CamVid数据集(智能驾驶场景的语义分割)
Posted 一颗小树x
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CamVid数据集(智能驾驶场景的语义分割)相关的知识,希望对你有一定的参考价值。
前言
CamVid 数据集是由剑桥大学公开发布的城市道路场景的数据集。CamVid全称:The Cambridge-driving Labeled Video Database,它是第一个具有目标类别语义标签的视频集合。
数据集包 括 700 多张精准标注的图片用于强监督学习,可分为训练集、验证集、测试集。同时, 在 CamVid 数据集中通常使用 11 种常用的类别来进行分割精度的评估,分别为:道路 (Road)、交通标志(Symbol)、汽车(Car)、天空(Sky)、行人道(Sidewalk)、电线杆 (Pole)、围墙(Fence)、行人(Pedestrian)、建筑物(Building)、自行车(Bicyclist)、 树木(Tree)。
目录
一、简介
CamVid数据集提供32个ground truth语义标签,将每个像素与语义类别之一相关联。该数据集解决了对实验数据的需求,以定量评估新兴算法。数据是从驾驶汽车的角度拍摄的,驾驶场景增加了观察目标的数量和异质性。
官网:http://mi.eng.cam.ac.uk/research/projects/VideoRec/CamVid/

二、精准标注示例
示例1:

示例2:

示例3:

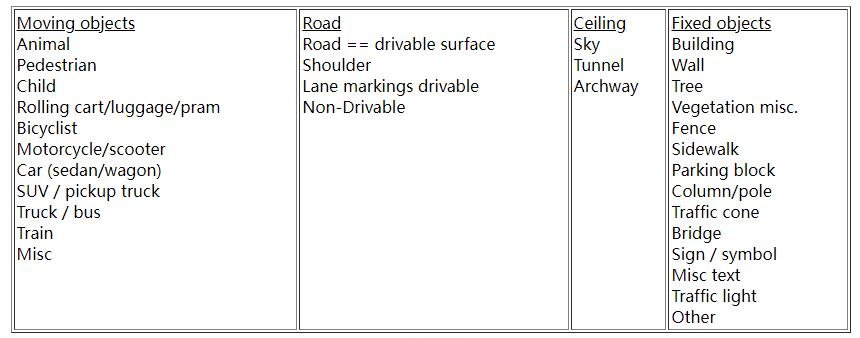
三、类别定义
类别标签链接:http://mi.eng.cam.ac.uk/research/projects/VideoRec/CamVid/#ClassLabels

下面是几个大类别,进行细分的各个小类别:
使用该数据,进行引用:
| (1) | Segmentation and Recognition Using Structure from Motion Point Clouds, ECCV 2008 (pdf) Brostow, Shotton, Fauqueur, Cipolla (bibtex) | ||
| (2) | Semantic Object Classes in Video: A High-Definition Ground Truth Database (pdf) Pattern Recognition Letters (to appear) Brostow, Fauqueur, Cipolla (bibtex) |
四、下载数据集
官网下载地址:Object Recognition in Video Dataset
我上传到了网盘,或者大家到这里下载:
链接:https://pan.baidu.com/s/1E50QplXMcZISlFV5RN4CLg
提取码:1024
本文直供大家参考和学习,谢谢。
以上是关于CamVid数据集(智能驾驶场景的语义分割)的主要内容,如果未能解决你的问题,请参考以下文章
MATLAB深度学习采用 Deeplab v3+ 实现全景分割