MySQL面试夺命连环24问
Posted Java后端何哥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL面试夺命连环24问相关的知识,希望对你有一定的参考价值。
1、mysql 逻辑架构分层
把 MySQL 分成三层,跟客户端对接的连接层,真正执行操作的服务层,和跟硬件打交道的存储引擎层。
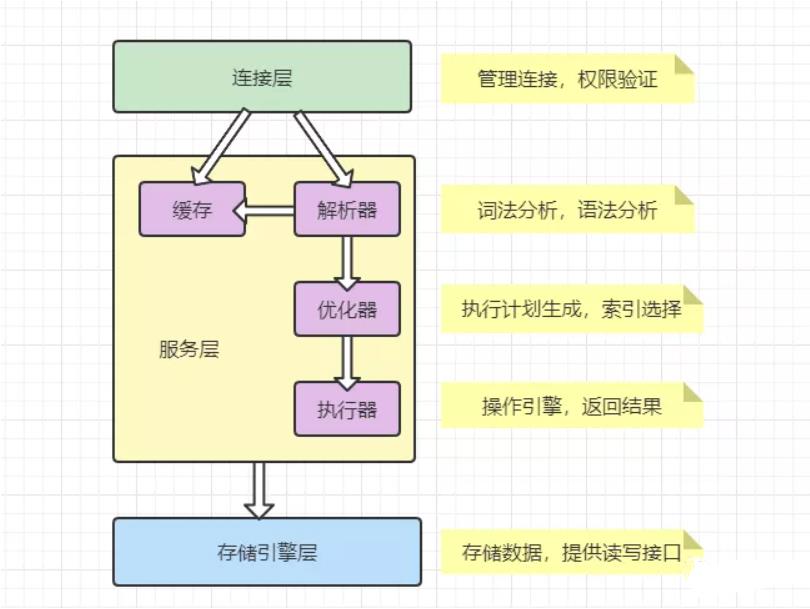 Mysql逻辑架构图主要分三层:
Mysql逻辑架构图主要分三层:
(1)第一层负责连接处理,授权认证,安全等等
(2)第二层负责编译、语法分析并优化SQL
(3)第三层是存储引擎。
连接层
我们的客户端要连接到 MySQL 服务器 3306 端口,必须要跟服务端建立连接,那么管理所有的连接,验证客户端的身份和权限,这些功能就在连接层完成。
服务层
连接层会把 SQL 语句交给服务层,这里面又包含一系列的流程:
比如查询缓存的判断、根据 SQL 调用相应的接口,对我们的 SQL 语句进行词法和语法的解析(比如关键字怎么识别,别名怎么识别,语法有没有错误等等)。
然后就是优化器,MySQL 底层会根据一定的规则对我们的 SQL 语句进行优化,最后再交给执行器去执行。
存储引擎
存储引擎就是我们的数据真正存放的地方,在 MySQL 里面支持不同的存储引擎。再往下就是内存或者磁盘。
2、一条SQL查询语句在MySQL中如何执行的?
-
先检查该语句是否有权限,如果没有权限,直接返回错误信息,如果有权限会先查询缓存(MySQL8.0 版本以前)。
-
如果没有缓存,分析器进行词法分析,提取 sql 语句中 select 等关键元素,然后判断 sql 语句是否有语法错误,比如关键词是否正确等等。
-
最后优化器确定执行方案进行权限校验,如果没有权限就直接返回错误信息,如果有权限就会调用数据库引擎接口,返回执行结果。
3、MySQL查询缓存
MySQL 内部自带了一个缓存模块。执行相同的查询之后我们发现缓存没有生效,为什么?MySQL 的缓存默认是关闭的。
show variables like 'query_cache%';
默认关闭的意思就是不推荐使用,为什么 MySQL 不推荐使用它自带的缓存呢?
主要是因为 MySQL 自带的缓存的应用场景有限:
第一个是它要求 SQL 语句必须一模一样,中间多一个空格,字母大小写不同都被认为是不同的的 SQL。
第二个是表里面任何一条数据发生变化的时候,这张表所有缓存都会失效,所以对于有大量数据更新的应用,也不适合。
所以缓存还是交给 ORM 框架(比如 MyBatis 默认开启了一级缓存),或者独立的缓存服务,比如 Redis 来处理更合适。
在 MySQL 8.0 中,查询缓存已经被移除了。
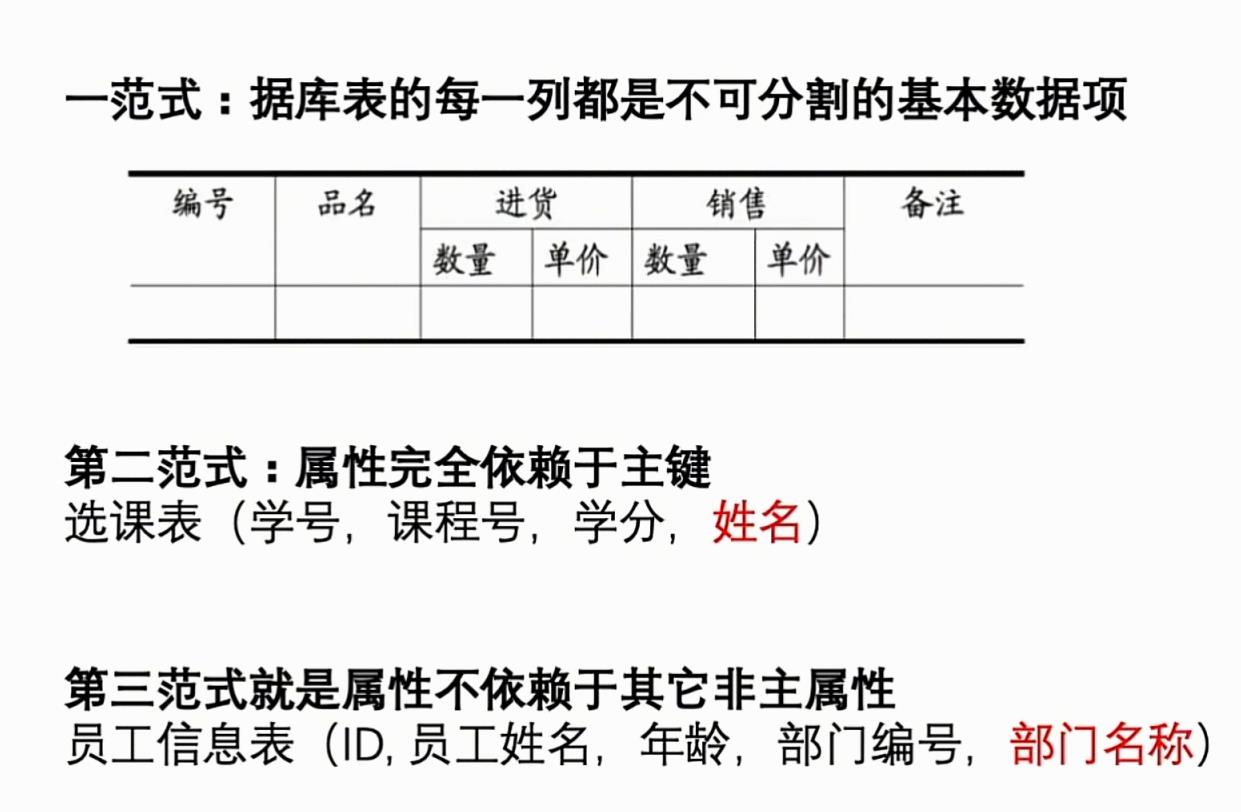
4、数据库三大范式
5、能说下存储引擎myisam 和 innodb的区别吗?
myisam引擎是5.1版本之前的默认引擎,支持全文检索、压缩、空间函数等,但是不支持事务和行级锁,所以一般用于有大量查询少量插入的场景来使用,而且myisam不支持外键,并且索引和数据是分开存储的。
innodb是基于聚簇索引建立的,和myisam相反它支持事务、行级锁、外键,并且通过MVCC来支持高并发,索引和数据存储在一起。
6、MySQL事务的四大特性
一般来说,事务是必须满足4个条件(ACID):原子性(Atomicity,或称不可分割性)、一致性(Consistency)、隔离性(Isolation,又称独立性)、持久性(Durability)。
-
原子性(Atomicity):事务作为一个整体被执行,包含在其中的对数据库的操作要么全部被执行,要么都不执行。
-
一致性(Consistency):指在事务开始之前和事务结束以后,数据不会被破坏,假如A账户给B账户转10块钱,不管成功与否,A和B的总金额是不变的。
-
隔离性(Isolation):多个事务并发访问时,事务之间是相互隔离的,即一个事务不影响其它事务运行效果。简言之,就是事务之间是井水不犯河水的。
-
持久性(Durability):表示事务完成以后,该事务对数据库所作的操作更改,将持久地保存在数据库之中。
7、事务的隔离级别有哪些?MySQL的默认隔离级别是什么?
Mysql默认的事务隔离级别是可重复读(Repeatable Read),而大多数数据库默认的事务隔离级别是Read committed,比如Sql Server , Orale。
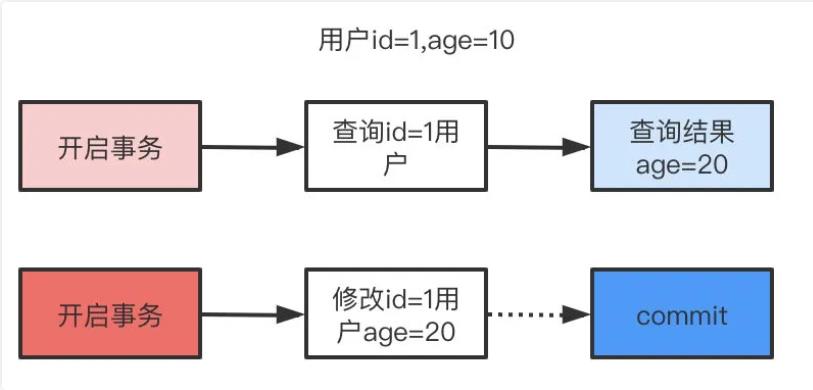
(1)读未提交(Read Uncommitted)
读未提交,顾名思义,就是一个事务可以读取另一个未提交事务的数据。
读未提交可能会读到其他事务未提交的数据,也叫做脏读。用户本来应该读取到id=1的用户 age应该是10,结果读取到了其他事务还没有提交的事务,结果读取结果age=20,这就是脏读。
(2) 读已提交(Read Committed)
读已提交,顾名思义,就是一个事务要等另一个事务提交后才能读取数据。
读已提交解决了脏读的问题,他只会读取已经提交的事务。
事例:程序员拿着信用卡去享受生活(卡里当然是只有3.6万),当他埋单时(程序员事务开启),收费系统事先检测到他的卡里有3.6万,就在这个时候!程序员的妻子要把钱全部转出充当家用,并提交。当收费系统准备扣款时,再检测卡里的金额,发现已经没钱了(第二次检测金额当然要等待妻子转出金额事务提交完)。程序员就会很郁闷,明明卡里是有钱的…
分析:这就是读已提交,若有事务对数据进行更新(UPDATE)操作时,读操作事务要等待这个更新操作事务提交后才能读取数据,可以解决脏读问题。但在这个事例中,出现了一个事务范围内两个相同的查询却返回了不同数据,这就是不可重复读。
那怎么解决可能的不可重复读问题?Repeatable read !
(3) 可重复读(Repeatable Read)
可重复复读就是在开始读取数据(事务开启)时,不再允许修改操作。可以解决不可重复读问题,但是可能出现幻读。
可重复复读是Mysql的默认事务隔离级别,就是每次读取结果都一样,但是有可能产生幻读。
事例:程序员拿着信用卡去享受生活(卡里当然是只有3.6万),当他埋单时(事务开启,不允许其他事务的UPDATE修改操作),收费系统事先检测到他的卡里有3.6万。这个时候他的妻子不能转出金额了。接下来收费系统就可以扣款了。
分析:重复读可以解决不可重复读问题。写到这里,应该明白的一点就是,不可重复读对应的是修改,即UPDATE操作。但是可能还会有幻读问题。因为幻读问题对应的是插入INSERT操作,而不是UPDATE操作。
什么时候会出现幻读?
事例:程序员某一天去消费,花了2千元,然后他的妻子去查看他今天的消费记录(全表扫描FTS,妻子事务开启),看到确实是花了2千元,就在这个时候,程序员花了1万买了一部电脑,即新增INSERT了一条消费记录,并提交。当妻子打印程序员的消费记录清单时(妻子事务提交),发现花了1.2万元,似乎出现了幻觉,这就是幻读。
(4) 串行化(Serializable)
Serializable 是最高的事务隔离级别,在该级别下,事务串行化顺序执行,可以避免脏读、不可重复读与幻读。但是这种事务隔离级别效率低下,比较耗数据库性能,一般不使用。
串行,一般是不会使用的,他会给每一行读取的数据加锁,会导致大量超时和锁竞争的问题。\\
8、什么是幻读,脏读,不可重复读呢?Innodb是怎么解决幻读问题的?
(1) 什么是幻读,脏读,不可重复读呢?
事务A、B交替执行,事务A被事务B干扰到了,因为事务A读取到事务B未提交的数据,这就是脏读。
在一个事务范围内,两个相同的查询,读取同一条记录,却返回了不同的数据,这就是不可重复读。
事务A查询一个范围的结果集,另一个并发事务B往这个范围中插入/删除了数据,并静悄悄地提交,然后事务A再次查询相同的范围,两次读取得到的结果集不一样了,这就是幻读。
(2) Innodb是怎么解决幻读问题的?
在上面的事务隔离级别介绍中,我们了解到不同的事务隔离级别会引发不同的问题,如在 RR 级别下会出现幻读。但如果将存储引擎选为 InnoDB ,在 RR 级别下,幻读的问题就会被解决。
InnoDB 为了在 RR 级别上解决该问题,引入了间隙锁,虽然解决了幻读的问题,但间隙锁会降低并发率,增加死锁情况的发生。而 next-key lock 其实就是行锁(Record Lock)和间隙锁的合集。
在业务不需要 RR 支持下,如果想提高并发率,可以将隔离级别设置成 RC 并将 binlog 格式设置成 row。
行锁锁住的是存在的记录行,间隙锁锁住的是行之间的空隙。而 next-key lock 锁住的是两者之和,比如 select * from t for update 锁住的就是 (-∞,0]、(0,5]、(5,10]、(10,15]、(15,20]、(20, 25]、(25, +supremum]。
(-∞,0],由间隙锁 (-∞,0]) 和行锁 0 组成,其他类似。
+supremum 表示 InnoDB 给每个索引加了一个不存在的最大值。
推荐阅读:幻读在 InnoDB 中是被如何解决的?
9、那事务ACID特性靠什么保证的呢?
A原子性由undo log日志保证,它记录了需要回滚的日志信息,事务回滚时撤销已经执行成功的sql
C一致性一般由代码层面来保证
I隔离性由MVCC来保证
D持久性由内存+redo log来保证,mysql修改数据同时在内存和redo log记录这次操作,事务提交的时候通过redo log刷盘,宕机的时候可以从redo log恢复
10、redo log,undo log,binlog的区别是什么?
(1)重做日志(redo log)作用
确保事务的持久性。防止在发生故障的时间点,尚有脏页未写入磁盘,在重启mysql服务的时候,根据redo log进行重做,从而达到事务的持久性这一特性。
(2)回滚日志(undo log)作用
确保事务的原子性。保存了事务发生之前的数据的一个版本,可以用于回滚,同时可以提供多版本并发控制下的读(MVCC),也即非锁定读
(3)二进制日志(binlog)作用
用于复制,在主从复制中,从库利用主库上的binlog进行重播,实现主从同步。
用于数据库的基于时间点的还原。
11、 那你知道什么是覆盖索引和回表吗?
覆盖索引指的是在一次查询中,如果一个索引包含或者说覆盖所有需要查询的字段的值,我们就称之为覆盖索引,而不再需要回表查询。
而要确定一个查询是否是覆盖索引,我们只需要explain sql语句看Extra的结果是否是“Using index”就能够触发索引覆盖。
12、聚集索引与非聚集索引的区别
可以按以下四个维度回答:
(1)一个表中只能拥有一个聚集索引,而非聚集索引一个表可以存在多个。
(2)如果表定义了PK,则PK就是聚集索引;如果表没有定义PK,则第一个not NULL unique列是聚集索引;否则,InnoDB会创建一个隐藏的row-id作为聚集索引
(3)我们可以这么理解聚簇索引:索引的叶节点就是数据节点。而非聚簇索引的叶节点不存放具体的整行数据(叶子结点不直接指向数据页),而是存储的这一行的主键的值。
(4)非聚集索引需要回表查询,先定位主键值,再定位行记录,因为要扫描两遍索引树,它的性能较扫一遍索引树更低。
13、为什么要用 B+ 树,为什么不用普通二叉树?
可以从几个维度去看这个问题,查询是否够快,效率是否稳定,存储数据多少,以及查找磁盘次数,为什么不是普通二叉树,为什么不是平衡二叉树,为什么不是B树,而偏偏是 B+ 树呢?
(1)为什么不是普通二叉树?
如果二叉树特殊化为一个链表,相当于全表扫描。平衡二叉树相比于二叉查找树来说,查找效率更稳定,总体的查找速度也更快。
(2)为什么不是平衡二叉树呢?
我们知道,在内存比在磁盘的数据,查询效率快得多。如果树这种数据结构作为索引,那我们每查找一次数据就需要从磁盘中读取一个节点,也就是我们说的一个磁盘块,但是平衡二叉树可是每个节点只存储一个键值和数据的,如果是B树,可以存储更多的节点数据,树的高度也会降低,因此读取磁盘的次数就降下来啦,查询效率就快啦。
(3)为什么不是 B 树而是 B+ 树呢?
B+ 树非叶子节点上是不存储数据的,仅存储键值,而B树节点中不仅存储键值,也会存储数据。innodb中页的默认大小是16KB,如果不存储数据,那么就会存储更多的键值,相应的树的阶数(节点的子节点树)就会更大,树就会更矮更胖,如此一来我们查找数据进行磁盘的IO次数有会再次减少,数据查询的效率也会更快。
B+ 树索引的所有数据均存储在叶子节点,而且数据是按照顺序排列的,链表连着的。那么 B+ 树使得范围查找,排序查找,分组查找以及去重查找变得异常简单。
14、锁的类型有哪些呢?说说数据库的乐观锁和悲观锁是什么以及它们的区别?MVCC 熟悉吗,知道它的底层原理?
(1)锁的类型有哪些呢?
mysql锁分为共享锁和排他锁,也叫做读锁和写锁。
读锁是共享的,可以通过lock in share mode实现,这时候只能读不能写。
写锁是排他的,它会阻塞其他的写锁和读锁。从颗粒度来区分,可以分为表锁和行锁两种。
表锁会锁定整张表并且阻塞其他用户对该表的所有读写操作,比如alter修改表结构的时候会锁表。
行锁又可以分为乐观锁和悲观锁,悲观锁可以通过for update实现,乐观锁则通过版本号实现。
(2) 说说数据库的乐观锁和悲观锁是什么以及它们的区别?
悲观锁:
悲观锁她专一且缺乏安全感了,她的心只属于当前事务,每时每刻都担心着它心爱的数据可能被别的事务修改,所以一个事务拥有(获得)悲观锁后,其他任何事务都不能对数据进行修改啦,只能等待锁被释放才可以执行。
乐观锁:
乐观锁的“乐观情绪”体现在,它认为数据的变动不会太频繁。因此,它允许多个事务同时对数据进行变动。
实现方式:乐观锁一般会使用版本号机制或CAS算法实现。
(3) MVCC 熟悉吗,知道它的底层原理?
MVCC (Multiversion Concurrency Control),即多版本并发控制技术。
MVCC在MySQL InnoDB中的实现主要是为了提高数据库并发性能,用更好的方式去处理读-写冲突,做到即使有读写冲突时,也能做到不加锁,非阻塞并发读。
15 、 那你说说什么是幻读,什么是MVCC?
要说幻读,首先要了解MVCC,MVCC叫做多版本并发控制,实际上就是保存了数据在某个时间节点的快照。
我们每行数实际上隐藏了两列,创建时间版本号,过期(删除)时间版本号,每开始一个新的事务,版本号都会自动递增。
假设我们有张user表,结构如下:
create table user(
id int(11) not null,
age int(11) not null,
primary key(id),
key(age)
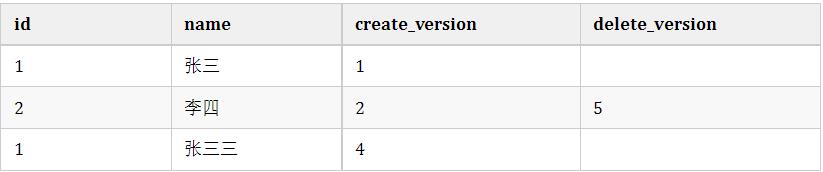
);假设我们插入两条数据,他们实际上应该长这样。
 这时候假设小明去执行查询,此时current_version=3
这时候假设小明去执行查询,此时current_version=3
select * from user where id<=3;同时,小红在这时候开启事务去修改id=1的记录,current_version=4
update user set name='张三三' where id=1;执行成功后的结果是这样的

如果这时候还有小黑在删除id=2的数据,current_version=5,执行后结果是这样的。
 由于MVCC的原理是查找创建版本小于或等于当前事务版本,删除版本为空或者大于当前事务版本,小明的真实的查询应该是这样
由于MVCC的原理是查找创建版本小于或等于当前事务版本,删除版本为空或者大于当前事务版本,小明的真实的查询应该是这样
select * from user where id<=3 and create_version<=3 and (delete_version>3 or delete_version is null);所以小明最后查询到的id=1的名字还是'张三',并且id=2的记录也能查询到。这样做是为了保证事务读取的数据是在事务开始前就已经存在的,要么是事务自己插入或者修改的。
明白MVCC原理,我们来说什么是幻读就简单多了。举一个常见的场景,用户注册时,我们先查询用户名是否存在,不存在就插入,假定用户名是唯一索引。
-
小明开启事务current_version=6查询名字为'王五'的记录,发现不存在。
-
小红开启事务current_version=7插入一条数据,结果是这样:
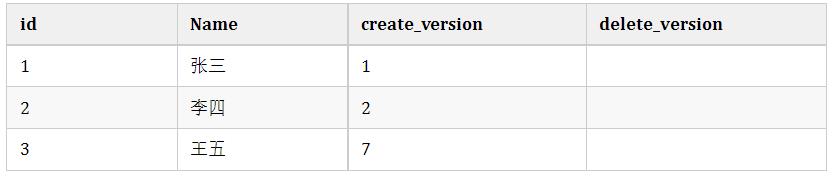 小明执行插入名字'王五'的记录,发现唯一索引冲突,无法插入,这就是幻读。
小明执行插入名字'王五'的记录,发现唯一索引冲突,无法插入,这就是幻读。
16、那你知道什么是间隙锁吗?
间隙锁是可重复读级别下才会有的锁,结合MVCC和间隙锁可以解决幻读的问题。我们还是以user举例,假设现在user表有几条记录
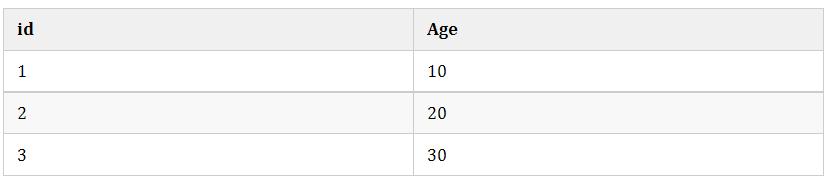
当我们执行:
begin;
select * from user where age=20 for update;
begin;
insert into user(age) values(10); #成功
insert into user(age) values(11); #失败
insert into user(age) values(20); #失败
insert into user(age) values(21); #失败
insert into user(age) values(30); #失败只有10可以插入成功,那么因为表的间隙mysql自动帮我们生成了区间(左开右闭)
(negative infinity,10],(10,20],(20,30],(30,positive infinity)
由于20存在记录,所以(10,20],(20,30]区间都被锁定了无法插入、删除。
如果查询21呢?就会根据21定位到(20,30)的区间(都是开区间)。
需要注意的是唯一索引是不会有间隙索引的。
17、说说mysql主从同步怎么做的吧
首先先了解mysql主从同步的原理
-
master提交完事务后,写入binlog
-
slave连接到master,获取binlog
-
master创建dump线程,推送binglog到slave
-
slave启动一个IO线程读取同步过来的master的binlog,记录到relay log中继日志中
-
slave再开启一个sql线程读取relay log事件并在slave执行,完成同步
-
slave记录自己的binglog
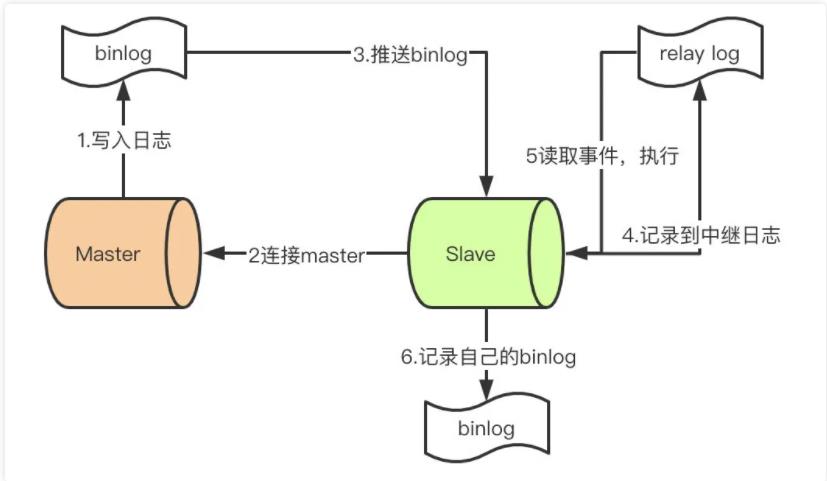
由于mysql默认的复制方式是异步的,主库把日志发送给从库后不关心从库是否已经处理,这样会产生一个问题就是假设主库挂了,从库处理失败了,这时候从库升为主库后,日志就丢失了。由此产生两个概念。
全同步复制
主库写入binlog后强制同步日志到从库,所有的从库都执行完成后才返回给客户端,但是很显然这个方式的话性能会受到严重影响。
半同步复制
和全同步不同的是,半同步复制的逻辑是这样,从库写入日志成功后返回ACK确认给主库,主库收到至少一个从库的确认就认为写操作完成。
18、日常工作中你是怎么优化SQL的?
可以从这几个维度回答这个问题:
(1) 优化表结构
(1)尽量使用数字型字段
若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
(2)尽可能的使用 varchar 代替 char
变长字段存储空间小,可以节省存储空间。
(3)当索引列大量重复数据时,可以把索引删除掉
比如有一列是性别,几乎只有男、女、未知,这样的索引是无效的。
(2) 优化查询
-
应尽量避免在 where 子句中使用!=或<>操作符
-
应尽量避免在 where 子句中使用 or 来连接条件
-
任何查询也不要出现select *
-
避免在 where 子句中对字段进行 null 值判断
(3) 索引优化
-
对作为查询条件和 order by的字段建立索引
-
避免建立过多的索引,多使用组合索引
19、关心过业务系统里面的sql耗时吗?统计过慢查询吗?对慢查询都怎么优化过?
我们平时写Sql时,都要养成用explain分析的习惯。慢查询的统计,运维会定期统计给我们
优化慢查询思路:
-
分析语句,是否加载了不必要的字段/数据
-
分析 SQL 执行句话,是否命中索引等
-
如果 SQL 很复杂,优化 SQL 结构
-
如果表数据量太大,考虑分表
20、如果让你做分库与分表的设计,简单说说你会怎么做?
分库分表方案:
-
水平分库:以字段为依据,按照一定策略(hash、range等),将一个库中的数据拆分到多个库中。
-
水平分表:以字段为依据,按照一定策略(hash、range等),将一个表中的数据拆分到多个表中。
-
垂直分库:以表为依据,按照业务归属不同,将不同的表拆分到不同的库中。
-
垂直分表:以字段为依据,按照字段的活跃性,将表中字段拆到不同的表(主表和扩展表)中。
常用的分库分表中间件:
-
sharding-jdbc
-
Mycat
分库分表可能遇到的问题
-
事务问题:需要用分布式事务啦
-
跨节点Join的问题:解决这一问题可以分两次查询实现
-
跨节点的count,order by,group by以及聚合函数问题:分别在各个节点上得到结果后在应用程序端进行合并。
-
数据迁移,容量规划,扩容等问题
-
ID问题:数据库被切分后,不能再依赖数据库自身的主键生成机制啦,最简单可以考虑UUID
-
跨分片的排序分页问题
21、你们数据量级多大?分库分表怎么做的?
首先分库分表分为垂直和水平两个方式,一般来说我们拆分的顺序是先垂直后水平。
垂直分库
基于现在微服务拆分来说,都是已经做到了垂直分库了

垂直分表
如果表字段比较多,将不常用的、数据较大的等等做拆分
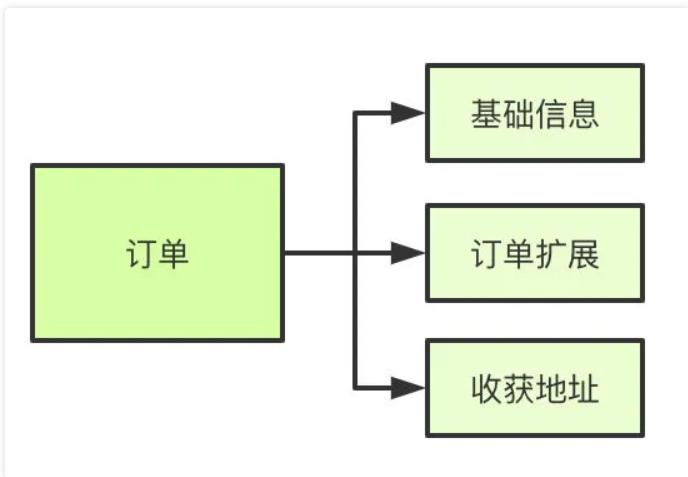
水平分表
首先根据业务场景来决定使用什么字段作为分表字段(sharding_key),比如我们现在日订单1000万,我们大部分的场景来源于C端,我们可以用user_id作为sharding_key,数据查询支持到最近3个月的订单,超过3个月的做归档处理,那么3个月的数据量就是9亿,可以分1024张表,那么每张表的数据大概就在100万左右。
比如用户id为100,那我们都经过hash(100),然后对1024取模,就可以落到对应的表上了。
22、那分表后的ID怎么保证唯一性的呢?
因为我们主键默认都是自增的,那么分表之后的主键在不同表就肯定会有冲突了。有几个办法考虑:
-
设定步长,比如1-1024张表我们设定1024的基础步长,这样主键落到不同的表就不会冲突了。
-
分布式ID,自己实现一套分布式ID生成算法或者使用开源的比如雪花算法这种
-
分表后不使用主键作为查询依据,而是每张表单独新增一个字段作为唯一主键使用,比如订单表订单号是唯一的,不管最终落在哪张表都基于订单号作为查询依据,更新也一样。
23、MySQL数据库cpu飙升的话,要怎么处理呢?
排查过程:
(1)使用top 命令观察,确定是mysqld导致还是其他原因。(2)如果是mysqld导致的,show processlist,查看session情况,确定是不是有消耗资源的sql在运行。(3)找出消耗高的 sql,看看执行计划是否准确, 索引是否缺失,数据量是否太大。
处理:
(1)kill 掉这些线程(同时观察 cpu 使用率是否下降), (2)进行相应的调整(比如说加索引、改 sql、改内存参数) (3)重新跑这些 SQL。
其他情况:
也有可能是每个 sql 消耗资源并不多,但是突然之间,有大量的 session 连进来导致 cpu 飙升,这种情况就需要跟应用一起来分析为何连接数会激增,再做出相应的调整,比如说限制连接数等
24、MySQL 遇到过死锁问题吗,你是如何解决的?(重点去了解一下,好跟面试官造火箭)
遇到过。我排查死锁的一般步骤是酱紫的:
(1)查看死锁日志 show engine innodb status;
(2)找出死锁Sql
(3)分析sql加锁情况
(4)模拟死锁案发
(5)分析死锁日志
(6)分析死锁结果
参考链接:
以上是关于MySQL面试夺命连环24问的主要内容,如果未能解决你的问题,请参考以下文章