IO流学习笔记
Posted z啵唧啵唧
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了IO流学习笔记相关的知识,希望对你有一定的参考价值。
文章目录
IO流,什么是IO
-
I:Input
-
O:Output
通过IO可以完成硬盘文件的读和写。
IO流的分类
有多种方式分类:
- 按照流的方向进行分类
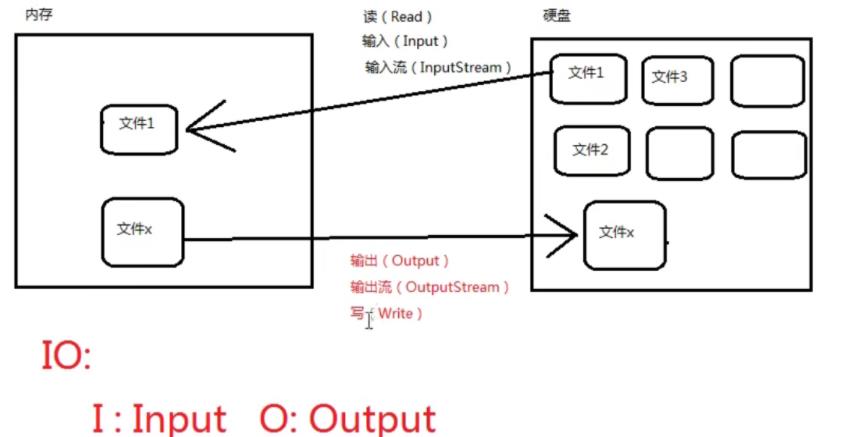
以内存作为参照物,往内存中去叫做输入(Input)或者叫做读(Read)
从内存当中取出来叫做输出(Output),或者叫做写(Write)
- 按照读取数据的方式进行分类
1.有的流是按照字节的方式去读取数据,一次读取一个字节,等同于一次读取8个二进制位,这种流是万能的,什么类型的文件都可以读取,包括:文本文件,图片,声音文件,视屏文件
2.还有的流是按照字符的方式去读取数据,一次读取一个字符,这种流是为了方面读取普通文本文件而存在的,这种流不能够读取:图片、声音、视频,只能够读取文本文件,连world文件也不能读取。
java io的四大家族
-
java.io.InputStream 字节输出流
-
java.io.OutputStream字节输入流
-
java.io.Reader字符输入流
-
java.io.Writer字符输出流
所有的流都实现了:java.io.Closeable接口,他们都是可以关闭的,都有Close方法,因为流是一个管道,是内存和硬盘之间的通道,用完之后一定要关闭,不然会占用很多的资源。
所有的输出流都实现了:java.io.Flushable接口,都是可以刷新的,都有这个flush方法,输出流在最终输出之后一定要记得刷新一下,这个刷新表示将管道的中剩余没有输出的资源强行输出完(清空管道),注意如果没有执行flush可能会造成资源丢失。
注意:在java中只要是以Stream结尾的都是字节流,以“Reader,Writer”结尾的都是字符流。
需要掌握的十六个流
- 文件专属
java.io.FileInputStream
java.io.FileOutputStream
java.io.FileReader
java.io.FileWriter
- 缓冲流专属的
java.io.BufferdReader
java.io.BufferdWriter
java.io.BufferdInputStream
java.io.BufferdOutputStream
- 数据流专属的
java.io.DataInputStream
java.io.DataOutputStream
- 转换流专属(将字节流转换成字符流)
java.io.InputStreamReader
java.io.OutputStreamWriter
- 对象专属流
java.io.ObjectInputStream
java.io.ObjectOutputStream
- 标准输出流
java.io.PrintWriter
java.io.PrintReader
FileInputStream(从文件中读)
通过FileInputStream来读取txt文件
- 先在C:\\Users\\zhengbo目录下t新建一个FileInput.txt文件
- 在java中通过获取输出流调用read方法来读取我们的文件
- read方法每执行一步就会向后访问一个字节,当访问完毕没有了时,read返回-1
- 输出的是对应字符的ascll码值
package com.zb.test;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
/**
* @Author 啵儿
* @Email 1142172229@qq.com
* @date 2021/10/23 15:58
**/
public class TestDemo2 {
public static void main(String[] args) {
//1.先获取一个输出流
FileInputStream file = null;
try {
//2.创建输入流对象,传出文件路径
file = new FileInputStream("C:\\\\Users\\\\zhengbo\\\\FileInput.txt");
//3.调用读方法
int tag=0;
while((tag=file.read())!=-1)
{
System.out.println(tag);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally {
//4.在finally子句中关闭输入流
try {
if (file!=null)
{
file.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}

-
补充一个知识点idea中的默认路径是project的根
-
缺陷:这种通过调用read()方法来一个字节一个字节的读取的这种方法存一定的问题,因为这样每读取一个字节就会调用一次方法这样会使读取效率大大降低。
往byte数组中读
可以通过往指定大小的byte数组中读这样就可以避免一次只能够读取一个字节,提高读取的效率
package com.zb.test;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
/**
* @Author 啵儿
* @Email 1142172229@qq.com
* @date 2021/10/23 16:55
**/
public class TestDEmo3 {
public static void main(String[] args) {
FileInputStream file = null;
try {
file=new FileInputStream("src/com/zb/File/TestFile");
//new 一个byte数组
byte[] bytes =new byte[4];
//file.read(bytes)执行这个方法返回的是byte数组的长度
//第一次调用read方法
file.read(bytes);
System.out.println("调用read方法第一次读的结果:"+new String(bytes));
//第二次调用read方法
file.read(bytes);
System.out.println("调用read方法第二次读的结果:"+new String(bytes));
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally {
if(file!=null)
{
try {
file.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}

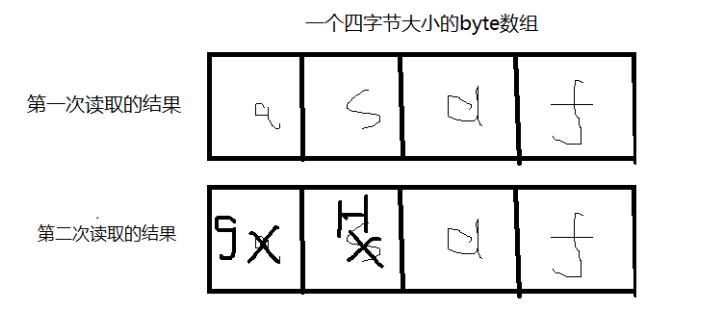
发现问题在第二次读取的时候我们想要的是gh结果可是,最终出来的是ghdf
-
改进
我们再读的时候可以给定输出的范围,我们每次读的时候可以只需要读从0开始一直到read()返回的数值即可。
int readCount = 0;//定义一个接受阅读字节数的变量
//第一次调用read方法
readCount = file.read(bytes);
//输出的时候输出从0到返回的字节数位置处
System.out.println("调用read方法第一次读的结果:"+new String(bytes,0,readCount));
//第二次调用read方法
readCount=file.read(bytes);
System.out.println("调用read方法第二次读的结果:"+new String(bytes,0,readCount));

- 再改进(采用循环的方式输出)
while(true)
{
readCount = file.read(bytes);
if(readCount!=-1)
{System.out.print(new String(bytes,0,readCount));}
else {
break;
}
}
- 这个循环的代码可以再改进为
int tag=0;
while((tag=file.read(bytes))!=-1)
{
System.out.print(new String(bytes,0,tag));
}
这样可以使代码更加简洁!
输出的结果为:

FileInputStream中一些其他的方法
- available(读取文件当中的总字节数)
这个方法的应用点:调用这个方法我们直接就可以知道文本文件的字节数,我们通过这个字节数直接一次读取全部的字节,就只需要读取一次就可以读取完,可以有效提高效率。(这个方法对于大文件不太适用)
package com.zb.test;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
/**
* @Author 啵儿
* @Email 1142172229@qq.com
* @date 2021/10/23 22:04
**/
public class Testdemo5 {
public static void main(String[] args) {
int count = 0;//定义一个变量用来接受总字节数
try {
FileInputStream file = new FileInputStream("src/com/zb/File/TestFile1");
count=file.available();
byte[] bytes = new byte[count];
int tag=0;
while((tag=file.read(bytes))!=-1)
{
System.out.print(new String(bytes,0,count));
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
只需要读取一次即可读出全部字节

- skip(跳过几个字节不读)
file.skip(2);//调用方法,采取跳过两个字节不读
System.out.println(file.read());//输出他的ASCII码值
原文本
结果(跳过了两个直接读取d的ASCII码值100)

FileOutputStream的使用(往文件中写)
获取FileOutputStream对象调用writer方法,向文件中写入数据
注意点:
- 我们在绑定文件地址时,如果原先不存在这个文件,那么在执行writer方法时,会自动先生成一个指定路径的文件
- 在进行写入操作时,在最后一定要记得刷新一下,并关闭释放资源。
package com.zb.test;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
/**
* @Author 啵儿
* @Email 1142172229@qq.com
* @date 2021/10/23 22:45
**/
public class TestDemo6 {
public static void main(String[] args) {
//1.获取一个FileOutputStream对象
FileOutputStream file = null;
//2.绑定文件地址
try {
file = new FileOutputStream("src/com/zb/File/TestFile3");
//将要写的数据存放在byte的数组中
byte[] bytes = {'z','h','e','n','g'};
//调用write方法写
file.write(bytes);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally {
if (file!=null)
{
//最后我们一定要记得去刷新一下我们的file
try {
file.flush();
file.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
程序完成之后在这里多了一个文件:
里面的内容为:
发现问题:
当我们再去存放一些数据时,发现写完后的文件内容变为了
//将要写的数据存放在byte的数组中
byte[] bytes = {'w','a','n'};
//调用write方法写
file.write(bytes);

所以:调用writer方法时,其实是先将文件当中的内容清空掉以后才写入新的数据,所以这个方法需要谨慎使用,不然可能会造成数据的丢失
解决方案:采用追加的方式向原文件中写入数据,具体实现的犯法是:再绑定文件的时候将append属性设置为true
//FileOutputStream有两个属性,一个是文件路径一个是append,设置为true就是再原文件后面最追加写入了
file = new FileOutputStream("src/com/zb/File/TestFile3",true);
测试
file = new FileOutputStream("src/com/zb/File/TestFile3",true);
byte[] bytes = {97,98,99};
file.write(bytes);
注明:这里存入的的97,98,99,其实是ASCII码值,会在文件中转换为对应的字符

这样就不回造成源数据丢失啦!
- 存入字符串,其本质还是将字符串转换成了字节数组byte[]
String str = "我是中国人我自豪";//创建一个字符串
byte[] bytes = str.getBytes();//调用getBytes方法,将字符串转换成字节数组
file.write(bytes);//写入数据
执行结果:

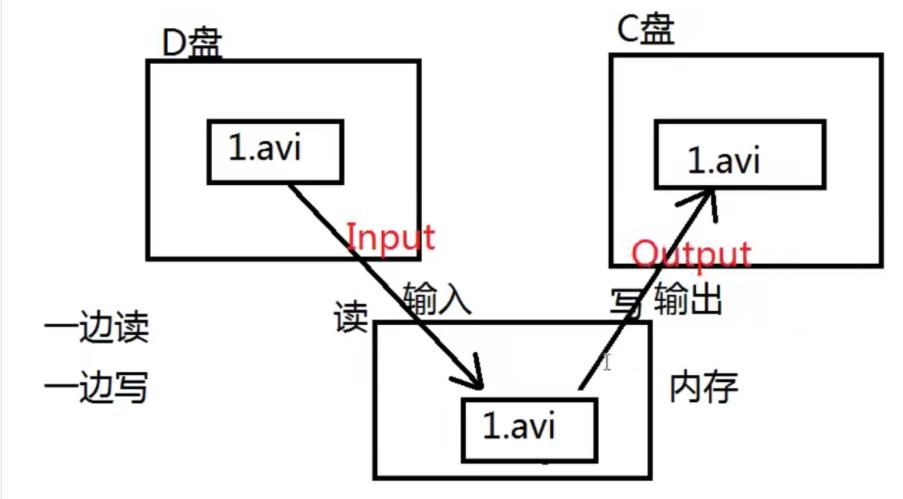
文件拷贝
文件拷贝原理:一边读一边写,原理和读写一样
package com.zb.test;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
/**
* @Author 啵儿
* @Email 1142172229@qq.com
* @date 2021/10/23 23:43
**/
public class TestDemo7 {
public static void main(String[] args) {
FileInputStream fis=null;
FileOutputStream fos = null;
try {
//fis绑定我们需要复制的文件,与就是我们要读的数据的文件
fis=new FileInputStream("C:\\\\Users\\\\zhengbo\\\\Documents\\\\" +
"WeChat Files\\\\wxid_rburdjipc9an22\\\\FileStorage" +
"\\\\Video\\\\2021-10\\\\舒克长胶.mp4");
//fos绑定我们要写入的文件名
fos=new FileOutputStream("C:\\\\test\\\\舒克长胶.mp4",true);
/*最核心的是一边读一边写*/
byte[] bytes = new byte[1024*1024];//一次最多读取1024*1024个字节也就是1M
int readcount=0;//定义一个变量用来接收读取的字节数
while ((readcount=fis.read(bytes))!=-1)
{
fos.write(bytes,0,readcount);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally {
if(fos!=null)
{
try {
fos.flush();
} catch (IOException e) {
e.printStackTrace();
}
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (fis!=null)
{
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
FileReader(字符输入流使用方法)
-
它只能够读文本文件,读文本文件比FileInputStream更加便捷有效
-
他和FileInputStream使用的方式差不多,只是在这里我们使用的是char[]数组来保存我们读的数据,其余流程基本相似。
package com.zb.test;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
/**
* @Author 啵儿
* @Email 1142172229@qq.com
* @date 2021/10/24 0:08
**/
public class TestDemo8 {
public static void main(String[] args) {
FileReader fr=null;
try {
fr=new FileReader("src/com/zb/File/TestFile3");
//和FireInputStream不同的是这里需要使用char[]数组来保存我们读出来的数据,因为这个叫做字符输入流
char[] chars = new char[4];
int readcount=0;
while ((readcount=fr.read(chars))!=-1)
{
System.out.print(new String(chars,0,readcount));
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if(fr!=null)
{
try {
fr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
原文件:

输出结果:

FileWriter(字符输出流)
- 字符输出流对文本文件的写操作更加便捷,而且方式更多
- 在操作普通文本文件的使用尽量使用FileReader/FileWriter会大大提高工作的效率
以上是关于IO流学习笔记的主要内容,如果未能解决你的问题,请参考以下文章