回顾一下大学学的数据结构
Posted 折桂怀橘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了回顾一下大学学的数据结构相关的知识,希望对你有一定的参考价值。
最近想回顾一下数据结构,今天看到一篇内容是是关于 ‘二叉树 ’的,突然感觉数据结构忘记了好多,今天来整理一下把,还曾记得当初准备考研的时候,数据结构还是学的不错的,没想到忘记的这么快~~~
一 基本概念
1、栈的特点是"LIFO,即后进先出(Last in, first out)"。数据存储时只能从顶部逐个存入,取出时也需从顶部逐个取出。(就像是一个杯子一样,先放入的要想拿出来话,就得先拿出后放入得)
var arr = [1, 2, 3, 4, 5];
arr.push(6); // 存入数据 arr -> [1, 2, 3, 4, 5, 6]
arr.pop(); // 取出数据 arr -> [1, 2, 3, 4, 5]
2、堆的特点是"无序"的key-value"键值对"存储方式。
我们想要在书架上找到想要的书,最直接的方式就是通过查找书名,书名就是我们的key。
堆是一种经过排序的树形数据结构,每个节点都有一个值,通常我们所说的堆的数据结构是指二叉树。所以堆在数据结构中通常可以被看做是一棵树的数组对象。而且堆需要满足一下两个性质:
(1)堆中某个节点的值总是不大于或不小于其父节点的值;
(2)堆总是一棵完全二叉树。
在程序中,堆用于动态分配和释放程序所使用的对象。在以下情况中调用堆操作:
1.事先不知道程序所需对象的数量和大小。
2.对象太大,不适合使用堆栈分配器。
3、队列的特点是是"FIFO,即先进先出(First in, first out)" 。数据存取时"从队尾插入,从队头取出"。
“与栈的区别:栈的存入取出都在顶部一个出入口,而队列分两个,一个出口,一个入口”。
var arr = [1, 2, 3, 4, 5];
// 队尾in
arr.push(6); // 存入 arr -> [1, 2, 3, 4, 5, 6]
// 队头out
arr.shift(); // 取出 arr -> [2, 3, 4, 5, 6]
JS引用
1、JavaScript中变量类型有两种:
基础类型(Undefined, Null, Boolean, Number, String, Symbol)一共6种
引用类型(Object)
1)JS中的基础数据类型,这些值都有固定的大小,往往都保存在栈内存中(闭包除外),由系统自动分配存储空间。我们可以直接操作保存在栈内存空间的值,因此基础数据类型都是按值访问 数据在栈内存中的存储与使用方式类似于数据结构中的堆栈数据结构,遵循后进先出的原则。
2)JS的引用数据类型,比如数组Array,它们值的大小是不固定的。引用数据类型的值是保存在堆内存中的对象。JS不允许直接访问堆内存中的位置,因此我们不能直接操作对象的堆内存空间。在操作对象时,实际上是在操作对象的引用而不是实际的对象。因此,引用类型的值都是按引用访问的。这里的引用,我们可以粗浅地理解为保存在栈内存中的一个地址,该地址与堆内存的实际值相关联。
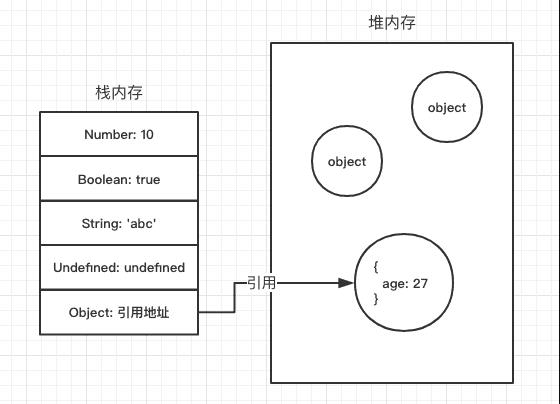
"浅拷贝:栈存储拷贝"
"深拷贝:栈堆存储拷贝"
垃圾回收机制
javascript中有自动垃圾回收机制,会通过标记清除的算法识别哪些变量对象不再使用,对其进行销毁。开发者也可在代码中手动设置变量值为null(a = null)进行标记清除,让其失去引用,以便下一次垃圾回收时进行有效回收。
局部环境中,函数执行完成后,函数局部环境声明的变量不再需要时,就会被垃圾回收销毁(理想的情况下,闭包会阻止这一过程)。
全局环境只有页面退出时才会出栈,解除变量引用。所以开发者应尽量避免在全局环境中创建全局变量,如需使用,也要在不需要时手动标记清除,将其内存释放掉。
为什么会有栈内存和堆内存之分?
通常与垃圾回收机制有关。为了使程序运行时占用的内存最小。
当一个方法执行时,每个方法都会建立自己的内存栈,在这个方法内定义的变量将会逐个放入这块栈内存里,随着方法的执行结束,这个方法的内存栈也将自然销毁了。因此,所有在方法中定义的变量都是放在栈内存中的;
当我们在程序中创建一个对象时,这个对象将被保存到运行时数据区中,以便反复利用(因为对象的创建成本通常较大),这个运行时数据区就是堆内存。堆内存中的对象不会随方法的结束而销毁,即使方法结束后,这个对象还可能被另一个引用变量所引用(方法的参数传递时很常见),则这个对象依然不会被销毁,只有当一个对象没有任何引用变量引用它时,系统的垃圾回收机制才会在核实的时候回收它。
JavaScript是单线程
栈顶的执行上下文处于执行中,其它需要排队
全局上下文只有一个处于栈底,页面关闭时出栈
函数执行上下文可存在多个,但应避免递归时堆栈溢出
函数调用时就会创建新的上下文,即使调用自身,也会创建不同的执行上下文
4)链表是由一组节点组成的集合。每个节点都使用一个对象的引用指向它的后继。许多链表的实现都在链表最前面有一个特殊节点,叫做头节点。
在这里我能联想到作用域链
当代码在一个环境中执行时,会创建变量对象的一个作用域链。
作用域链的用途:保证对执行环境有权访问的所有变量和函数的有序访问。
作用域链的前端,始终是当前执行的代码所在环境的变量对象,若此环境是函数,则将其活动对象作为变量对象。
- 函数在执行的过程中,先从自己内部找变量,
- 如果找不到,再从创建当前函数所在的作用域去找, 以此往上,
- 注意找的是变量的当前的状态。
在这里我能联想到原型链
当这个对象没有这个属性的时候,去它自身的隐式原型中找,它自身的隐式原型就是它构造函数(Foo)的显式原型(Foo.prototype)但显式原型(Foo.prototype)中并没有 toString ;但显式原型(Foo.prototype)也是对象,也要在它的隐式原型中找,即在其构造函数 (Object )的显式原型中去找 toString. 故要在 f.proto(隐式原型)的.proto(隐式原型)中找,如图所示,故输出 null

5)二叉树:树是一种非线性的数据结构,以分层的方式存储数据,特别是有序列表。树可以分为几个层次,根节点是第0层。没有任何子节点的节点称为叶子节点。
二叉树是一种特殊的树,二叉树进行查找、添加、删除都非常快。二叉树每个节点的子节点不允许超过两个。相对较小的值保存在左节点中,较大的值保存在右节点中。
二、排序
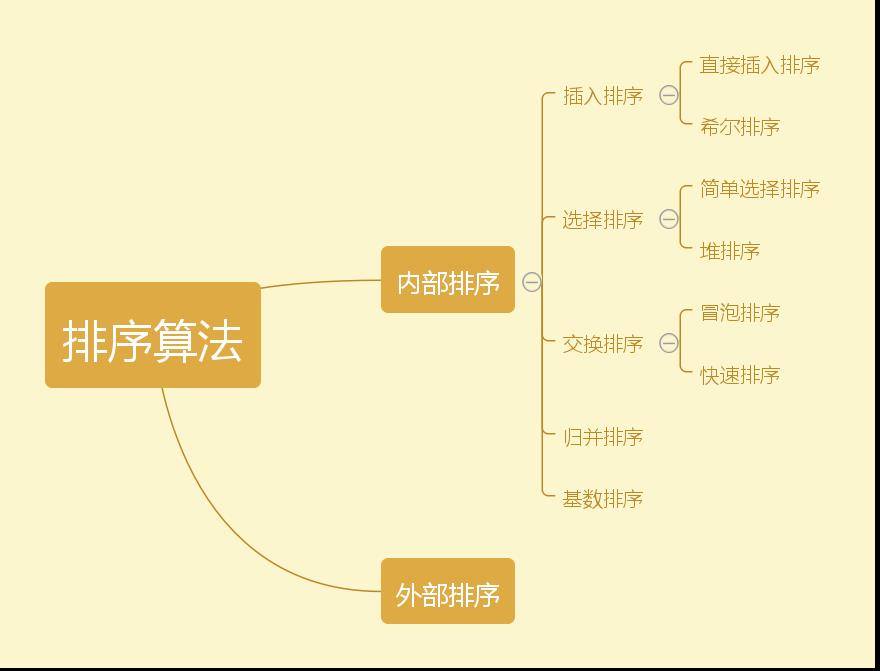
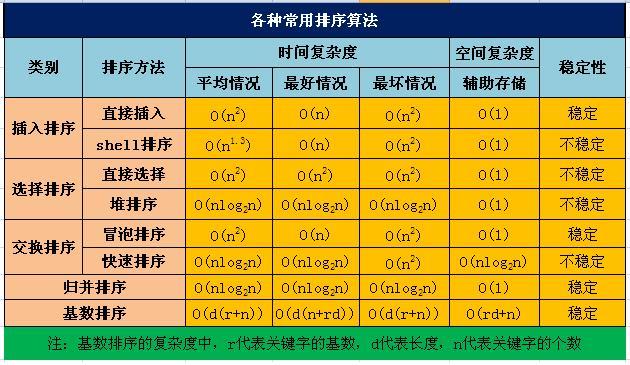
直接插入排序(Straight Insertion Sort)的基本思想是:把n个待排序的元素看成为一个有序表和一个无序表。开始时有序表中只包含1个元素,无序表中包含有n-1个元素,排序过程中每次从无序表中取出第一个元素,将它插入到有序表中的适当位置,使之成为新的有序表,重复n-1次可完成排序过程。
以上是关于回顾一下大学学的数据结构的主要内容,如果未能解决你的问题,请参考以下文章