(王道408考研操作系统)第二章进程管理-第一节3:进程控制(配合Linux讲解)
Posted 快乐江湖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(王道408考研操作系统)第二章进程管理-第一节3:进程控制(配合Linux讲解)相关的知识,希望对你有一定的参考价值。
文章目录
进程控制是指对系统中所有进程实施有效的管理,它具有创建新进程、撤销已有进程、实现进程状态转换等功能。可以简单理解为实现进程状态转换

一:如何实现进程控制
还记的PCB吗? 对,就是它。在学校中学校如果想要对我们进行管理,依靠的就是你的综测,在操作系统中要对进程进行控制依靠的就是PCB
在Linux的task struct结构体定义中(Linux是用C语言写的)大家可以很明显的看到一个字段叫做state
struct task_struct {
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
void *stack;
atomic_t usage;
unsigned int flags; /* per process flags, defined below */
unsigned int ptrace;
int lock_depth; /* BKL lock depth */
#ifdef CONFIG_SMP
#ifdef __ARCH_WANT_UNLOCKED_CTXSW
int oncpu;
#endif
#endif
......
.....
...
既然这样,操作系统在实现进程状态控制时,就像记录学生成绩一样,进行删删改改,修修补补即可(当然没有这么简单)

- 创建进程:需要初始化PCB、分配系统资源
- 创建态->就绪态:修改PCB内容和相应队列
- 就绪态->运行态:恢复进程运行环境、修改PCB内容和相应队列
- 运行态->终止态:回收进程拥有的资源,撤销PCB
- 运行态->就绪态:(进程切换)需要保存进程运行环境、修改PCB内容和相应队列
- 运行态->阻塞态:需要保存进程运行环境、修改PCB内容和相应队列
- 阻塞态->就绪态:需要保存进程运行环境、修改PCB内容和相应队列。如果等待的是资源,则还需要为进程分配系统资源
二:进程控制原语
原语就是指原子性操作。“要么做要么不做,如果做了你就做完”,这就是原子性操作的含义,不能出现模棱两可的情况
进程控制是一个高度敏感的话题,如果出现控制方面的二义性问题话会导致一些不堪设想的后果,所以需要使用原语进行进程控制,采用“关中断”“开中断”实现原语操作,在执行期间不允许中断

接下来的三种原语中,无论哪一个原语,它们所做的事情无外乎以下三种
- 更新PCB中的信息。比如修改进程状态标志、将运行环境保存到PCB、从PCB恢复运行环境等等
- 将PCB插入至合适的队列
- 分配/回收资源
(1)进程创建
A:概述
一个进程创建另一个进程,此时创建者称为父进程,被创建的进程称之为子进程
- 子进程可以继承父进程所拥有的资源;子进程撤销时,应将其从父进程哪里获得的资源还给父进程
创建新进程的过程如下
- 申请空白PCB:为新进程分配一个唯一的进程标识号,并申请一个空白的PCB,若PCB申请失败,则进程创建失败
- 为新进程分配所需资源:为新进程的程序和数据及用户栈分配必要的内存空间,注意若资源不足,进入阻塞态等待资源
- 初始化PCB:主要包括初始化标志信息、初始化处理机状态信息和初始化处理机控制信息,以及设置进程的优先级等等
- 将PCB插入就绪队列:若进程就绪队列能够接纳新进程,则将新进程插入就绪队列,等待被调度运行
可以引起进程创建的事件有
- 用户登录:分时系统中,用户登录成功,系统会为其建立一个新的进程。比如Linux中的
bash - 作业调度:多道批处理系统中,有新的作业放入内存时,会为其建立一个新的进程
- 提供服务:用户向操作系统提出某些请求时,会建立一个进程处理该请求
- 应用请求:由用户进程主动请求创建一个子进程。比如Linux中的系统调用
fork
B:补充-Linux中的创建进程操作
上面所叙述的均是概述,并没有针对特定的操作系统,因此这里以Linux为例,展示一下在Linux中创建进程等操作,加深同学们的理解。如果想要了解更多请移步:Linux系统编程10:进程入门之系统编程中最重要的概念之进程&&进程的相关操作&&使用fork创建进程
fork()函数是用来创建进程的,在fork函数执行后,如果成功创建新进程就会出现两个进程,一个是子进程,一个是父进程,fork函数有两个返回值
①:fork()
1:演示一:创建子进程
编写如下C语言文件,进入主函数后,执行fork函数,创建进程
#include <stdio.h>
#include <unistd.h>
int main()
{
printf("执行到fork函数之前其进程为:%d,其父进程为:%d\\n",getpid(),getppid());
sleep(1);
fork();
sleep(1);
prinf("这个进程id为:%d,它的父进程id为%d\\n",getpid(),getppid());
sleep(1);
return 0;
}
运行效果如下

根据上面程序的运行效果,似乎可以发现下面比较值得注意的几点
- 它们的逻辑关系有些特点
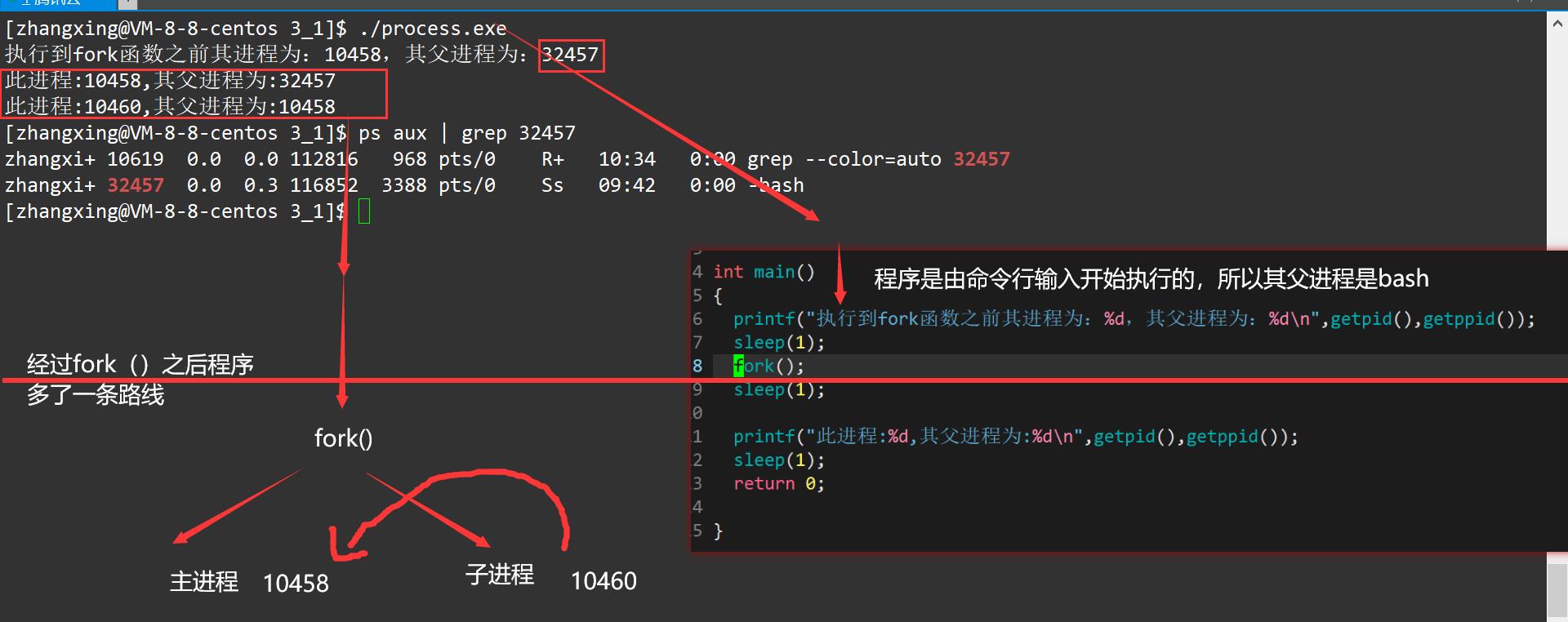
- 从上面的动图可以发现,fork()函数调用完成之后,它们似乎是同时输出的,这是否告诉我们这两个进程是同时进行的? 或许它可以被画成这样?

2:演示二:创建子进程
前面说过,fork有两个返回值。官方手册中是这样解释到的
- 在父进程中,fork返回新创建子进程的ID
- 在子进程中,fork返回0
- 未能创建,fork返回负值
在子进程中,fork函数返回0,在父进程中,fork返回新创建子进程的ID。我们可以通过fork返回值判断当前进程是什么进程。
根据以上描述,编写C语言代码,使用fork函数的返回值来进行分流
#include <stdio.h>
#include <unistd.h>
int main()
{
prinf("还没有执行fork函数的本进程为:%d\\n",getpid());
pid_t=fork();//其返回值是pid类型的
sleep(1);
if(ret>0)//父进程返回的是子进程ID
printf("我是父进程,我的id是:%d,我的孩子id是%d\\n",getpid(),ret);
else if(ret==0)//子进程fork返回值是0
printf("我是子进程,我的id是%d,我的父亲id是%d\\n",getpid(),getppid());
else
printf("进程创建失败\\n");
sleep(1);
return 0;
}
效果如下
3:演示三:一个大的问题
为了方便演示,修改上述代码如下,为每个if语句块内加入死循环,使其能不断输出
#include <stdio.h>
#include <unistd.h>
int main()
{
prinf("还没有执行fork函数的本进程为:%d\\n",getpid());
pid_t=fork();//其返回值是pid类型的
sleep(1);
if(ret>0)//父进程返回的是子进程ID
{
while(1)
{
printf("----------------------------------------------------------------\\n");
printf("我是父进程,我的id是:%d,我的孩子id是%d\\n",getpid(),ret);
sleep(1);
}
}
else if(ret==0)//子进程fork返回值是0
{
while(1)
{
printf("我是子进程,我的id是%d,我的父亲id是%d\\n",getpid(),getppid());
sleep(1);
}
}
else
printf("进程创建失败\\n");
sleep(1);
return 0;
}
效果如下

同时再使用之前的命令查看这个进程,发现也是两个进程
但是这里有一个很大的问题:我们知道,不论是哪种编程语言,if-else执行时每次只能执行一路,怎么可能同时执行多路,同时每个if语句块内都有死循环,一个循环未结束,又怎么可能去执行其他语句呢
其实在Linux中,进程创建会形成链表,父进程创建子进程,那么父进程的进程指针会指向子进程ID。所以这两个进程是同时运行的
②:fork()相关问题
1.如何理解进程创建
前面说过,操作系统在进行管理时,必然遵循“先描述,再组织”的原则,所以在进行进程管理时。首先会创建相应的task_struct,写入有关信息,然后和你编写好的代码共同组成进程
2.为什么fork有两个返回值
根据上面的描述,可以大致描述fork函数的执行逻辑如下
pid_t fork()
{
//先描述,再组织,所以首先为子进程创建结构体
struct task_struct* p=malloc(struct task_struct);
//以下逻辑就是写入属性信息
p->XX=father->XX;
....
p->status=run;
p->id=1888;
//到这里之前,子进程创建完毕
return p->id;
}
其实,进程数据=代码+数据,代码是共享的,数据是私有的,上述逻辑中return之前的语句是父进程执行,结果就是生成了子进程,等执行return语句时,子进程已经生成,于是父子进程同时执行这一条语句,又因为数据是私有的,所以各自返回不同的值
执行完fork之后,父进程pid不等于0,子进程pid等于0。这两个进程都是独立的,存在于不同地址中,不是公用的。
fork把进程当前的情况进行拷贝,执行fork时,fork只拷贝下一个要执行的代码到新的进程
为了说明变量不共用,可以编写一个C语言代码如下,同一个变量分别在父进程和子进程中修改
#include <stdio.h>
#include <unistd.h>
int main()
{
int cout=0;
printf("还未执行fork函数的cout=%d\\n",cout);
pid_t ret=fork();
if(ret>0)
{
cout+=1;//父进程cout=1;
printf("父进程:cout=%d\\n",cout);
}
else if(ret==0)
{
cout+=10;//子进程cout=10;
printf("子进程:cout=%d\\n",cout);
}
else
printf("失败\\n");
sleep(1);
return 0;
}
结果如下,可以发现它们不公用变量

3.为什么两个返回值不一样
其实很好理解,创建进程时相当于形成了链表(Linux)中,父进程指向子进程,所以返回的是子进程的ID,而子进程没有它的子进程,所以返回0。
再者从现实生活中理解,一个孩子肯定知道它只有一个爹,而一个爹可能有多个孩子,所以子进程在标识父进程时就不要做那么多的区分,但是父进程可能有多个子进程,它与它在区分不同的子进程时必须要使用PID。
4.为什么代码是共享的,数据是私有的
首先代码是不可修改的(还记得代码段,数据段吗?),还有下面的常量字符串其实反映的也是这个道理
const char* str1="Hello World";
const char* str2="Hello World";
//str1和str2地址相同
对于数据来说,如果数据不私有,造成的后果就是同一份数据在父子进程之间改来改去引起混乱
(2)进程终止
A:概述
操作系统终止进程的过程如下:
- 根据被终止进程的标识符,检索PCB,从中读出该进程的状态
- 若被终止进程处于执行状态,立即终止该进程的执行,将处理机资源分配给其他进程
- 若该进程还有子孙进程,则应将其所有子孙进程终止
- 将该进程所有用的全部资源归还给操作系统或其父进程
- 将其PCB从所在队列中删除
引起进程终止的事件主要有:
- 正常结束:表示进程的任务已经完成并准备退出运行
- 异常结束:表示进程在运行时,发生了某种异常事件,使程序无法继续运行。比如存储区越界、保护错误、非法指令、特权指令错误、运行超时、浮点异常等等
- 外界干预:指进程相应外界的请求而终止运行。比如操作员或操作系统干预、父进程请求或父进程终止
B:补充-僵尸进程与孤儿进程
上面所叙述的均是概述,并没有针对特定的操作系统,因此这里以Linux为例,展示一下在Linux中由于进程终止而产生的一些现象,加深同学们的理解。如果想要了解更多请移步:Linux系统编程10:进程入门之系统编程中最重要的概念之进程&&进程的相关操作&&使用fork创建进程
①:僵尸进程
简单点来说:僵尸进程就是子进程已经退出了,父进程还在运行当中,父进程没有读取到子进程的状态,子进程就会进入僵尸状态
使用下面的C语言程序模拟一个僵尸程序,子进程在10秒后利用exit退出,但是父进程一直在运行
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
// printf("还没执行fork函数时的本进程为:%d\\n",getpid());
pid_t ret=fork();//其返回值类型是pid_t型的
sleep(1);
if(ret>0)//父进程返回的是子进程ID
{
while(1)
{
printf("----------------------------------------------------\\n");
printf("父进程一直在运行\\n");
sleep(1);
}
}
else if(ret==0)//子进程fork返回是0
{
int count=0;
while(count<=10)
{
printf("子进程已经运行了%d秒\\n",count+=1);
sleep(1);
}
exit(0);//让子进程运行10s
}
else
printf("进程创建失败\\n");
sleep(1);
return 0;
}
效果如下,可以发现,在10s后,子进程已经退出,父进程还在运行

根据上面的定义,当子进程先退出,父进程还在运行,由于读取不到子进程的退出状态,所以子进程会变为僵尸状态。为了方便演示,使用下面的脚本,来每1s监控进程
while :; do ps axj | head -1 && ps axj | grep a.out | grep -v grep;sleep 1;echo "###########";done
效果如下,可以发现当子进程结束后,父进程还是在运行,此时进程太变为Z,也就是僵尸状态
那么为什么有僵尸进程呢?
其实道理也很简单,子进程是由父进程创建的,父进程之所以要创建子进程,其目的就是要给子进程分配任务,那么在这个过程中,子进程平白无故的没了,而父进程却不知道子进程到底把自己交给它的任务完成的怎么样,成功了还好,失败的话就能再交代一个进程去操作。
所以进程结束时一定要给父进程返回一个状态,父进程一直不读取这个状态的话,那么子进程就会一直卡在僵尸状态,其中像代码这些资源已经被释放,但是这个进程却没有真正退出,因为PCB还在维护它,直到父进程读取到它的状态,才能进入死亡状态
- 进程控制块中,一个进程退出后,还有一个退出码返回给父进程,如下是Linux内核中关于这部分的定义

- 在Linux中一行命令就是一个进程,那么这个命令的父进程是
bash,那么命令在结束的一瞬间也会给bash返回一个状态码,bash作为父进程,就是依靠这个返回码来判断命令是否正常结束,如果状态码为某一个值即可判定为没有这样的命令。在Linux中可以用echo $?来查看上一个输入命令的状态返回码,命令正确返回0,否则返回非0

②:孤儿进程
孤儿进程就是父进程没了,子进程还在。那么根据上面的僵尸进程,子进程在退出后由于没有父进程来读取它的状态,所以会一直卡在僵尸状态,那么这样就会存在一个问题,它的内存资源谁来回收,通俗点将就会造成 内存泄漏
修改上面的代码,让父进程先挂,如下
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
// printf("还没执行fork函数时的本进程为:%d\\n",getpid());
pid_t ret=fork();//其返回值类型是pid_t型的
sleep(1);
if(ret>0)//父进程返回的是子进程ID
{
int cout=0;
while(cout<10)
{
printf("----------------------------------------------------\\n");
printf("父进程运行了%d秒\\n",cout+=1);
sleep(1);
}
exit(0);//让父进程挂了
}
else if(ret==0)//子进程fork返回是0
{
int count=0;
while(1)
{
printf("子进程已经运行了%d秒\\n",count+=1);
sleep(1);
}
}
else
printf("进程创建失败\\n");
sleep(1);
return 0;
}
效果如下,这里还有一个现象就是,当父进程挂了之后,子进程一直在运行,并且ctrl+C,无法结束进程。这是因为ctrl+C此时结束的是父进程,但是父进程早已结束,子进程像孤儿一样四处游荡

除非使用killl才能将其杀掉
那么问题来了,这个进程难道一直要占用资源吗,其实操作系统在设计的时候就考虑到了这一步。所以一旦父进程先挂了,那么这个子进程就会被1号进程领养
依然使用下面脚本进行观察
while :; do ps axj | head -1 && ps axj | grep a.out | grep -v grep;sleep 1;echo "###########";done
效果如下,可以发现,当父进程挂了,这个进程的ppid,也就是父进程更换为了1号进程
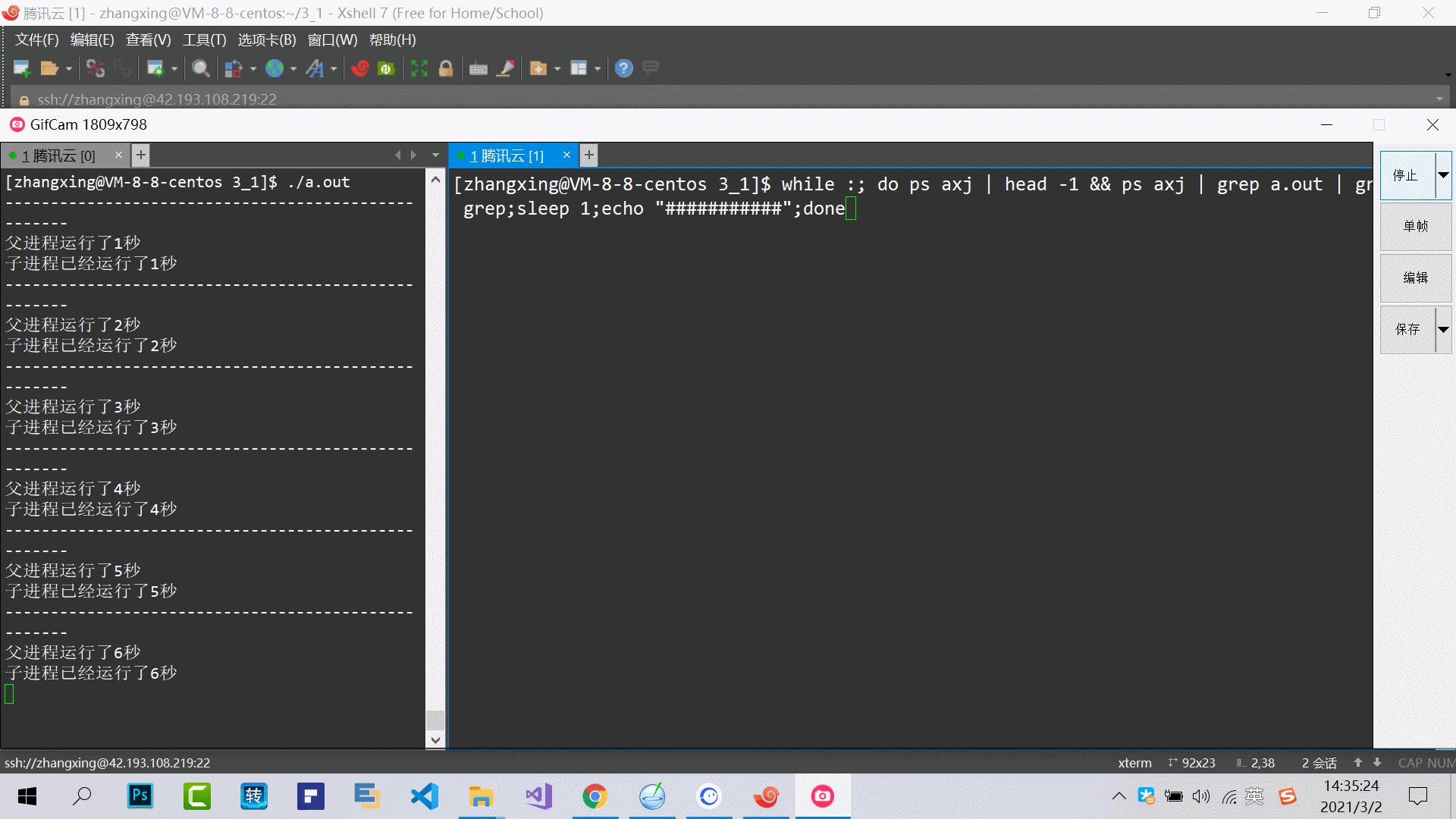
1号进程是什么呢,其实就是systemd

(3)进程阻塞(Block)/等待(Wait)
A:概述
进程阻塞执行过程如下
- 找到将要被阻塞进程的标识号对应的PCB
- 若该进程为运行态,则需要保护其现场,将其状态转换为阻塞态,停止运行
- 把该PCB插入相应事件的等待队列,将处理机资源调度给其他就绪进程
引起进程阻塞的事件有
- 需要等待系统分配某种资源
- 需要等待相互合作的其他进程完成工作
B:补充-Linux中的进程等待
上面所叙述的均是概述,并没有针对特定的操作系统,因此这里以Linux为例,展示一下Linux中的进程等待现象,加深同学们的理解。如果想要了解更多请移步:Linux系统编程17:进程控制之进程等待&&为什么进程需要被等待&wait方法和waitpid方法&&阻塞和非阻塞等待
①:为什么进程需要被等待/阻塞
前面的例子中说过,子进程退出后就变成了僵尸状态,一旦变成僵尸状态,这个子进程就如同僵尸一样,杀也杀不死(因为它已经死了),所以它必须需要让父进程读取到它的状态,回收子进程信息。只有这样,子进程才能得到“救赎”,“魂魄”才能归天,这属于进程需要被等待的一个典型例子
②:进程阻塞式等待
在上面的僵尸进程的例子中,修改代码子进程在10s后退出,父进程在10s后继续运行,运行至第15s,跳出循环,加入语句wailt(NULL)以回收子进程
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
// printf("还没执行fork函数时的本进程为:%d\\n",getpid());
pid_t ret=fork();//其返回值类型是pid_t型的
sleep(1);
if(ret>0)//父进程返回的是子进程ID
{
int count=1;
while(count<=15)
{
printf("----------------------------------------------------\\n");
printf("父进程运行了%d秒\\n",count);
count++;
sleep(1);
}
wait(NULL);//回收子进程
}
else if(ret==0)//子进程fork返回是0
{
int count=1;
while(count<=10)
{
printf("子进程已经运行了%d秒\\n",count);
count++;
sleep(1);
}
exit(0);//让子进程运行10s
}
else
printf("进程创建失败\\n");
sleep(1);
return 0;
}
如下可以发现,当父进程将子进程回收后,僵尸进程也消失了

如果父进程里只写上wait(NULL),那么就表示父进程阻塞在这里,等着子进程死亡,回收子进程
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
// printf("还没执行fork函数时的本进程为:%d\\n",getpid());
pid_t ret=fork();//其返回值类型是pid_t型的
sleep(1);
if(ret>0)//父进程返回的是子进程ID
{
printf("父进程正在等待子进程死亡\\n");
wait(NULL);//进程阻塞
printf("子进程已经死亡,父进程退出\\n");
exit(0);
}
else if(ret==0)//子进程fork返回是0
{
int count=1;