iOS 性能检测新方式——AnimationHitches
Posted 阿里巴巴淘系技术团队官网博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了iOS 性能检测新方式——AnimationHitches相关的知识,希望对你有一定的参考价值。

AnimationHitches 的运行原理
背景
在 Xcode12 中,Instrument 新增 AnimationHitches 检测类型用以检测卡顿,并去除 CoreAnimation 检测方式。在支持 PromotionDisplay 的设备上帧率可调整至 120 帧,并且会根据当前用户手势和设备状态进行动态调整。此时再继续使用帧率来判断性能的好坏及流畅度将会是一个错误的选择。所以 AnimationHitches 主要用于代替帧率检测,并且提出 卡顿时间比(Hitch Time Ratio) 的概念用于替代 FPS。由于目前关于 Hitch 相关的资料很少,而在 iPhone13Pro 之前 iPhone 屏幕最高刷新频率仍为 60 HZ,所以很多同学都还未关注到该能力。所以本篇将主要介绍 Hitch(卡顿) 的概念、RenderLoop(渲染循环) 的整体流程,卡顿类型及如何避免卡顿。
什么是卡顿?
▐ 概念
任何时候屏幕上出现晚于预计的帧都属于卡顿。

▐ 实例
例如 滚动动画(Scroll)、点击动画(Animation)、转场动画(Transition),这些流畅的动画构建了一种用户和屏幕内容的视觉连接感,而如果动画卡顿会导致动画画面跳跃,打破这种连接感,用户体验会变得很差。

一个常见的例子,当用户在操作一个滚动视图上下滚动时,发生了卡顿,这是因为第四帧的延迟导致了第三帧占用了两帧的时间,给用户看到的就是卡顿掉帧的现象。
RenderLoop
▐ 概念
RenderLoop 是一个连续的过程,通过用户手势等将事件传给 App,接着 App 向操作系统传递事件并最终响应事件,再将响应传递给用户的过程。
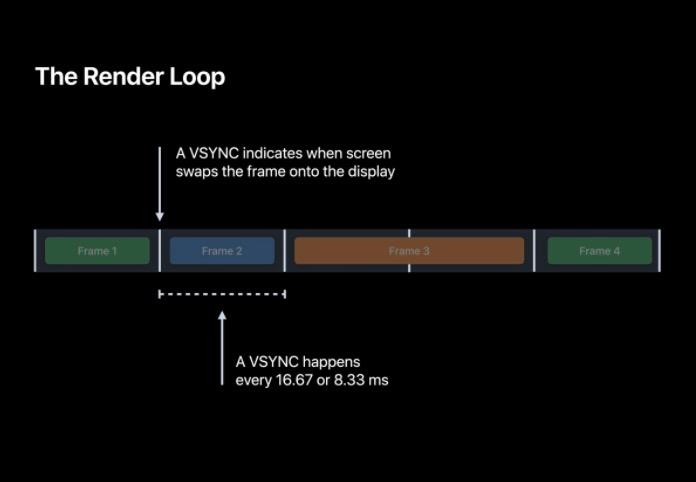
RenderLoop 的时间随着设备刷新频率,在 iPhone13 Pro(Max) 以下的 iPhone 设备最大均为 60 帧,而 iPhone13 Pro(Max) 及 iPadPro 则最高支持 120 帧,也就是最短仅需每 8.33 毫秒就可以显示一个新帧。
▐ 帧准备阶段
在准备每一帧的过程中,可以总体分为三个阶段。App、RenderServer 和 Display。其中 App 中主要进行一些用户事件的处理,而 RenderServer 会进行真正的用户界面绘制,这两个阶段都需要在下一个 VSNYC 到来前完成。最终到 Display 阶段会将缓冲的帧展示出来。对这一帧进行双帧处理我们把这称之为双缓冲,由于显示器是逐行扫描进行画面显示,双缓冲和垂直同步机制避免了屏幕撕裂的现象。
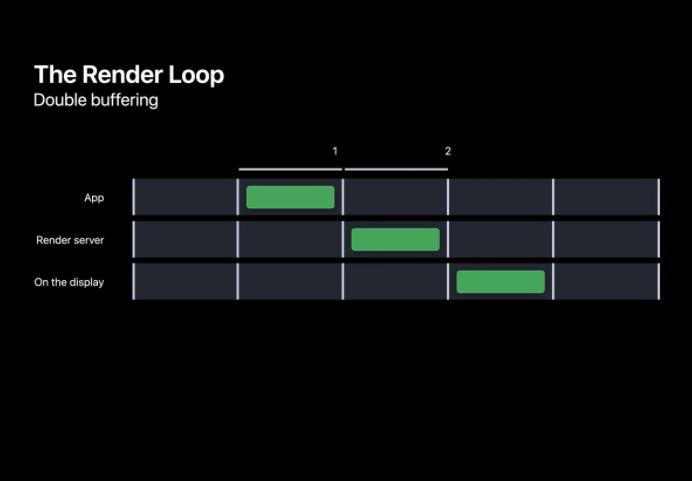
当然,系统也提供备用的三缓冲机制,为 RenderServer 提供额外的一帧进行渲染,该机制通常情况下不会开启。
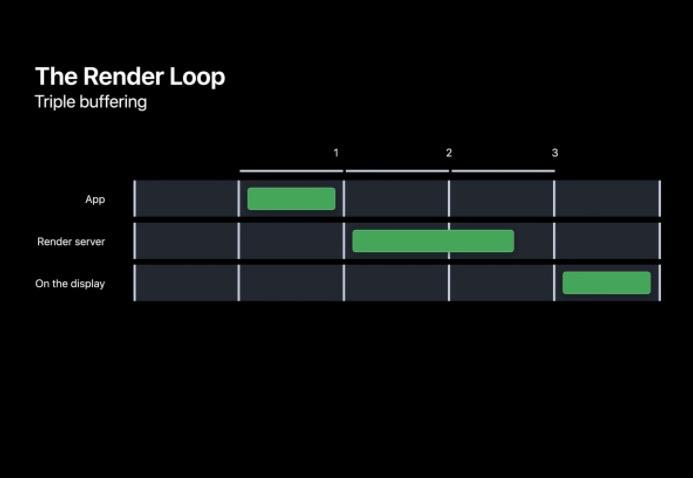
▐ 阶段细节
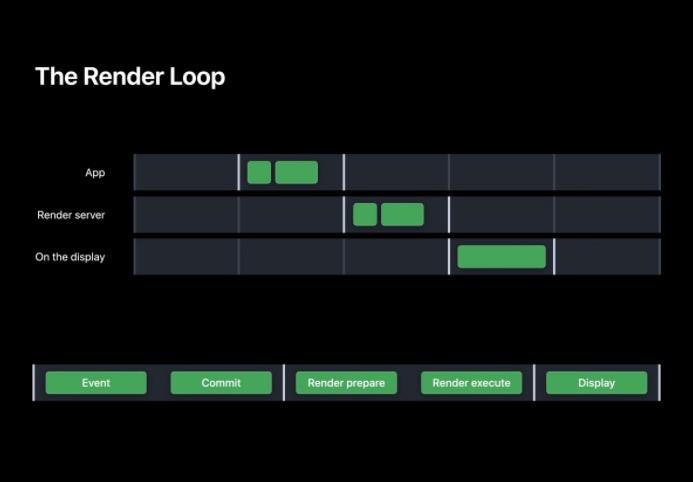
整个渲染循环可细分为 5 个阶段,其中在我们 App 中的为 Event,Commit 阶段,而 Commit 阶段可进一步细分为 Layout、Display、Prepare 和 Commit。
在事件阶段通过 touch,timer 等事件决定用户界面是否需要改变;
而在 Commit 阶段 App 会向渲染服务器 RenderServer 提交渲染命令;
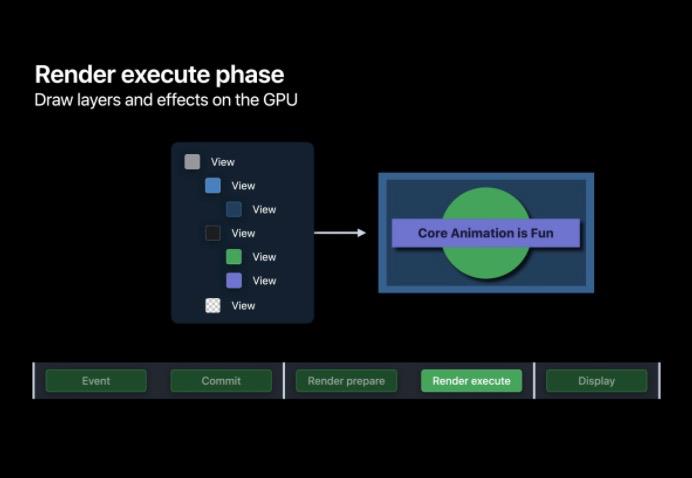
RenderServer 中的 Prepare,Execute 阶段,在 Prepare 阶段会为 GPU 的绘制做好准备,而在 Execute 阶段会由 GPU 将用户界面的图像绘制出来;
最后的 Display 阶段会将缓冲帧交换到屏幕上显示。
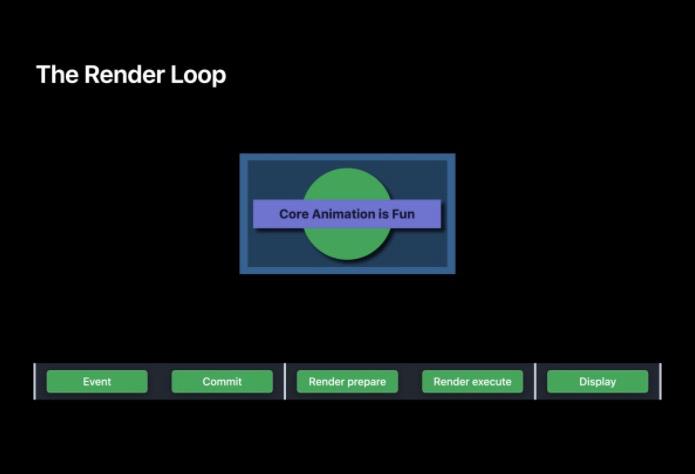
以一个带有阴影的渲染图形为例,观察下 RenderLoop 中每一帧所做的工作
App
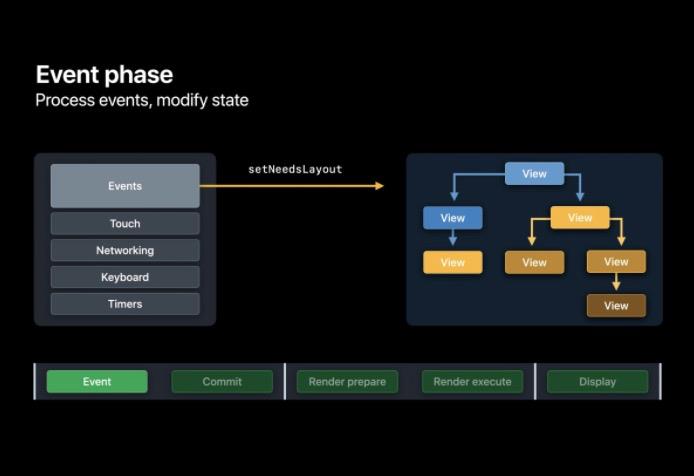
Event
在该阶段表示 App 接收到了事件,比如 touch 事件、网络请求回调、键盘和 Timer 。一个 App 可以通过改变其层级结构或是用任何其他方式响应这些事件。
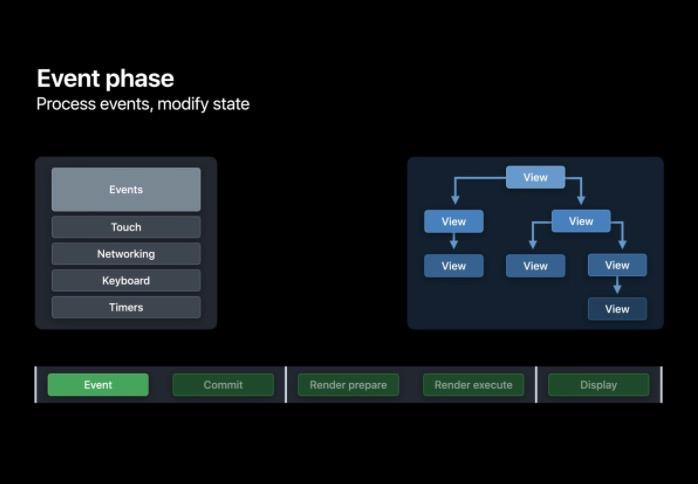
例如 App 能改变图层的背景颜色,甚至能改变图层的大小和位置。当 App 更新了图层的限制范围时, CoreAnimation 会同时会调用 setNeedsLayout。它能够分辨哪些图层必须要重新计算布局,系统会合并这些需要布局的请求并在 Commit 阶段按顺序执行,用以减少重复工作。
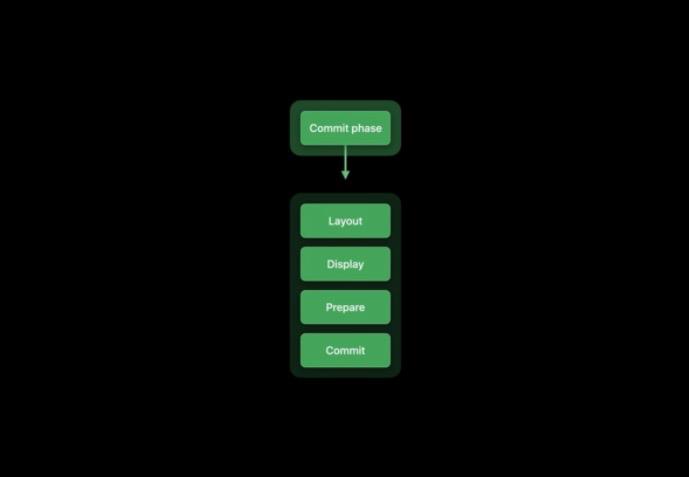
Commit
在一次事务的提交中共涉及四个不同的阶段:布局阶段、显示阶段、准备阶段和最后的提交阶段。
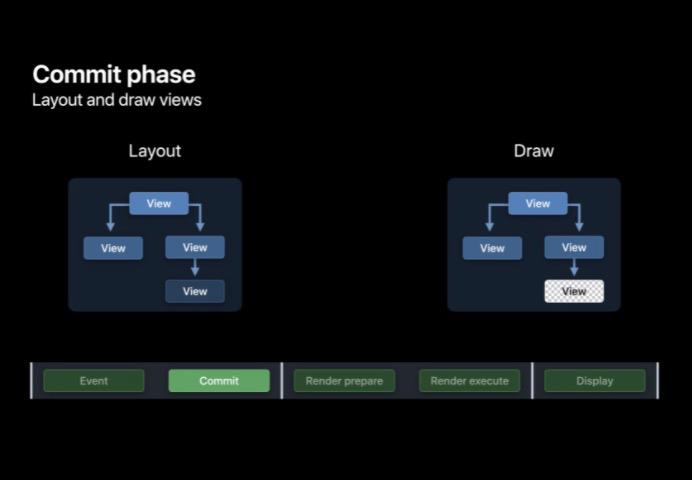
布局阶段
在布局阶段, layoutSubviews 会被所有需要布局的 View 调用。比如布局视图(frame、bounds、transform),增加或移除视图,亦或是直接调用 setNeedsLayout。注意这些布局操作并非立即执行,系统会合并这些布局请求,在 Runloop 休眠前统一执行这些操作。
显示阶段
在显示阶段,drawRect 会被每个需要被更新的 View 调用。比如 UILabel、UIImageView 或者只是任何重写 drawRect 方法的类。他们必须调用 setNeedsDisplay 用以支持 View 的更新。在绘制时每个自定义的绘图图层都会接收到带纹理的 CoreGraphics 的背景。他们将利用 CoreAnimation 进行绘制,这些图层就变成了图片。所以如果没有必要则不要重写 drawRect 方法,其不仅会额外开辟一块内存用以存储 bitmap,还会在 CPU 上进行绘制,增加了整体主线程时间占用,当自定义 drawRect 视图较多时,对整体的内存压力也比较大。
准备阶段
在 Prepare 阶段还没有解码的图像将会在这一步进行解码,也就是我们需要优化的常见的图片主线程解码操作。
对于每个被解码的图像, App 可能会持续存在大量的内存分配。这种内存分配与输入图像的大小成正比,而与 FrameBuffer 中实际渲染的图像视图的大小没有必然联系。当 App 占用越来越多的内存时,操作系统将会开始压缩物理内存(physical memory)。整个过程都需要 CPU 的参与,所以除了我们自己的 App 对 CPU 的使用外,还可能会增加无法控制的全局 CPU 使用率。最终,我们的 App 可能会消耗更多的物理内存,以至于操作系统需要启动终止进程,它将从低优先级的后台进程开始。如果我们的 App 对内存的消耗了达到了特定数量,可能会被终止,这也就是为什么经常会因为大图的原因产生 OOM。
若某个图像的颜色格式 GPU 无法直接使用,也会在这一步进行格式转换。这就要求对该图像进行 copy 操作,而不是直接使用指针,这样会耗时更长及占用更多的内存。
提交阶段
在提交阶段中,视图树将会被递归打包并发送到 RenderServer 中,所以当视图层级较为复杂时,这个过程耗费的时间也会更长一些,所以需要尽量减轻视图层级结构。
RenderServer
RenderServer 负责将我们的图层树转换为真正可显示的图像。RenderServer 有两个阶段:Prepare 和 Execute 。在 Prepare 阶段我们的图层树被编译成一系列简单的指令,供 GPU 执行,帧动画也在此处进行处理。在渲染执行阶段 GPU 将 App 的图层绘制成最终图像。

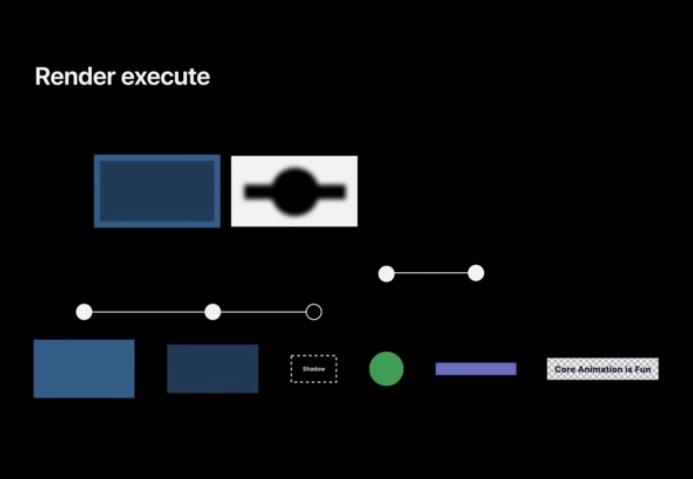
下面来一个渲染实例。在下面这个实例中,圆形和长条周围都有阴影。

Prepare
在准备阶段, RenderServer 会广度优先遍历 App 的图层树,准备一个线性管线,这样 GPU 就能按照顺序执行命令进行绘制。从根图层开始逐层遍历,最终才有了 GPU 可以在下一个执行阶段执行的整个管线。
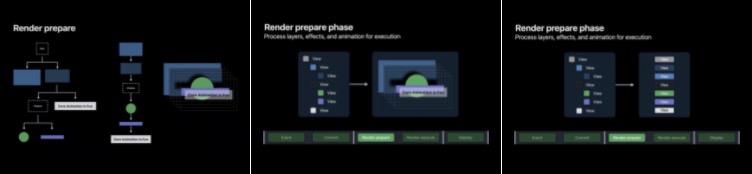
Execute
执行阶段主要是由 GPU 根据前面 prepare 阶段准备好的图层树进行顶点着色、形状装配、几何着色、光栅化、片段着色与图层混合。一旦 GPU 执行完会将渲染好的图像放入帧缓存区中等待下一个 VSYNC 的到来并交换到屏幕上进行显示。
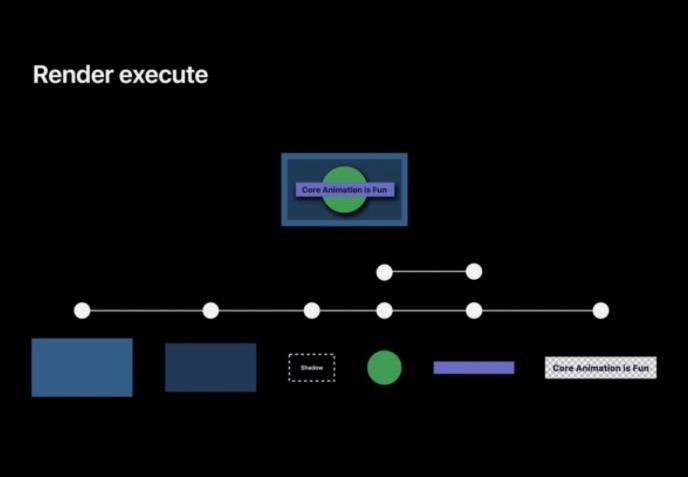
在该例中, GPU 的工作就是利用该管线将每一步都绘制成纹理并最终合成,最终在显示阶段会在屏幕上显示该纹理。
从第一个蓝色的图层开始,它在指定的边界内绘制颜色。然后深蓝色被绘制在其边界内,但是当前圆形和矩形中都有阴影,所以现在 GPU 必须先去绘制阴影。而阴影的形状由还未绘制的两层定义,所以需要先绘制圆形和矩形,为了避免这两图层被阴影遮挡,所以需要切换到不同的纹理先绘制阴影,对于这种情况我们称之为“离屏渲染”。在这里需要额外开辟一块内存用以绘制圆形和矩形,然后将该图层变为黑色并且模糊来实现阴影的效果。
然后 GPU 可以将阴影的离屏渲染纹理复制到最终的纹理中。阴影图层就完成了,下一步是再次绘制圆形和矩形。可以注意到的是,这里不仅开辟了一块额外的存储空间用以渲染阴影,圆形和矩形也被渲染了两次,对性能损害极大。
而最后的文本是在 CPU 上完成绘制的, GPU 会通过复制 CPU 绘制的文本图像来完成。完成上述流程后,帧已经准备好进行显示了。
需要注意在这个过程中我们不得不用离屏渲染来渲染阴影,导致渲染需要更长的时间。
离屏渲染
离屏渲染通道指的是 GPU 必须先在其它地方开辟一块内存进行图层渲染,然后再将其复制回来。就阴影而言,它必须绘制图层,以确定最终形状。

偶尔的离屏渲染对性能影响并不大,但离屏通道可能会积少成多,导致渲染出现卡顿。因此需要在 App 中监控并尽量避免。主要有四种主要类型的离屏通道可以优化:阴影、蒙版、圆角和毛玻璃。
Shadow:比如在实例中,如果不先绘制附加到图形上面的阴影,GPU 就没有足够的信息来绘制阴影。

Mask:当图层或图层树需要被遮蔽时,GPU 需要渲染被遮蔽的子树,它也需要避免覆盖被遮蔽形状外的像素。因此它只会把最终需要显示的像素复制回最终纹理,由于最终结果可能由多层渲染结果叠加,所以必须要利用额外的内存空间对中间的渲染结果进行缓存,因此系统会默认来触发离屏渲染,这种离屏渲染可能会导致渲染了许多用户永远不会看到的像素。

CornerRadius:由于 GPU 绘制时会先从根节点开始绘制,所以如果根节点上设置了圆角,并且设置了 maskToBounds 裁剪属性,那就会需要一个额外的离屏渲染 buffer 用以缓存中间的裁剪结果,并最终将圆角内的像素复制回来,组透明度等属性都可能会触发离屏渲染。

ios8 中开始支持 UIBlurEffectView 控件用以支持模糊化和鲜亮化,要应用这些效果,GPU 必须用离屏通道将内容复制到另一个纹理中,然后对其进行模糊、缩放叠加等操作并将最终结果复制回来。

Display
Display 的过程实际上就是将帧缓存区中的内容交换到显示器上进行最终显示,这一过程我们参与不多。
▐ 总结
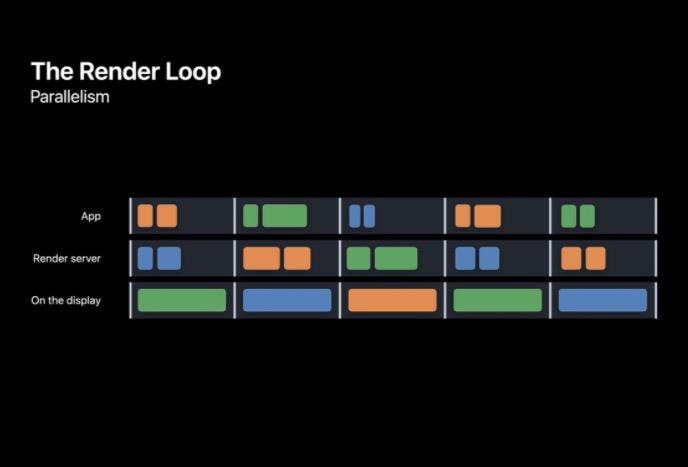
为了达到目标帧速率并且保持低输入延迟,RenderLoop 的整个过程实际上是在每一帧中并行进行的,这样管线就成了并行的。在系统渲染前一帧的同时 CPU 可以准备一个新帧,所以每帧的截止期都很重要。
卡顿类型
上面已经描述了 RenderLoop 的整个工作流程,实际上主要是在 App 和 RenderServer 中进行,所以总共有两种主要类型的卡顿:提交卡顿(发生在 App 中),渲染卡顿(发生在 RenderServer 中)。

▐ 提交卡顿
概念
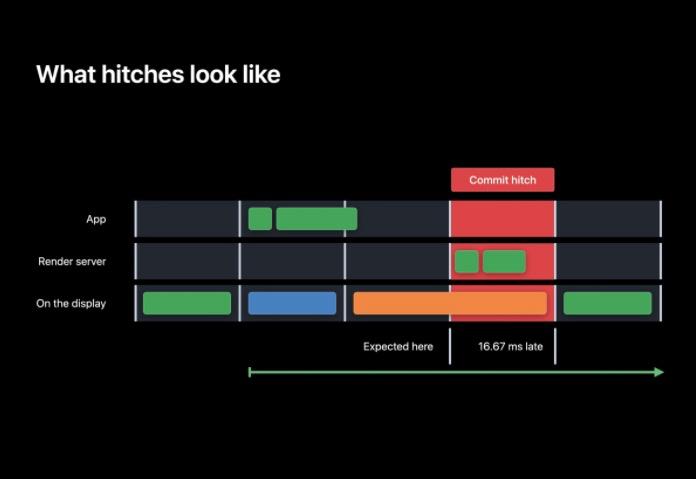
提交卡顿指的是 App 花费过长时间来处理或提交事件。
在提交中用了太长的时间而错过了截止期,所以在下一个 VSYNC 中 RenderServer 没有事情可以处理,必须等待下一个 VSYNC 到来后才能开始渲染。现在已经把帧传送的时间推迟了一帧,以毫秒计时这将是 iPhone(60hz) 或 iPad 上的 16.67 毫秒。这个延迟时间就被称为“卡顿时间(Hitch Time)”。如果提交工作花了更长的时间,比如通过了下一个 VSYNC 的起始时间,那么这一帧就晚了两帧或者说是 33.34 毫秒,在这 33.34 毫秒中用户都无法得到顺畅的滚动。
如何避免卡顿
保持视图的轻量
为了保持视图的轻量尽可能地利用CALayer 上 GPU 加速的可用属性,如非必要需要避免使用 CPU 进行自定义绘制。
若非必要情况下不要重写 drawRect 属性,因为其会开辟额外的内存空间进行 CPU 绘制,并且在 CPU 上绘制会耗费更多的时间主线程。针对于文本、图片等原本就在 CPU 上进行绘制的系统控件,我们可以尝试使用其更底层线程安全的 CoreGraphics 能力,比如 TextKit、CoreText 等搭配多线程异步绘制减轻主线程压力。
尽量复用视图而不是频繁的添加或移除视图。
如果要把某一视图从某一动画中移除,尽量使用 hidden 属性。
对于 Prepare 阶段,当我们的 UIImage 容器视图的大小小于图片本身时,我们通常可以使用 下采样技术(downsampling) 来进行缩略图的创建以节省部分内存空间。
避免复杂布局
减少代价过高且重复的布局,在需要更新布局时尽量只使用 setNeedsLayout。layoutIfNeeded 会消耗当前事务的生命周期也会造成卡顿,大多数时候你可以等到下一次 Runloop 执行时再更新你的布局。
尝试使用最少的约束来完成布局。
视图应该只能使自己或自己的子视图无效,而不能使其同级视图或父视图无效,避免递归布局。
避免非必要的视图层级创建,复杂的视图层级会增加提交阶段的整体耗时
合理多线程能力
学会利用 GCD 的多线程能力,充分利用 CPU 多核优势,提前在子线程进行布局等 UI 无关操作,避免主线程挂起(hang)。
避免主线程 IO 等磁盘相关操作。
而针对于常见的主线程解码操作,在 iOS15 之前,我们通常都是自己封装或是利用最常见的第三方库 SDWebImage 替我们在子线程进行解码操作。而在 iOS15 中,Apple 终于提供了官方的解决方案以解决该问题:UIImage 的 prepareThumbnailOfSize:completionHandler: 等新接口。
针对于必须在 CPU 上进行绘制的组件,尝试结合多线程使用异步绘制能力减轻主线程压力。
▐ 渲染卡顿
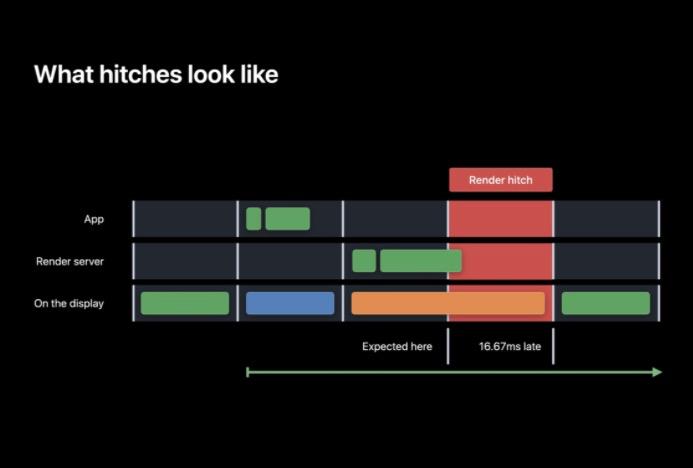
概念
渲染卡顿会在渲染服务器无法按时准备或者执行图层树时出现。这里显然 Execute 的时长超过了 VSYNC 的界限,因此这一帧无法按时准备好。绿色的画面比预期的晚了一帧于是有了 16 毫秒的卡顿
如何避免卡顿
准备阶段我们影响较少,通常主要影响在于执行阶段的离屏渲染。对于阴影来说,在设置阴影时,确保设置 shadowPath 以减少大量离屏通道。在圆化矩形时,使用 cornerRadius 和 cornerCurve 属性避免用蒙版或角内容来构成圆角矩形。

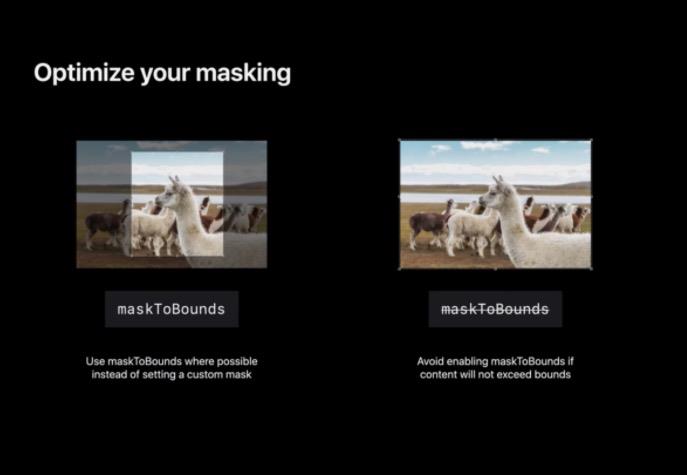
优化整个 App 的 Mask。使用 masksToBounds 遮蔽为矩形圆角矩形或椭圆形的性能比自定义蒙版图层好得多。重要的是用 Instruments 来对 App 进行分析并检查图层树以获得重要的技巧从而降低整体离屏计数。
合理并谨慎的使用 shouldRasterize 属性,它会对一块图层进行光栅化操作并进行缓存。若针对于需要频繁刷新的图层使用该属性反而对性能有着负面影响。
尽量使用非透明的图层以尽量减少图层混合。
检测卡顿
当只着眼于一个卡顿或几个卡顿时,卡顿时间是很有用的,但在像在滚动、动画或者是转场等时长更长的事件时会变得很难处理。除非每次滚动或者动画用的都是完全相同的时间,这样就会有相同的帧数。并且 iOS 设备并不总是更新屏幕,如果没有事务发送到 RenderServer 上,新的一帧就不会被提交。通过测试来比较卡顿时间就更难了。所以 Apple 提供了一种叫 “卡顿时间比(Hitch Time Ratio)” 的指标来衡量一段时间内的卡顿情况。
卡顿时间比就是一个区间内的总卡顿时间除以它的持续时间。因为它标准化为总时间,我们就能在不同的实践中交叉比较。它是由每秒中的卡顿毫秒时间来测定的。所以代表着设备在每秒内出现卡顿的毫秒数。

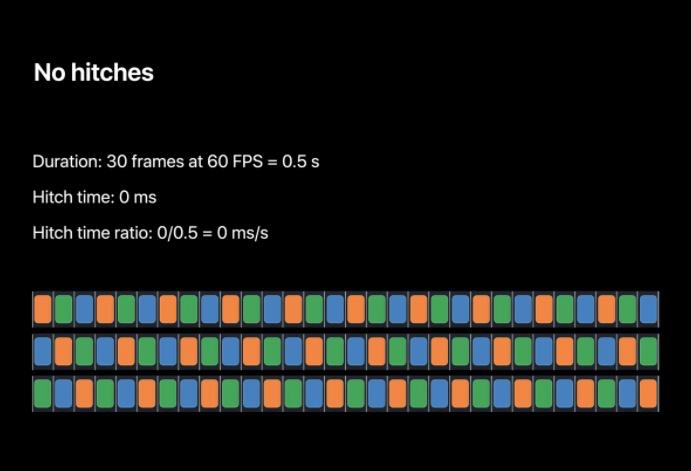
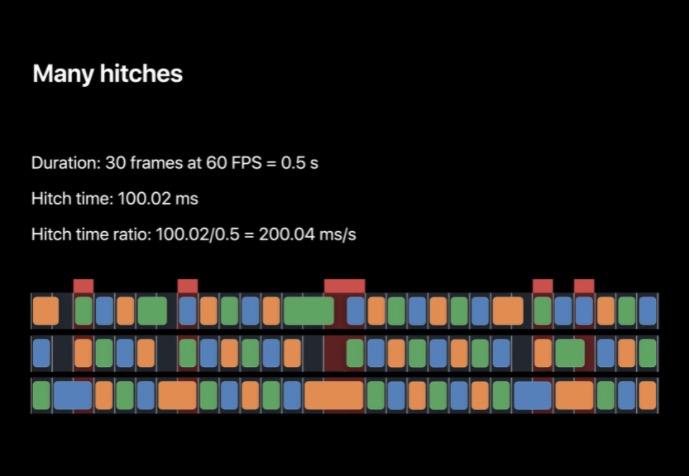
一个实例如下,在一台 iPhone(60HZ) 上这是半秒的工作量,每一帧都在 VSYNC 到来前准备好了,所以用户看不到卡顿,卡顿时间为 0,卡顿时间比也为 0。
第二个例子如下,在该例中有时是在提交阶段的卡顿,有时是在 RenderServer 中造成了卡顿。将卡顿时间加起来结果就是 100.02 ms 半秒。我们就得到了每秒 200.04 ms 的卡顿时间比。
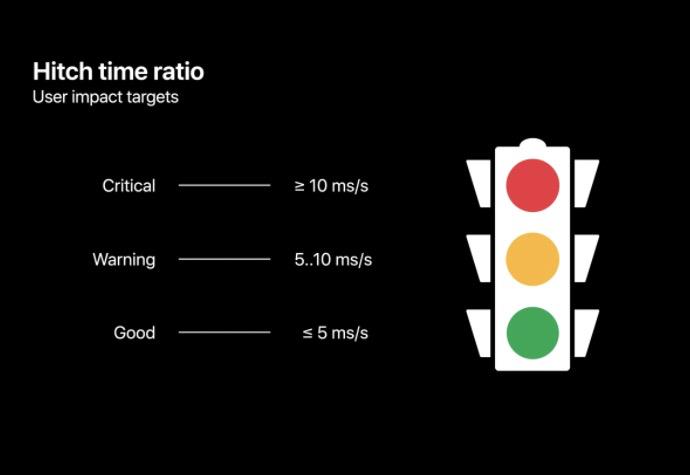
以下是苹果建议的卡顿时间比目标。目标是 5 ms/s 以下的卡顿,是最不易被用户察觉到的。5~10 ms/s 的卡顿用户就会察觉到一些中断。超过 10 ms/s 就会严重影响用户体验。
总结
本篇主要讨论了 RenderLoop 以及新的一帧展现给用户的整个流程,并且着眼于什么是卡顿,以及它的两种类型:提交卡顿以及渲染卡顿。并最终定义了卡顿时间比用以测量当前 App 的卡顿程度和性能。相信大家对整个渲染循环和卡顿类型有了更清晰的认识,在日常编码中也可以尽量避免这些问题。
本篇主要介绍了一些原理相关的概念,那么具体的卡顿应该如何测量?下一篇将会通过实践结合 Instrument 的 AnimationHitches 能力分析 DXSDK 作为卡片层面在日常信息流的使用过程中在性能方面存在的一些问题,以及 DXSDK 上半年做的一些性能优化改进。
参考资料
WWDC 2020,2021
✿ 拓展阅读


作者|岚遥
编辑|橙子君
出品|阿里巴巴新零售淘系技术


以上是关于iOS 性能检测新方式——AnimationHitches的主要内容,如果未能解决你的问题,请参考以下文章