序列上进行学习 |
| TD 可以在连续的环境下(没有终止)进行学习 | MC 只能在有终止的情况下学习 |
| TD 利用了马尔可夫性质,在马尔可夫环境下有更高的学习效率 | MC 没有假设环境具有马尔可夫性质,利用采样的价值来估计某一个状态的价值,在不是马尔可夫的环境下更加有效。 |
2 N-step TD
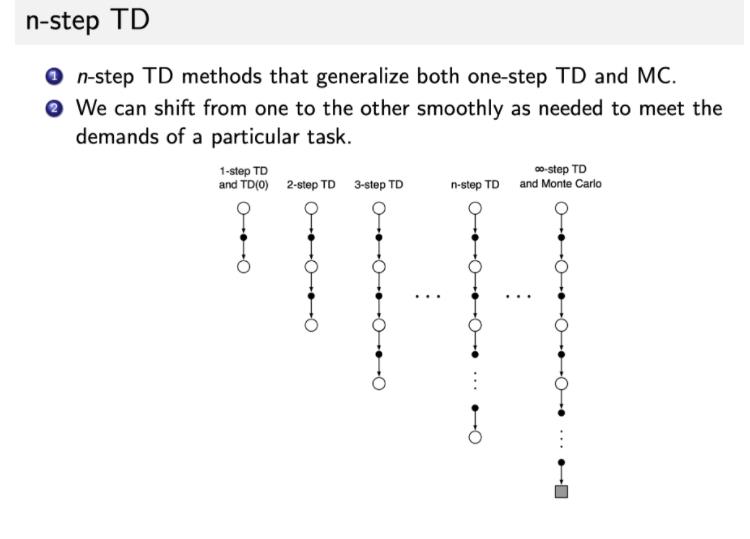
-
我们可以把 TD 进行进一步的推广。之前是只往前走一步,即 one-step TD,TD(0)。
-
我们可以调整步数,变成
n-step TD。比如TD(2),即往前走两步,然后利用两步得到的 return,使用 bootstrapping 来更新状态的价值。 -
这样就可以通过 step 来调整这个算法需要多少的实际奖励和 bootstrapping。

3 DP (Policy evaluation) ,MC 和TD的异同
| MC | DP | TD | |
| Bootstrapping:更新时使用了估计 | MC 没用 bootstrapping,因为它是根据实际的 return 来更新。 | DP 用了 bootstrapping。 | TD 用了 bootstrapping。 |
| Sampling:更新时通过采样得到一个期望 | MC 是纯 sampling 的方法。 | DP 没有用 sampling,它是直接用 Bellman expectation equation 来更新状态价值的。 | TD 用了 sampling。 |
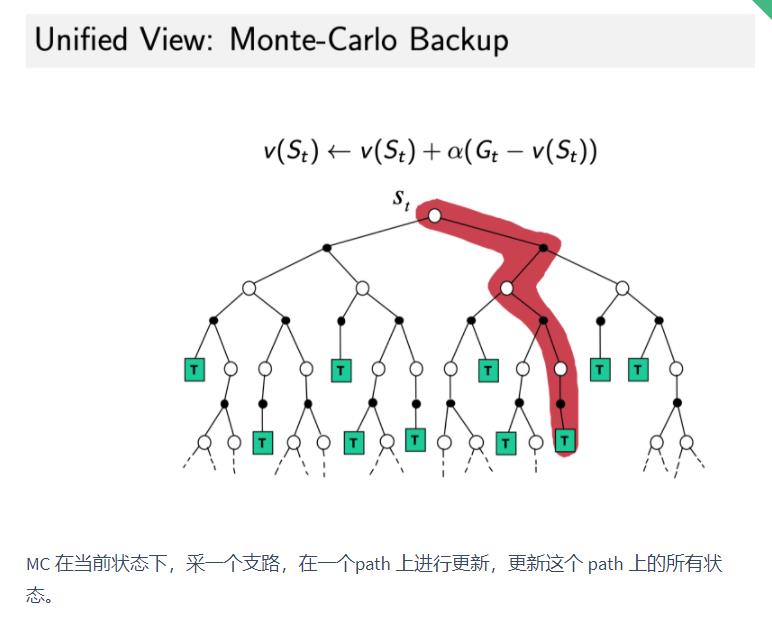 | 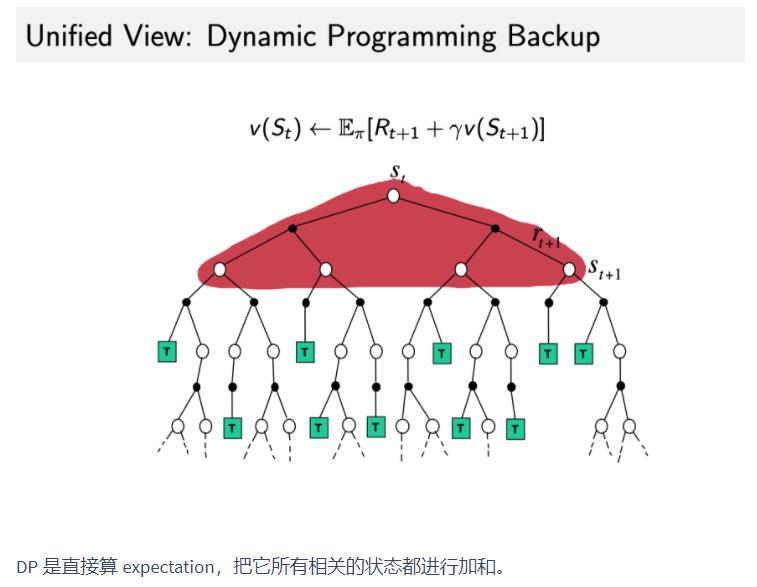 |  | |
| 是否有偏估计 | 无偏估计 | 有偏估计 |
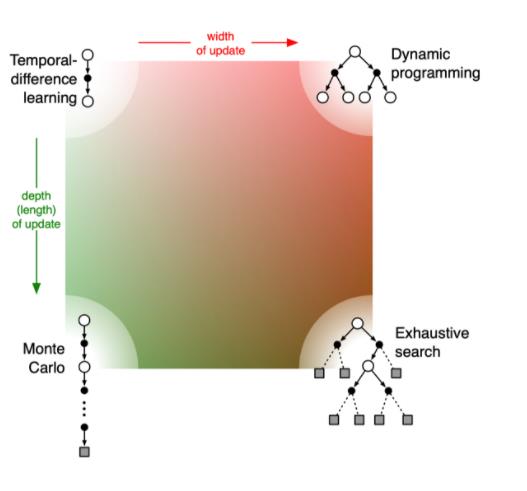
- 如果 TD 需要更广度的 update,就变成了 DP(因为 DP 是把所有状态都考虑进去来进行更新)。
- 如果 TD 需要更深度的 update,就变成了 MC。
- 右下角是穷举的方法(exhaustive search),穷举的方法既需要很深度的信息,又需要很广度的信息。
以上是关于强化学习笔记:Q-learning :temporal difference 方法的主要内容,如果未能解决你的问题,请参考以下文章