《Redis核心技术与实战》学习总结
Posted dotNET跨平台
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《Redis核心技术与实战》学习总结相关的知识,希望对你有一定的参考价值。

【Redis】| 总结/Edison Zhou
1上一篇的遗留问题
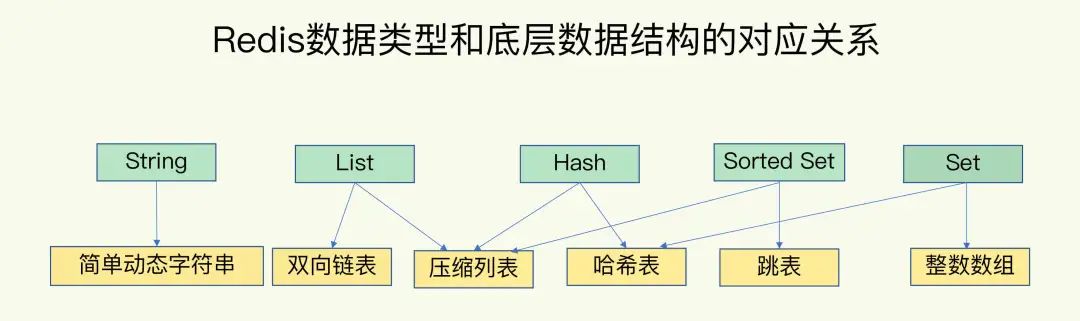
上一篇总结了一个KV数据库的基本架构 和 Redis的底层数据结构概览,重点总结了Sorted Set的两个数据结构的切换,但没有介绍List的两个数据结构的切换,因此本文试着总结一下。
这里先直接给出答案:

从上图可以看到,当List的数据满足下面两个条件时,就会使用压缩列表,否则使用双向链表。
(1)列表对象保存的所有字符串元素的长度都小于64字节;
(2)列表对象保存的元素数量小于512个;
这两个参数其实也是可以在redis.conf中修改的:
list-max-ziplist-value 64
list-max-ziplist-entries 5122Redis 3.2之前的实现
由上一篇已经知道,List类型的底层实现包括了 双向链表 和 压缩列表,但这是在Redis的3.2版本之前的底层实现。而从Redis 3.2版本开始,Redis修改了List的底层实现,将压缩列表 和 双向链表 结合,我们称它为 quickList 快速列表。
从第一节的内容我们已经知道,当创建一个新的List时,Redis会优先使用压缩列表,然后在有需要的时候,再转成双向链表。
Redis为什么要这么设计呢?
因为,双向链表的内存占用 比 压缩列表 多,而压缩列表的设计初衷就在于 节约内存。众所周知,Redis之所以快的原因之一就是它是内存数据库,所有操作都在内存上完成,因此对于内存的占用有要求。
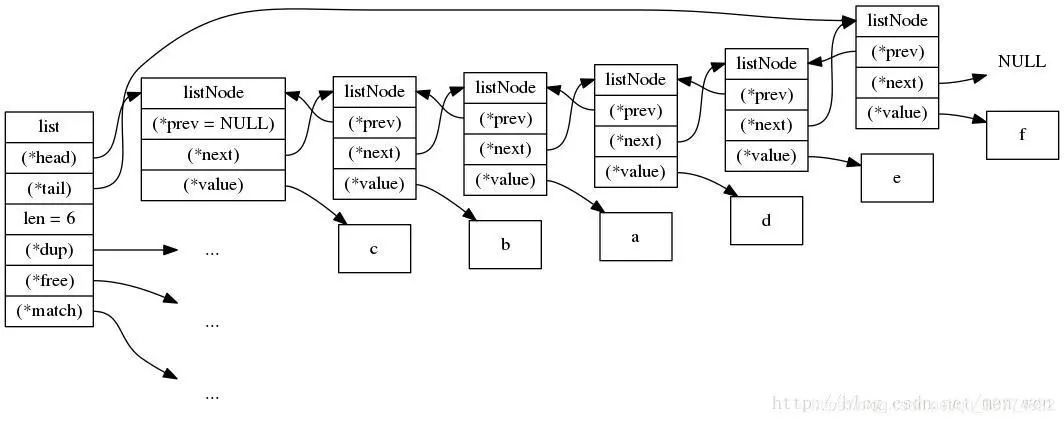
双向链表
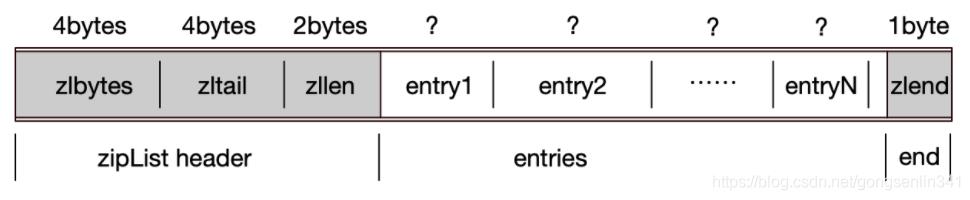
压缩列表
画外音:在Redis 3.2 之前,我们也可以通过命令来验证:
192.168.80.100:6379> rpush testkey "edison" "andy" "leo"
3
192.168.80.100:6379> object encoding testkey
ziplist
192.168.80.100:6379> rpush testkey "wwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwww"
4
192.168.80.100:6379> object encoding testkey
linkedlist那么,压缩列表为什么占用内存少呢?
其实从上面的图和下面的源码也可以看出来,压缩列表并没有维护双向指针prev 和 next,而只是存储了上一个entry的长度 和 下一个entry的长度,通过长度来推算下一个entry在哪里。
typedef struct zlentry { // 压缩列表节点
unsigned int prevrawlensize, prevrawlen; // prevrawlen是前一个节点的长度,prevrawlensize是指prevrawlen的大小,有1字节和5字节两种
unsigned int lensize, len; // len为当前节点长度 lensize为编码len所需的字节大小
unsigned int headersize; // 当前节点的header大小
unsigned char encoding; // 节点的编码方式
unsigned char *p; // 指向节点的指针
} zlentry;这是一种典型的“时间换空间”的方法,即牺牲读取的性能,换取极致的存储空间。由于压缩列表存储在一段连续的内存上,所以它的存储效率还是蛮高的。
但是,此种设计只适合在字段个数、值比较小的时候,一旦长度过长,压缩列表的设计(利于读取但不利于修改的初衷)会导致修改和删除操作需要频繁的申请和释放内存,可能会导致大量的数据拷贝,拖慢Redis的整体性能。
因此,Redis选择了在达到阈值时,切换数据结构为双向链表。
3Redis 3.2之后的实现
在Redis 3.2及之后,Redis选择了结合压缩列表 和 双向链表的优点,形成了一个新的底层实现:quicklist 快速列表。
快速列表是一个压缩列表组成的双向链表,每个节点使用压缩列表来保存数据。换句话说,快速列表中保存了一个个小的压缩列表。其结构如下图所示:
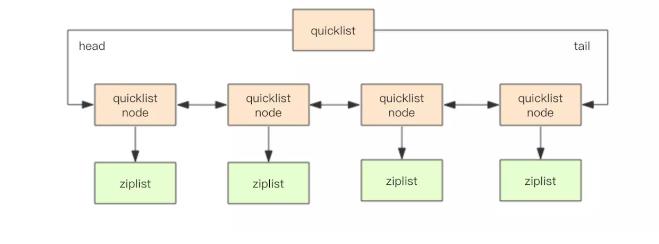
为了进一步节约空间,Redis 还会对压缩列表进行压缩存储(一种无损压缩算法LZF),这取决压缩深度的参数设置,我们可以选择不压缩(默认值不压缩) 也可以 选择压缩中间节点。
画外音:两端节点一般不被压缩,因为当一个链表很长时,最频繁访问的就是两端的数据,根据“二八定律”,两端数据不压缩,而将中间数据压缩,从而节省空间,但又保证读取效率。
此外,对于每个压缩列表的大小,也是可以通过在redis.conf中的参数来设置的:
list-max-ziplist-size -2参数可选值从-1到-5,其含义如下:
1) -5:每个quicklist节点上的ziplist大小不能超过64kb。
2) -4:每个quicklsit节点上的ziplist大小不能超过32kb。
3) -3:每个quicklsit节点上的ziplist大小不能超过16kb。
4) -2:每个quicklsit节点上的ziplist大小不能超过8kb。
5) -1:每个quicklsit节点上的ziplist大小不能超过4kb。
画外音:在Redis 3.2 之后,我们也可以通过命令来验证:
192.168.80.100:6379> rpush testkey "edison" "andy" "leo"
3
192.168.80.100:6379> object encoding testkey
quicklist
192.168.80.100:6379> rpush testkey "wwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwww"
4
192.168.80.100:6379> object encoding testkey
quicklist综述,快速列表的本质其实是对压缩列表的一次封装,使用小块的压缩列表来组织,既可以保证内存占用较小,也可以保证操作性能。
End总结
本文总结了Redis的List类型在何时使用压缩列表,何时使用双向链表,以及快速列表的基本概念。当然,更多的内容还是需要自行去搜索学习,意犹未尽的童鞋也可以去分析源码。最后,如果你对其他集合类型也有此类问题,你可以参考下面附录中的内容,而至于Why,则可以自行百度搜索了解。
Anyway,对于Redis集合类型的底层思想采用了两种数据结构的设计思想是值得我们学习借鉴的,它其实充分体现了软件设计中的Tradeoff(权衡)思想。对于Redis来说,即在主体目标是保证性能的大约束前提下,权衡多方因素如操作时间和空间占用,以达到较为稳定的运行表现。对于软件设计来说,也需要在时间 vs 空间,新技术 vs 老技术,优雅 vs 效率,轻度设计 vs 重度设计等之间做权衡,一个问题总会有多种解决方案可以实现,在特定的时间段,永远没有最完美的设计,只有较合适的设计。在实际中,它可能结合了多种因素的考虑,不断地去粗取精,迭代为更好的设计。
Ref附录
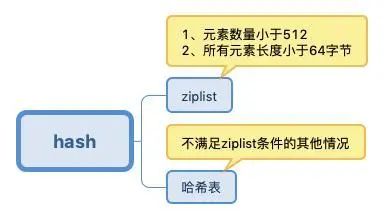
Hash:
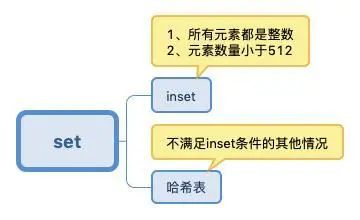
Set:
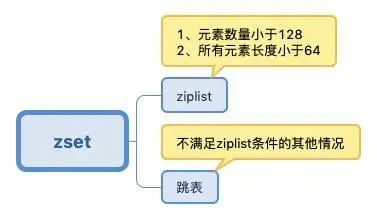
Sorted Set(zset):
参考资料
极客时间,蒋德钧《Redis核心技术与实战》

年终总结:Edison的2020年终总结
数字化转型:我在传统企业做数字化转型
C#刷题:C#刷剑指Offer算法题系列文章目录
.NET面试:.NET开发面试知识体系
.NET大会:2020年中国.NET开发者大会PDF资料

以上是关于《Redis核心技术与实战》学习总结的主要内容,如果未能解决你的问题,请参考以下文章
Day768.大佬推荐的经典的Redis学习资料 -Redis 核心技术与实战
Day774.能向 Redis 学到什么 -Redis 核心技术与实战