2021年中国高校大数据挑战赛-智能运维中的异常检测与趋势预测-A题思路1028版
Posted 数模孵化园
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2021年中国高校大数据挑战赛-智能运维中的异常检测与趋势预测-A题思路1028版相关的知识,希望对你有一定的参考价值。
2021年中国高校大数据挑战赛A题思路 2021年中国高校大数据挑战赛A题思路 2021年中国高校大数据挑战赛A题思路 2021年中国高校大数据挑战赛A题思路 2021年中国高校大数据挑战赛A题思路 2021年中国高校大数据挑战赛A题思路 2021年中国高校大数据挑战赛A题思路 2021年中国高校大数据挑战赛A题思路 2021年中国高校大数据挑战赛A题思路
CSDN:数模孵化园,提供,思路开源持续更新,允许售卖,鼓励进行改进,欢迎加入学习群,这里有漂亮的小姐姐,小哥哥,可脱单。。。

A 智能运维中的异常检测与趋势预测
首先按题目要求整理好关键数据


虽然题目只要求用到了几个指标,但是其余指标也都可以用,可以用来描述设备的运行状态,怎么用要看第一问检测出的异常变动和其余哪些指标具有强相关性,如果有就可以作为后期预测的参考,没有就不做,
虽然本题目告诉了数据具有周期性,也谈到了异常,很明显时间序列解题方向是没错,用异常检测算法检测出异常数据,然后需要对异常数据进行修正,这里的修正我个人觉得不是简单套一个算法解决,数据异常只是设备的问题,而数据趋势肯定不和设备有关,虽然这道题没说舆情,但是自己想一下用户的活跃,是否和娱乐圈、电影、新冠疫情、股市期货、猪肉价格等等事件相关呢,这也并不是说要人人都去爬取微博、知乎、东方财富等网站的评论然后做热词分析,量太大时间也来不及,这里推荐百度指数、微指数、谷歌趋势、360趋势。
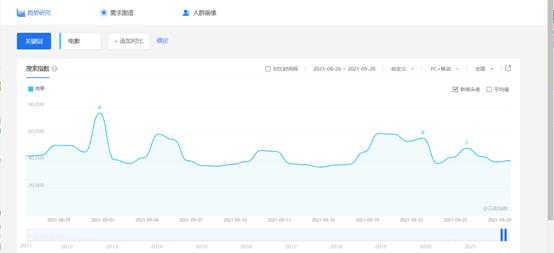
疫情数据国内外都可以,以及股市大盘的走向,或者比较关心的猪肉价格走势等等,分别构建本题三个关键指标的指标体系,然后用这些指标数据作为训练输入,关键指标作为输出,分别通过机器学习方法去修正检测到的数据,如何给自己增加亮点自己考虑,随便套用算法谁都会
来看看第一问,一定是针对每个小区编号来做分析,做分析前一定是要对数据进行平滑处理,虽然说平滑后会导致数据失真,那肯定不能平滑的太厉害,平滑程度至少要把异常数据段凸显出来,其实是有必要进行平滑的,只要趋势一致就行,这样主要利于后问的分析。接下来是先检测异常数据,这三个关键指标理论上应当是相关性较强的,因此可以直接比对趋势就可以比对出来,并不是单独对每个关键指标用异常检测算法去做。就比如说下面这个小区的数据肯定没有异常,异常检测如果一定要写个唬人的,就写通过设立滤波矩阵去对趋势异常进行检测的,还有一个需要注意的是,人们睡觉期间肯定没有太多的活跃数据,可以单独对0点到7点进行检测,用户和基站数据肯定是比较低的

异常周期好算,如果有两个以上异常点就可以算异常周期,然后进行异常值修正,如果不想用上面说到的修正方法,哪怕你直接其中一个关键指标的趋势去等比计算也可以

时间周期推荐两个方法,一个是傅里叶变化的平均时间周期,第二个是混沌理论中的时延(常见的有自相关法、互信息法、平均位移法等,在matlab混沌时间序列工具箱中都有)
| function T_mean=period_mean_fft(data) %该函数使用快速傅里叶变换FFT计算序列平均周期 %data:时间序列 %T_mean:返回快速傅里叶变换FFT计算出的序列平均周期 Y = fft(data); %快速FFT变换 N = length(Y); %FFT变换后数据长度 Y(1) = []; %去掉Y的第一个数据,它是data所有数据的和 power = abs(Y(1:N/2)).^2; %求功率谱 nyquist = 1/2; freq = (1:N/2)/(N/2)*nyquist; %求频率 figure plot(freq,power); grid on %绘制功率谱图 xlabel('频率') ylabel('功率') title('功率谱图') period = 1./freq; %计算周期 figure plot(period,power); grid on %绘制周期-功率谱曲线 ylabel('功率') xlabel('周期') title('周期—功率谱图') [mp,index] = max(power); %求最高谱线所对应的下标 T_mean=period(index); %由下标求出平均周期 |
第一问也差不多就是确定周期参数和一场数据检测和处理,来看第二问
注意是每个小区单独分析,如果有异常就有异常,每异常就别故意增加异常
如果按前面说的找舆情数据,那这个问就比较好做,为什么前面要说如果能用上设备状态的数据就用,设备的运行,主要有天气和负载导致的,地理位置都没给也没办法对标天气数据,分析设备参数与三个关键指标的相关性后,如果没发现相关性较高的设备状态指标,这里也可以通过基站服务范围所有用户的活跃情况来反映。第二问首先是异常预测,在历史数据中,三个关键指标以及一些舆情指标、小区所属基站的整体三个关键指标值,异常点输出1,正常输出0,建立一个二分类的模型,为什么还要结合基站来分析,一个基站服务多个小区,就算一个小区看着数据正常,但是也不能保证会因为其他小区导致高过载引起的异常,就例如平时的网络波动,大家在做题目的时候一定是要结合生活实际去分析,在使用算法算出比较好的结果的同时,也应当具有完善的逻辑
第三问是预测,先对异常处理后的三个关键指标数据进行预测,第一问的周期是需要用上的,在混沌时间序列中,时延和周期是其中算法的输入参数,也就刚好接上了第一问,这个问可以先用混沌时间序列方法进行预测(RBF神经网络一步预测、RBF神经网络多步预测、Volterra级数一步预测、Volterra级数多步预测等),预测之后再同样的用第二问做法过一遍,如果预测出数据,接下来还需考虑异常变化量,异常变化量可通过第二问中的过程数据求一个关系式,这里加减就行。最后建议输出无异常的趋势和存在异常的趋势
以上是关于2021年中国高校大数据挑战赛-智能运维中的异常检测与趋势预测-A题思路1028版的主要内容,如果未能解决你的问题,请参考以下文章