又被 AI 抢饭碗?2457 亿参数规模,全球最大中文人工智能巨量模型 “源1.0”正式开源...
Posted AI科技大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了又被 AI 抢饭碗?2457 亿参数规模,全球最大中文人工智能巨量模型 “源1.0”正式开源...相关的知识,希望对你有一定的参考价值。


作者 | 伍杏玲
出品 | AI科技大本营(ID:rgznai100)
输入:
昔我往矣,杨柳依依。
今我来思,雨雪霏霏。
行道迟迟,载渴载饥。
我心伤悲,莫知我哀!
(以战争为题写一首诗)
回复:
我欲东归,害我者谁?
我欲西归,谁当为守?
我欲南归,谁与借逝?
我欲东归,谁与更岁?
我欲与归,道里辽远,山川悠长。
我欲与归,而无与归。
大家瞅一瞅,这工整、这情感,你可能会猜是哪位文艺青年写的?
原来这位“文艺青年”叫“源1.0”,是浪潮信息最新研发的中文人工智能巨量模型。好玩吧?在 2021 人工智能计算大会(AICC)上,“源1.0”正式亮相,小编还用“程序”为主题请 “源1.0”当场作词,大家品品这诗句属于什么水平?
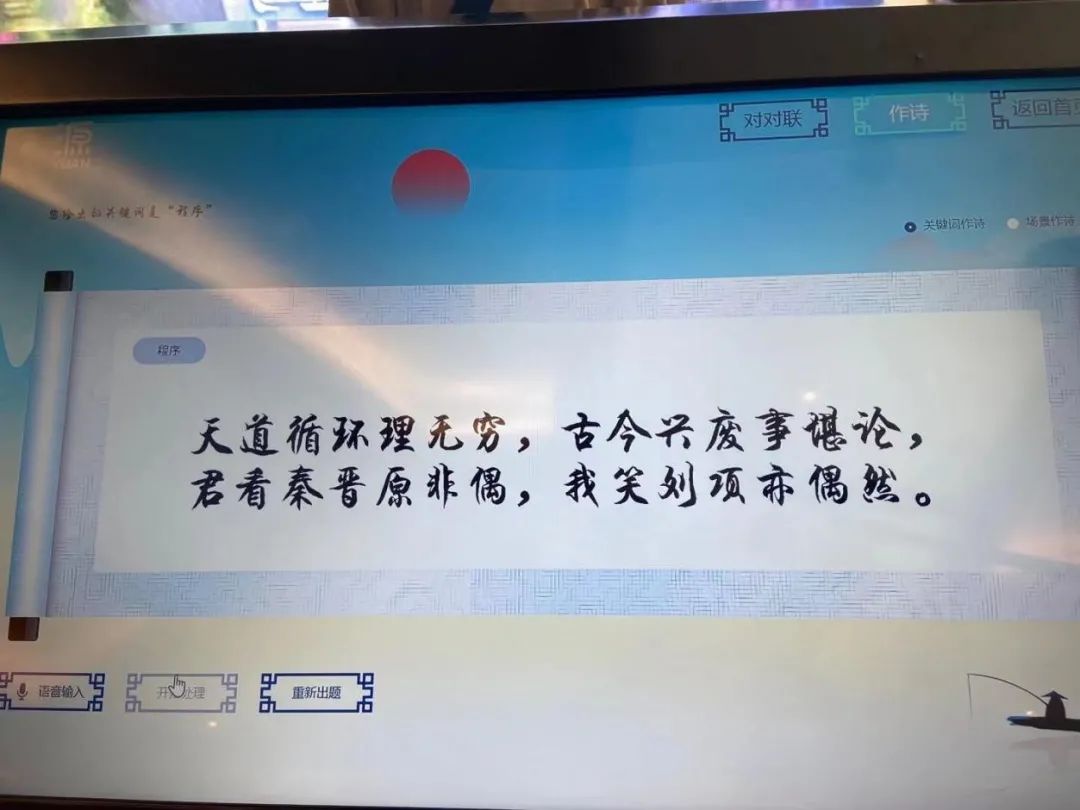

2457 亿参数规模,“源1.0”到底有多牛?
去年,涵盖 1750 亿参数的 GPT-3 一经发布,引发大众惊呼“GPT-3可以改变世界了”。而浪潮信息发布的“源1.0”被称为“全球最大规模的中文AI巨量模型”,参数规模高达 2457 亿,训练采用的中文数据集达5000GB,获得中文语言理解评测基准CLUE榜单的零样本学习和小样本学习两类总榜冠军,模型能力大幅度提升。
据介绍,“源1.0”可以创建任何具有语言结构的东西,可自动问答,撰写文章、诗歌、小说、新闻报道,翻译语言,还可以写代码。最关键的是,“源1.0”可以理解文字的含义,从中抽取关键信息,做出回复,如文章开头“源1.0”堪比“对穿肠”,回复的诗句富含感情,其创作能力、学习能力表现不俗。
在人机对比测试中,将“源1.0”模型生成的对话、小说续写、新闻、诗歌、对联与由人类创作的同类作品进行混合并由人群进行分辨,测试结果表明,测试人员准确分辨人与“源1.0”作品差别的成功率已低于 50%。
如此一来,“源1.0”可用于智能客服、文字识别、文本搜索、翻译、智能运维、智能助手等应用中。以智能客服为例,可感知客户的情绪,以便更好地理解客户的需求,提供更人性化的服务。
这下子小编的饭碗是不是要不保了?AI 太强大了。

“源1.0”正式开源
浪潮信息副总裁、浪潮信息 AI & HPC 产品线总经理刘军表示,如今算力正在助推中国人工智能产业快速发展,技术、区域、行业、应用场景等多个维度都在加速发展。其中智算呈现多元化、巨量化、生态化的发展趋势。
(1)多元化:2021年全球 AI 芯片厂商超 150 家,NPU、IPU、VPU、TPU、DPU、GPU 等 AI 计算芯片百花齐放。多元化的芯片发展为产业 AI 化的加速提供了重要的产业基础和更加多元化的选择,但如何让多元算力走向产业,实现算力普适普惠的关键。
(2)巨量化:模型和使用量巨大,如国外 OpenAI、微软、谷歌、英伟达等企业均在发力“大模型”,如微软联手英伟达推出的 5300 亿参数“威震天-图灵自然语言生成模型(Megatron Turing-NLG)”。
(3)生态化:开放生态造就产业繁荣。对此,为推进算法基础设施建设的发展,浪潮信息在大会上公布 “源1.0”开放开源的计划,为降低巨量模型研究和应用门槛,推进AI产业化和产业AI化进程,“源1.0”面向学术研究单位和产业实践用户进行开源、开放、共享。目前的合作内容涵盖模型API、高质量中文数据集、模型训练代码、模型推理代码、模型应用代码等。
谈及未来,浪潮信息表示,源 2.0 将往多模态、视觉领域开展。

巨量模型“源1.0”的诞生 ,源自浪潮信息 AI 十年探索的底气
提及浪潮信息,可能大伙首先想到的是服务器。早在2012 年,浪潮信息与英特尔、英伟达成立并行计算实验室,研发 MIC 和 GPU 异构加速技术;2015年,浪潮信息提出“计算+”战略,开始对深度学习框架单机版进行异构扩展优化工作。
紧接着通过软硬结合的方式大力发展 AI。在硬件上,基于GPU、MIC 和 FPGA 等 HPC 异构计算应用能力的积累,提出前沿的可重构计算解决方案;在软件上,推出深度学习管理平台 AI-Station;在生态建设上,浪潮信息携手具有 AI 自研能力的左手伙伴和具有 AI 交付能力的 SI、ISV 右手伙伴,共同推动 AI产业发展。
目前,浪潮信息AI 服务器市占率已位居全球第一,连续四年中国市场占比超过50%;在深度学习框架领域,浪潮信息推出了深度学习并行计算框架 Caffe-MPI、TensorFlow-Opt、全球首个 FPGA 高效 AI 计算开源框架 TF2 等。2020年,浪潮信息在人工智能领域的专利贡献达到1174 件,位居中国前列。由此可见,本次“源1.0”的诞生与开源开放,来源于浪潮信息近 10 年在 AI 领域的积累。


往
期
回
顾
资讯
资讯
资讯
技术

分享

点收藏

点点赞

点在看
以上是关于又被 AI 抢饭碗?2457 亿参数规模,全球最大中文人工智能巨量模型 “源1.0”正式开源...的主要内容,如果未能解决你的问题,请参考以下文章
全球最大中文单体模型来了!2600亿参数,AI产业规模化应用可期