MYSQL索引详解
Posted 敲代码的小小酥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MYSQL索引详解相关的知识,希望对你有一定的参考价值。
一、命名规范
mysql表的命名规范: 全部小写,见名知意,不要用复数,不要用关键字。
索引的命名规范: 主键索引以pk_开头,唯一索引用uk_开头,普通索引用idx_开头,后面跟索引列名称,有几个跟几个。
二、主键索引(聚集索引)
主键索引是Mysql根据主键,自动创建的索引,如果没有主键,则根据唯一索引创建,没有唯一索引,mysql会创建一个隐含的rowid来做主键,进行主键索引的创建。
主键索引用的是B+tree,以主键作为非叶子节点的键值,每个非叶子节点,就是根据主键大小排列,然后取中间的值作为父节点,对主键数据进行树的构建。当一个节点主键数据超过树阶的大小后,进行分裂(详情请看上一篇文章)。最后,把所有的主键都构建成树后,将行记录数据放在B+树的叶子节点中。
所以,聚集索引叶子节点上存放的是完整的每行记录。因此,可以通过聚集索引能获取完整的行数据,对于主键排序和范围查询速度很快。
(B+tree查询数据,都是在叶子节点进行查询的,非叶子节点只起到索引左右,不获取数据)
三、二级索引(辅助索引)
我们自己对表进行优化,创建的索引,成为二级索引。
二级索引树的构建过程也是B+tree的构建过程,只不过,索引列是哪个,非叶子节点的值就是哪个。构建到最后的叶子节点后,存放所有的索引列的值,但是没有其他列的数据。所以二级索引只能获得到索引列的数据。
在叶子节点中,除了存索引列的数据,还会存主键id数据。存放的目的是为了回表用。什么是回表呢?
上面说到,二级索引的叶子节点只存放索引列数据。那么我们在sql中select 多个字段的时候,非索引列的数据如何获取到呢?就是根据叶子节点存放的id值,去聚集索引中查询其余列的值,这就叫回表。
因为聚集索引中有整行的记录,所以通过回表,获取到非索引列的数据。
回表会影响一定的性能,因为要走两颗B+tree,当然不如只走一棵树性能高。那我们是否可以把所有字段都加入到一个索引中呢。这样的话,索引占用的空间就大了,也是浪费性能,所以,是回表,还是加入多列成索引,需要在具体业务场景中进行尝试,优化,再做决定。
需要注意的是,回表的作用不仅仅是获取select的非索引列而用,还有一个作用就是在使用了索引查询出来数据后,可能还有一个非索引列的查询条件,这个条件,也要在回表时进行过滤查询,所以回表还有过滤数据的作用。例如:a列有索引,b列没有索引,则如下语句:
select * from table where A> xxx and B='xxx';
在使用A列索引查询完数据回表后,还要查询出满足B列条件的数据,才返回。
需要注意的是,mysql优化器会根据回表次数进行判断,如果回表次数过多,可能出现虽然有索引,但是不走索引,走全表扫描的情况。因为mysql会认为全表扫描付出的代价要比多次回表更低。
四、联合索引(复合索引)
一个索引中包含多个列,就是联合索引。而不同列创建多个索引,那是多个不同的索引,注意区分。
在联合索引中,只创建一个B+tree。而多个索引,则有几个索引,创建几个B+tree。
联合索引创建B+tree时,是按照第一列作为索引优先,第二列的排序其次…依次类推,来创建非叶子节点的,在叶子节点,对第一列的数据进行排序,然后,第一列相同的数据,按第二列数据进行排序,依次类推。所以,在联合索引中,最关键的是第一列,在列的顺序上,是有讲究的。这也是最左原则的根本原因。为什么like的左面加%索引失效,也是这个原因。
需要注意的是,在非叶子节点上,也都有联合索引列 的信息,在通过非叶子节点二分定位叶子节点时,是通过几个列共同结合,定位到哪个下级节点的。因为联合索引是多列共同结合来划分节点的,所以第一列相同的值,第二列不同的值,会划分出多个节点来,所以定位下级节点时,要结合多个列进行定位。
当联合索引中的列能满足查询条件时,通过联合索引,就能返回需要的字段数据,这时就不用进行回表操作了,性能也相应提高。这种现象,叫做索引覆盖。
五、扫描区间
在innodb的B+tree索引中,只要索引列与常数使用=、!=、in、not in、>=、<=、between、like等时,就会产生一个区间。
需要指出的是,B+tree进行范围查询时,是根据最小的临界范围定位到叶子节点,然后在叶子节点上进行比较,直到扫出查询范围内的值。
in: 会产生多个单点区间,和用or连接起来的等值查询是一样的。
!=:产生两片区间,一个是从叶子节点开始到!=的值,一段是!=的值到叶子节点结束。
like: 对于Like来说,首先%不能写在左侧,否则索引失效。而写在右侧后,对于字符串来说,首字母相同的数据,肯定是按大小排序排列在一起的,例如,like ‘b%’,那么肯定是在叶子节点中找到第一个b开头的数据,然后沿着叶子节点的链表进行查找,直到第一条不是b开头的数据为止,形成一块区间,如下图:
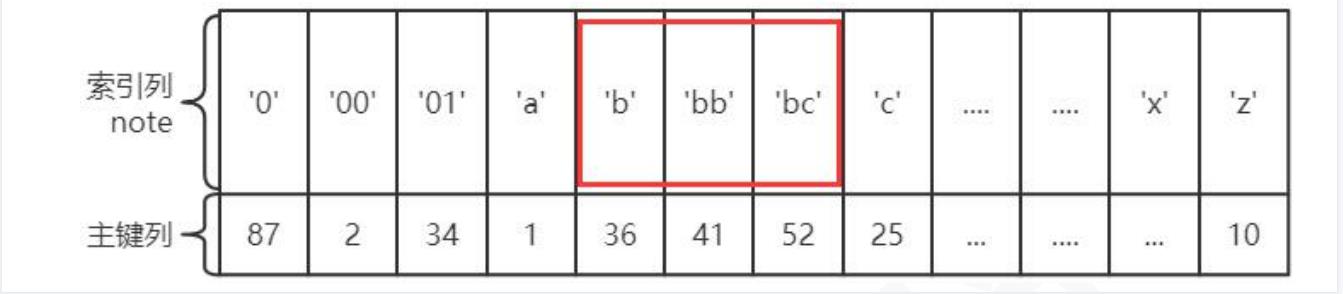
而对于联合索引来说,第一列相同值的数据,节点肯定是相邻的,然后按照第二列排序,第二列相同的数据肯定也是相邻的,然后按照第三列排序…依次类推。在形成区间时,也是按照这个特性进行生成的。
六、索引的使用
一个索引就是一个B+树,在一个select查询中,一般最多只能用一个二级索引,即使在where条件中用到了多个二级索引的列。
那么mysql到底使用哪个索引来查询数据呢?mysql会分析使用每个索引的各种情况,包括性能消耗,扫描数据多少,数据重复多少等等,来判断使用哪个索引最优,然后选择这个索引进行查询。这就是为何用这个索引,而不用那个索引的原因,也是为何有时mysql不执行索引,而是走全表扫描的原因。当mysql认为全表扫描更合适,就不会走索引了。当我们不知道创建哪个列为索引合适时,那就涉及到的列都创建索引,让mysql决定用哪个索引查询。当数据量,数据重复度,查询条件不同时,同一个sql语句,可能会使用不同的索引,来进行查询,mysql会选择最优的方式,来进行。
七、索引的优化
索引虽然能高效查询,但是需要占用空间,而且前面B+tree的添加数据也可以看出,对B+tree的影响很大。索引在增删数据的时候,影响很大,索引索引不是随便加的。下面看索引的优化:
- 尽量选数据类型小的列作为索引列;
- 选择数据重复度低的列作为索引。因为数据重复度越高索引过滤掉的数据就越少,mysql越认为等同于走全表扫描。索引唯一索引的性能是最高的。可以通过:
select count(distinct A)/count(*) from table
来查看每个列的重复度。
3. 使用前缀索引,当列的数据字段很大时,又要对该列创建索引,可以使用前缀索引,来减少索引的空间。
4. 只为搜索,排序或分组的列创建索引。当然这个也不能一概而论,有些时候,使用覆盖索引可能性能会更高。
5. 联合索引,调整列的顺序。这个在联合索引中已经讲过。
6. 删除重复索引和冗余索引。例如联合索引和单独创建的联合索引中第一列的索引就算重复索引,要去掉。
7. null值在索引列会对索引造成影响,mysql默认为null值都是相同的,会集中单独处理,null越多相当于重复值越多。所以,可以将null值替换为-1或其他特殊值,代表null。来消除mysql对null单独处理造成的消耗。
8. 在多表查询中,关联查询的两表的列,都要建立索引。
画外音:
在Innodb中,全表扫描的含义就是在聚集索引的叶子节点中,从头到尾扫一遍数据。
以上是关于MYSQL索引详解的主要内容,如果未能解决你的问题,请参考以下文章