RNN经典案例使用seq2seq模型架构实现英译法任务
Posted ZSYL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RNN经典案例使用seq2seq模型架构实现英译法任务相关的知识,希望对你有一定的参考价值。
使用seq2seq模型架构实现英译法任务
前言
学习目标:
- 更深一步了解seq2seq模型架构和翻译数据集.
- 掌握使用基于GRU的seq2seq模型架构实现翻译的过程.
- 掌握Attention机制在解码器端的实现过程.
seq2seq模型架构:
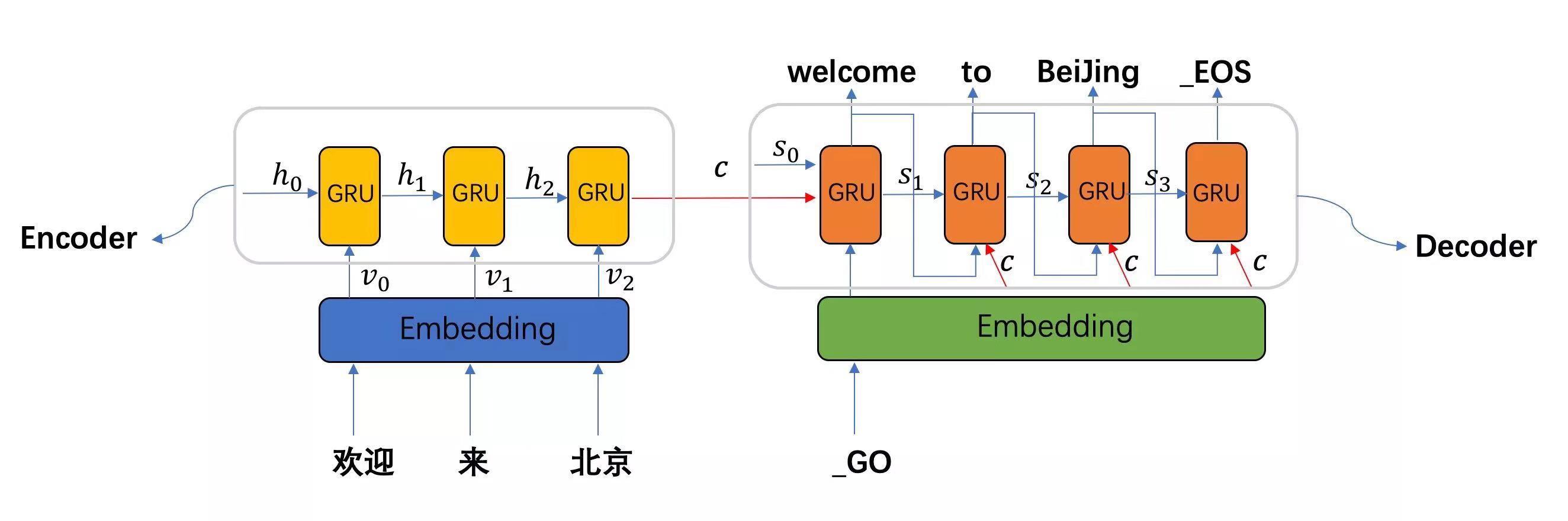
seq2seq模型架构分析:
从图中可知, seq2seq模型架构, 包括两部分分别是encoder(编码器)和decoder(解码器), 编码器和解码器的内部实现都使用了GRU模型, 这里它要完成的是一个中文到英文的翻译: 欢迎 来 北京 --> welcome to BeiJing. 编码器首先处理中文输入"欢迎 来 北京", 通过GRU模型获得每个时间步的输出张量,最后将它们拼接成一个中间语义张量c, 接着解码器将使用这个中间语义张量c以及每一个时间步的隐层张量, 逐个生成对应的翻译语言.
翻译数据集:
下载地址: https://download.pytorch.org/tutorial/data.zip
数据文件预览:
- data/
- eng-fra.txt
She feeds her dog a meat-free diet. Elle fait suivre à son chien un régime sans viande.
She feeds her dog a meat-free diet. Elle fait suivre à son chien un régime non carné.
She folded her handkerchief neatly. Elle plia soigneusement son mouchoir.
She folded her handkerchief neatly. Elle a soigneusement plié son mouchoir.
She found a need and she filled it. Elle trouva un besoin et le remplit.
She gave birth to twins a week ago. Elle a donné naissance à des jumeaux il y a une semaine.
She gave him money as well as food. Elle lui donna de l'argent aussi bien que de la nourriture.
She gave it her personal attention. Elle y a prêté son attention personnelle.
She gave me a smile of recognition. Elle m'adressa un sourire indiquant qu'elle me reconnaissait.
She glanced shyly at the young man. Elle a timidement jeté un regard au jeune homme.
She goes to the movies once a week. Elle va au cinéma une fois par semaine.
She got into the car and drove off. Elle s'introduisit dans la voiture et partit.
基于GRU的seq2seq模型架构实现翻译的过程:
- 第一步: 导入必备的工具包.
- 第二步: 对持久化文件中数据进行处理, 以满足模型训练要求.
- 第三步: 构建基于GRU的编码器和解码器.
- 第四步: 构建模型训练函数, 并进行训练.
- 第五步: 构建模型评估函数, 并进行测试以及Attention效果分析.
1. 导入必备的工具包
python版本使用3.6.x, pytorch版本使用1.3.1
pip install torch==1.3.1
# 从io工具包导入open方法
from io import open
# 用于字符规范化
import unicodedata
# 用于正则表达式
import re
# 用于随机生成数据
import random
# 用于构建网络结构和函数的torch工具包
import torch
import torch.nn as nn
import torch.nn.functional as F
# torch中预定义的优化方法工具包
from torch import optim
# 设备选择, 我们可以选择在cuda或者cpu上运行你的代码
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
2. 数据预处理
对持久化文件中数据进行处理, 以满足模型训练要求
2.1 将指定语言中的词汇映射成数值
# 起始标志
SOS_token = 0
# 结束标志
EOS_token = 1
class Lang:
def __init__(self, name):
"""初始化函数中参数name代表传入某种语言的名字"""
# 将name传入类中
self.name = name
# 初始化词汇对应自然数值的字典
self.word2index = {}
# 初始化自然数值对应词汇的字典, 其中0,1对应的SOS和EOS已经在里面了
self.index2word = {0: "SOS", 1: "EOS"}
# 初始化词汇对应的自然数索引,这里从2开始,因为0,1已经被开始和结束标志占用了
self.n_words = 2
def addSentence(self, sentence):
"""添加句子函数, 即将句子转化为对应的数值序列, 输入参数sentence是一条句子"""
# 根据一般国家的语言特性(我们这里研究的语言都是以空格分个单词)
# 对句子进行分割,得到对应的词汇列表
for word in sentence.split(' '):
# 然后调用addWord进行处理
self.addWord(word)
def addWord(self, word):
"""添加词汇函数, 即将词汇转化为对应的数值, 输入参数word是一个单词"""
# 首先判断word是否已经在self.word2index字典的key中
if word not in self.word2index:
# 如果不在, 则将这个词加入其中, 并为它对应一个数值,即self.n_words
self.word2index[word] = self.n_words
# 同时也将它的反转形式加入到self.index2word中
self.index2word[self.n_words] = word
# self.n_words一旦被占用之后,逐次加1, 变成新的self.n_words
self.n_words += 1
实例化参数:
name = "eng"
输入参数:
sentence = "hello I am Jay"
调用:
engl = Lang(name)
engl.addSentence(sentence)
print("word2index:", engl.word2index)
print("index2word:", engl.index2word)
print("n_words:", engl.n_words)
输出效果:
word2index: {'hello': 2, 'I': 3, 'am': 4, 'Jay': 5}
index2word: {0: 'SOS', 1: 'EOS', 2: 'hello', 3: 'I', 4: 'am', 5: 'Jay'}
n_words: 6
2.2 字符规范化
# 将unicode转为Ascii, 我们可以认为是去掉一些语言中的重音标记:Ślusàrski
def unicodeToAscii(s):
return ''.join(
c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn'
)
def normalizeString(s):
"""字符串规范化函数, 参数s代表传入的字符串"""
# 使字符变为小写并去除两侧空白符, z再使用unicodeToAscii去掉重音标记
s = unicodeToAscii(s.lower().strip())
# 在.!?前加一个空格
s = re.sub(r"([.!?])", r" \\1", s)
# 使用正则表达式将字符串中不是大小写字母和正常标点的都替换成空格
s = re.sub(r"[^a-zA-Z.!?]+", r" ", s)
return s
输入参数:
s = "Are you kidding me?"
调用:
nsr = normalizeString(s)
print(nsr)
输出效果:
are you kidding me ?
2.3 将持久化文件中的数据加载到内存, 并实例化类Lang
data_path = '../Downloads/data/eng-fra.txt'
def readLangs(lang1, lang2):
"""读取语言函数, 参数lang1是源语言的名字, 参数lang2是目标语言的名字
返回对应的class Lang对象, 以及语言对列表"""
# 从文件中读取语言对并以/n划分存到列表lines中
lines = open(data_path, encoding='utf-8').\\
read().strip().split('\\n')
# 对lines列表中的句子进行标准化处理,并以\\t进行再次划分, 形成子列表, 也就是语言对
pairs = [[normalizeString(s) for s in l.split('\\t')] for l in lines]
# 然后分别将语言名字传入Lang类中, 获得对应的语言对象, 返回结果
input_lang = Lang(lang1)
output_lang = Lang(lang2)
return input_lang, output_lang, pairs
输入参数:
lang1 = "eng"
lang2 = "fra"
调用:
input_lang, output_lang, pairs = readLangs(lang1, lang2)
print("input_lang:", input_lang)
print("output_lang:", output_lang)
print("pairs中的前五个:", pairs[:5])
输出效果:
input_lang: <__main__.Lang object at 0x11ecf0828>
output_lang: <__main__.Lang object at 0x12d420d68>
pairs中的前五个: [['go .', 'va !'], ['run !', 'cours !'], ['run !', 'courez !'], ['wow !', 'ca alors !'], ['fire !', 'au feu !']]
2.4 过滤出符合我们要求的语言对
# 设置组成句子中单词或标点的最多个数
MAX_LENGTH = 10
# 选择带有指定前缀的语言特征数据作为训练数据
eng_prefixes = (
"i am ", "i m ",
"he is", "he s ",
"she is", "she s ",
"you are", "you re ",
"we are", "we re ",
"they are", "they re "
)
def filterPair(p):
"""语言对过滤函数, 参数p代表输入的语言对, 如['she is afraid.', 'elle malade.']"""
# p[0]代表英语句子,对它进行划分,它的长度应小于最大长度MAX_LENGTH并且要以指定的前缀开头
# p[1]代表法文句子, 对它进行划分,它的长度应小于最大长度MAX_LENGTH
return len(p[0].split(' ')) < MAX_LENGTH and \\
p[0].startswith(eng_prefixes) and \\
len(p[1].split(' ')) < MAX_LENGTH
def filterPairs(pairs):
"""对多个语言对列表进行过滤, 参数pairs代表语言对组成的列表, 简称语言对列表"""
# 函数中直接遍历列表中的每个语言对并调用filterPair即可
return [pair for pair in pairs if filterPair(pair)]
输入参数:
# 输入参数pairs使用readLangs函数的输出结果pairs
调用:
fpairs = filterPairs(pairs)
print("过滤后的pairs前五个:", fpairs[:5])
输出效果:
过滤后的pairs前五个: [['i m .', 'j ai ans .'], ['i m ok .', 'je vais bien .'], ['i m ok .', 'ca va .'], ['i m fat .', 'je suis gras .'], ['i m fat .', 'je suis gros .']]
2.5 对以上数据准备函数进行整合, 并使用类Lang对语言对进行数值映射
def prepareData(lang1, lang2):
"""数据准备函数, 完成将所有字符串数据向数值型数据的映射以及过滤语言对
参数lang1, lang2分别代表源语言和目标语言的名字"""
# 首先通过readLangs函数获得input_lang, output_lang对象,以及字符串类型的语言对列表
input_lang, output_lang, pairs = readLangs(lang1, lang2)
# 对字符串类型的语言对列表进行过滤操作
pairs = filterPairs(pairs)
# 对过滤后的语言对列表进行遍历
for pair in pairs:
# 并使用input_lang和output_lang的addSentence方法对其进行数值映射
input_lang.addSentence(pair[0])
output_lang.addSentence(pair[1])
# 返回数值映射后的对象, 和过滤后语言对
return input_lang, output_lang, pairs
调用:
input_lang, output_lang, pairs = prepareData('eng', 'fra')
print("input_n_words:", input_lang.n_words)
print("output_n_words:", output_lang.n_words)
print(random.choice(pairs))
输出效果:
input_n_words: 2803
output_n_words: 4345
pairs随机选择一条: ['you re such an idiot !', 'quelle idiote tu es !']
2.6 将语言对转化为模型输入需要的张量
def tensorFromSentence(lang, sentence):
"""将文本句子转换为张量, 参数lang代表传入的Lang的实例化对象, sentence是预转换的句子"""
# 对句子进行分割并遍历每一个词汇, 然后使用lang的word2index方法找到它对应的索引
# 这样就得到了该句子对应的数值列表
indexes = [lang.word2index[word] for word in sentence.split(' ')]
# 然后加入句子结束标志
indexes.append(EOS_token)
# 将其使用torch.tensor封装成张量, 并改变它的形状为nx1, 以方便后续计算
return torch.tensor(indexes, dtype=torch.long, device=device).view(-1, 1)
def tensorsFromPair(pair):
"""将语言对转换为张量对, 参数pair为一个语言对"""
# 调用tensorFromSentence分别将源语言和目标语言分别处理,获得对应的张量表示
input_tensor = tensorFromSentence(input_lang, pair[0])
target_tensor = tensorFromSentence(output_lang, pair[1])
# 最后返回它们组成的元组
return (input_tensor, target_tensor)
输入参数:
# 取pairs的第一条
pair = pairs[0]
调用:
pair_tensor = tensorsFromPair(pair)
print(pair_tensor)
输出效果:
(tensor([[2],
[3],
[4],
[1]]),
tensor([[2],
[3],
[4],
[5],
[1]]))
3. 构建基于GRU的编码器和解码器
3.1 构建基于GRU的编码器
编码器结构图:
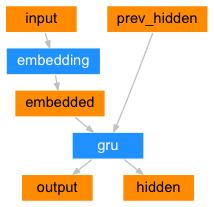
class EncoderRNN(nn.Module):
def __init__(self, input_size, hidden_size):
"""它的初始化参数有两个, input_size代表解码器的输入尺寸即源语言的
词表大小,hidden_size代表GRU的隐层节点数, 也代表词嵌入维度, 同时又是GRU的输入尺寸"""
super(EncoderRNN, self).__init__()
# 将参数hidden_size传入类中
self.hidden_size = hidden_size
# 实例化nn中预定义的Embedding层, 它的参数分别是input_size, hidden_size
# 这里的词嵌入维度即hidden_size
# nn.Embedding的演示在该代码下方
self.embedding = nn.Embedding(input_size, hidden_size)
# 然后实例化nn中预定义的GRU层, 它的参数是hidden_size
# nn.GRU的演示在该代码下方
self.gru = nn.GRU(hidden_size, hidden_size)
def forward(self, input, hidden):
"""编码器前向逻辑函数中参数有两个, input代表源语言的Embedding层输入张量
hidden代表编码器层gru的初始隐层张量"""
# 将输入张量进行embedding操作, 并使其形状变为(1,1,-1),-1代表自动计算维度
# 理论上,我们的编码器每次只以一个词作为输入, 因此词汇映射后的尺寸应该是[1, embedding]
# 而这里转换成三维的原因是因为torch中预定义gru必须使用三维张量作为输入, 因此我们拓展了一个维度
output = self.embedding(input).view(1, 1, -1)
# 然后将embedding层的输出和传入的初始hidden作为gru的输入传入其中,
# 获得最终gru的输出output和对应的隐层张量hidden, 并返回结果
output, hidden = self.gru(output, hidden)
return output, hidden
def initHidden(self):
"""初始化隐层张量函数"""
# 将隐层张量初始化成为1x1xself.hidden_size大小的0张量
return torch.zeros(1, 1, self.hidden_size, device=device)
实例化参数:
hidden_size = 25
input_size = 20
输入参数:
# pair_tensor[0]代表源语言即英文的句子,pair_tensor[0][0]代表句子中
的第一个词
input = pair_tensor[0][0]
# 初始化第一个隐层张量,1x1xhidden_size的0张量
hidden = torch.zeros(1, 1, hidden_size)
调用:
encoder = EncoderRNN(input_size, hidden_size)
encoder_output, hidden = encoder(input, hidden)
print(encoder_output)
输出效果:
tensor([[[ 1.9149e-01, -2.0070e-01, -8.3882e-02, -3.3037e-02, -1.3491e-01,
-8.8831e-02, -1.6626e-01, -1.9346e-01, -4.3996e-01, 1.8020e-02,
2.8854e-02, 2.2310e-01, 3.5153e-01, 2.9635e-01, 1.5030e-01,
-8.5266e-02, -1.4909e-01, 2.4336e-04, -2.3522e-01, 1.1359e-01,
1.6439e-01, 1.4872e-01, -6.1619e-02, -1.0807e-02, 1.1216e-02]]],
grad_fn=<StackBackward>)
3.2 构建基于GRU的解码器
解码器结构图:
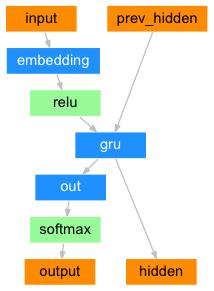
class DecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size):
"""初始化函数有两个参数,hidden_size代表解码器中GRU的输入尺寸,也是它的隐层节点数
output_size代表整个解码器的输出尺寸, 也是我们希望得到的指定尺寸即目标语言的词表大小"""
super(DecoderRNN, self).__init__()
# 将hidden_size传入到类中
self.hidden_size = hidden_size
# 实例化一个nn中的Embedding层对象, 它的参数output这里表示目标语言的词表大小
# hidden_size表示目标语言的词嵌入维度
self.embedding = nn.Embedding(output_size, hidden_size)
# 实例化GRU对象,输入参数都是hidden_size,代表它的输入尺寸和隐层节点数相同
self.gru = nn.GRU(hidden_size, hidden_size)
# 实例化线性层, 对GRU的输出做线性变化, 获我们希望的输出尺寸output_size
# 因此它的两个参数分别是hidden_size, output_size
self.out = nn.Linear(hidden_size, output_size)
# 最后使用softmax进行处理,以便于分类
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden):
"""解码器的前向逻辑函数中, 参数有两个, input代表目标语言的Embedding层输入张量
hidden代表解码器GRU的初始隐层张量"""
# 将输入张量进行embedding操作, 并使其形状变为(1,1,-1),-1代表自动计算维度
# 原因和解码器相同,因为torch预定义的GRU层只接受三维张量作为输入
output = self.embedding(input).view(1, 1, -1)
# 然后使用relu函数对输出进行处理,根据relu函数的特性, 将使Embedding矩阵更稀疏,以防止过拟合
output = F.relu(output)
# 接下来, 将把embedding的输出以及初始化的hidden张量传入到解码器gru中
output, hidden = self.gru(output, hidden)
# 因为GRU输出的output也是三维张量,第一维没有意义,因此可以通过output[0]来降维
# 再传给线性层做变换, 最后用softmax处理以便于分类
output = self.softmax(self.out(output[0]))
return output, hidden
def initHidden(self):
"""初始化隐层张量函数"""
# 将隐层张量初始化成为1x1xself.hidden_size大小的0张量
return以上是关于RNN经典案例使用seq2seq模型架构实现英译法任务的主要内容,如果未能解决你的问题,请参考以下文章