大数据Spark MLlib基于模型的协同过滤
Posted 赵广陆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据Spark MLlib基于模型的协同过滤相关的知识,希望对你有一定的参考价值。
目录
1 简介
在大数据Spark MLlib推荐算法这篇文章中涉及到拆分,至于为什么拆分没有详解接下来写一下如何来构建模型.
基于模型的协同过滤推荐,就是基于样本的用户偏好信息,训练一个推荐模型,然后根据实时的用户喜好的信息进行预测新物品的得分,计算推荐
基于近邻的推荐和基于模型的推荐
- 基于近邻的推荐是在预测时直接使用已有的用户偏好数据,通过近邻数据来预测对新物品的偏好
(类似分类) - 而基于模型的方法,是要使用这些偏好数据来训练模型,找到内在规律,再用模型来做预测(类
似回归)
■ 训练模型时,可以基于标签内容来提取物品特征,也可以让模型去发掘物品的
潜在特征;这样的模型被称为隐语义模型(Latent Factor Model, LFM)
2 隐语义模型(LFM)
用隐语义模型来进行协同过滤的目标
- 揭示隐藏的特征,这些特征能够解释为什么给出对应的预测评分
- 这类特征可能是无法直接用语言解释描述的,事实上我们并不需要知道,类似“玄学”
通过矩阵分解进行降维分析
- 协同过滤算法非常依赖历史数据,而一般的推荐系统中,偏好数据又往往是稀疏的;这就需要
对原始数据做降维处理 - 分解之后的矩阵,就代表了用户和物品的隐藏特征
隐语义模型的实例
- 基于概率的隐语义分析(pLSA)
- 隐式迪利克雷分布模型(LDA)
- 矩阵因子分解模型(基于奇异值分解的模型,SVD)
3 LFM 降维方法 —— 矩阵因子分解
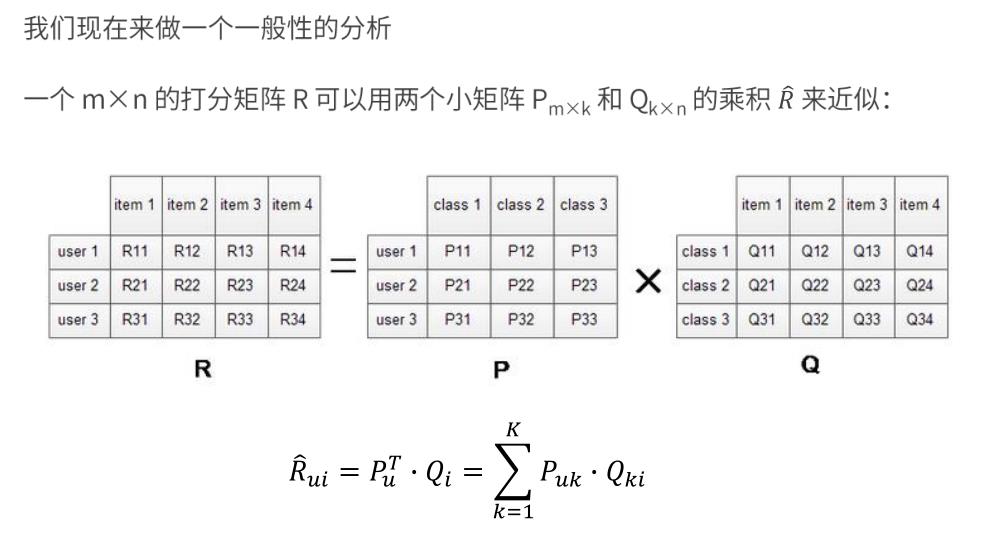
- 假设用户物品评分矩阵为 R, 现在有 m 个用户, n 个物品
- 我们想要发现 k 个隐类,我们的任务就是找到两个矩阵 P 和 Q, 使这两个矩阵的乘积
近似等于 R, 即将用户物品评分矩阵 R 分解成为两个低维矩阵相乘:


3.1 矩阵因子分解

3.2 矩阵因子分解计算

4 LFM 的进一步理解
我们可以认为,用户之所以给电影打出这样的分数,是有内在原因的,我们可以挖掘出影响用户打分的隐藏因素,进而根据未评分电影与这些隐藏因素的关联度,决定此未评分电影的预测评分
应该有一些隐藏的因素,影响用户的打分,比如电影:演员、题材、年代…甚至不一定是人直接可以理解的隐藏因子找到隐藏因子,可以对 user 和 item 进行关联(找到是由于什么使得 user 喜欢/不喜欢此 item, 什么会决定 user 喜欢/不喜欢此 item) , 就可以推测用户是否会喜欢某一部未看过的电影
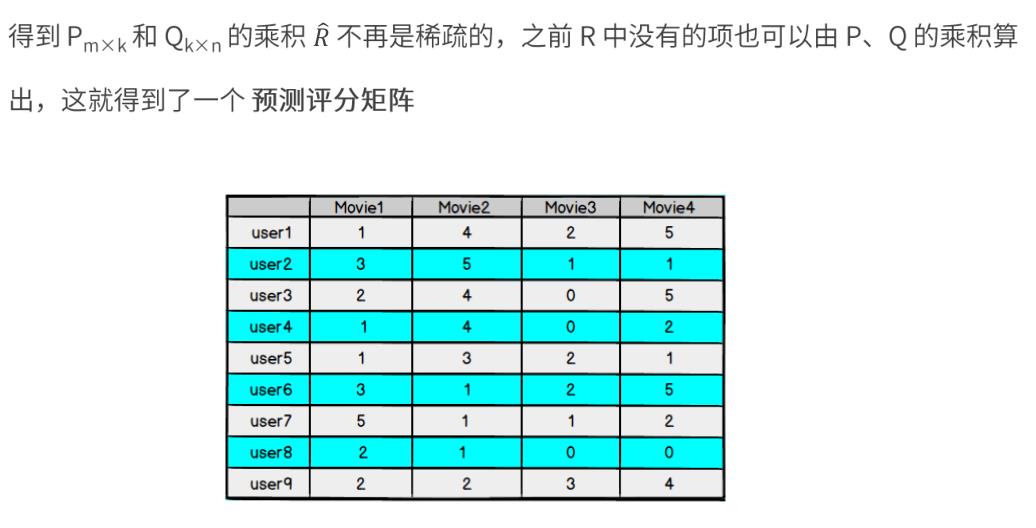
对于用户看过的电影,会有相应的打分,但一个用户不可能看过所有电影,对于用户没有看过的电影是没有评分的,因此用户评分矩阵大部分项都是空的,是一个稀疏矩阵

4.1 矩阵因子分解

5 模型的求解 —— 损失函数

以上是关于大数据Spark MLlib基于模型的协同过滤的主要内容,如果未能解决你的问题,请参考以下文章