一幅画是不是真迹?AI比专家看得更明白
Posted 程序员的店小二
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一幅画是不是真迹?AI比专家看得更明白相关的知识,希望对你有一定的参考价值。
在这个紧要的关头,深度学习技术终于踏入了艺术领域。
编者按:2011年,马克•安德森写了一篇著名的文章:软件正在吞噬世界。如今,全球正被其中的一种特殊的软件所吞噬:深度学习。这种软件使机器能够处理一些在几年前还被认为是计算机无法处理的任务,包括驾驶汽车和医疗诊断。我们准备在这个名单上再添一项惊人的壮举——识别伪造画作。计算机能够帮助专家鉴定艺术品,这是斯蒂芬·弗兰克和安德莉亚·弗兰克夫妇努力的结果。他们开发了一种卷积神经网络,可以评估一幅画,甚至是一幅画的一部分,是由目标画家完成的概率。他们最近用这种神经网络来评估列奥纳多·达·芬奇的《救世主》的真假。2017年,这幅画在佳士得拍卖会上以4.5亿美元的价格成交,成为有史以来最昂贵的画作。

要对达芬奇的画作进行分析,首先需要把高清的原画分割成一片片相互重叠的切片区域,并且这些切片需要含有足够的有效信息来进行分析,正如图中所显示的。之后作者会利用他的系统来对这些切片进行学习和分析。图片来源: CORBIS/GETTY IMAGES
2017年11月15日,英国佳士得拍卖行的香槟瓶塞砰砰作响,震耳欲聋。一幅名为《救世主》(Salvator Mundi)的耶 稣肖像在纽约佳士得拍卖行以4.503亿美元的价格售出,成为迄今为止成交价最高的画作。
但是,即使在锤子落下的时候,仍有很多人在质疑这幅画真的是文艺复兴时期杰出大师列奥纳多·达·芬奇(Leonardo da Vinci)的作品吗?50多年前,一位来自路易斯安那州的男子在伦敦仅花了45英镑就买下了这幅画。而从1909年到《救世主》重见天日之前的这段时间,根本就没有出现过达芬奇的真迹。
一些持怀疑态度的专家看了这幅画的历史销售和转让记录以后,开始质疑这幅作品的来源,他们指出,这幅严重受损的画作进行过大规模的修复。还有一些人觉得这幅画出自达芬奇的徒弟而非达芬奇本人。
从专家们的唇枪舌战和一系列不完整的证据中,我们真的可以确定一件艺术品的真伪吗?先进的测量技术可以确定一幅画的年代、揭示暗藏的细节,但并不能直接确定其创作者。这项工作需要对风格和技术进行微妙的判断,所以似乎只有专家们才能胜任。但事实上,这项任务非常适合计算机分析,特别是神经网络这一擅长检查模式的计算机算法。用于分析图像的卷积神经网络(CNN)已经得到了很广泛的应用,比如人脸识别和自动驾驶。那么,为什么不用它们来鉴定艺术品呢?



作者将他的神经网络应用在了一副伦勃朗的画(上)、一幅曾经被认定是伦勃朗的画(中)和列奥纳多的《救世主》(下)这三幅画作上。图片上用类似热成像的显示方法显示了不同部分为真迹的概率,颜色越接近红色就越代表这些区域是算法认为的可能是由艺术家本人绘制的部分。图片来源:史蒂文和安德里亚·弗兰克
这是我在2018年问妻子安德莉亚 M. Frank的问题。她是一位专业的艺术策展人。虽然我职业生涯中的大部分时间都在做知识产权律师,但我对网络教育的痴迷程度最近达到了顶峰,并且还获得了哥伦比亚大学人工智能专业的学士学位。刚好安德莉亚最近正考虑从原来的工作退休,所以我们决定一起接受这个新的挑战。
我们从回顾用神经网络分析绘画的障碍开始,很快确定了其中最主要的几个。首先纯粹是尺寸问题:一幅高分辨率的绘画图像对于传统的CNN来说太大了,但是适合CNN大小的较小的图像可能缺乏支持鉴别所需要的信息。另一个障碍便是数据库。神经网络需要数千个训练样本,这远远超过即使是最高产的艺术家穷尽一生所能创作的画作数量。由于这些障碍的存在,电脑技术在解决画作真伪问题这方面的作用显得微乎其微。
尺寸问题并不是艺术图像所独有的,被病理学家用来检查癌症和其他病症的数字化活检切片也包含着大量像素。医学研究人员的解决办法是,他们将这些图像分解成更小的碎片,例如正方形的切片,以便于CNN处理。这样做还可以帮助解决数据库的问题,因为这样一来就可以从单个图像分割出大量训练样本,特别是当切片可以水平或垂直重叠的时候。当然,这些样本切片中有很多多余的信息,不过事实证明,拥有足够的样本数量才是最重要的,因为,在训练神经网络时,数量就是质量。
如果可以在艺术品鉴定中应用这一技术的话,那么接踵而至的问题就是决定应该用哪些图像来作为训练样本。《救世主》这幅作品中既有图像信息十分丰富的区域,也有缺乏足够视觉信息的背景区域,而这些缺乏信息的区域会给训练造成极大的困难。比如,如果由于达芬奇不在乎签名而导致签名信息的缺乏,或者有很多艺术家们都喜欢采用同样的渲染背景的方式,那么CNN将会被误导,这样一来,它划定真迹的能力就会受到影响。
我们需要一些标准来帮助我们识别有足够图像信息的样本,以及那些可以被电脑自动且一致地应用的样本。我认为信息理论或许能提供一个解决方案,或者至少为我们指明方向。每当我开始进行数学计算时,安德莉亚的眼睛就会变得呆滞,但这一领域的先驱Claude Shannon是一位独轮摩托车制造商,他制造的产品包括火焰喷射喇叭和火箭动力飞盘,所以,如果他都可以做到的话,我们应该也差不到哪里去。
信息理论的一个支柱就是熵的概念。当大多数人想到熵的时候,他们想到的是物体分裂成无序状态。Shannon却认为这是一种很有效率的通过电线传输信息的方式。信息包含的冗余越多,就越容易压缩,那么发送它所需的带宽也就越少。能够被高度压缩的信息具有低熵,而另一方面,高熵信息却无法被压缩,因为它们具有更多的独特性、更多的不可预测性和更多的无序性。

图片来源:Pexels
像文字一样,图像也携带信息,它们的熵同样表明了它们的复杂程度。一个全白(或全黑)的图像的熵为零,所以在这种情况下,记录大量的1或0是完全多余的。以及格纹,虽然视觉上格纹看起来比一条单独的对角线要复杂,但从可预测性的角度上来说,格纹其实并不复杂,这意味着它只多出来了一点点熵。不过当然,一幅静物画的熵要比黑白画和格纹大得多。
不过,认为熵就等同于图像中的信息量这一想法也是错误的。即使是非常小的图像也可能有很高的熵,所以,熵反映了图像信息的多样性。作为团队中数学最差的那个人,我突然想到,我们可以在努力消除背景和其他缺乏信息的区域时,排除掉那些低熵的部分。
我们从荷兰大师伦勃朗的肖像画开始,几个世纪以来,他的作品的归属问题一直很有争议。训练CNN识别伦勃朗真迹显然需要一个数据集,其中包括伦勃朗的一些画作和其他人的一些画作。但是,收集这些数据集也带来了一个难题。
如果我们随机挑选50幅伦勃朗的肖像画和50幅其他艺术家的肖像画,我们就可以训练出一套系统来区分伦勃朗和毕加索,而不是伦勃朗和他的学生以及崇拜者(更不用说那些伪造者了)。但是,如果我们的训练样本都集中于伦勃朗的真迹和仿制品中的话,CNN就会过度拟合。也就是说,它不能很好地概括其训练之外的内容。所以安德莉亚开始收集非伦勃朗作品的数据集,其中包括一些非常接近伦勃朗的作品,以及一些让人可以联想到伦勃朗但又容易与真品区分开来的作品。
然后我们还需要一些额外的选择。如果我们要把伦勃朗的画切成片,且只保留那些熵足够高的部分的话,那么我们的熵截断点应该是什么?我认为一片切片至少应该有和一幅完整图像一个数量级的熵,这样才能进行可靠的分类。实践证明我的想法是正确的,根据不同的作品,我们需要将熵阈值与画作的特征联系在一起。这是一个很难达到的标准,通常只有不到15%的切片符合标准。不过这个问题很好解决,我们可以增加相邻切片之间的重叠部分,以达到训练所需的切片数量。
这种基于熵进行选择的结果从直观上来看是有意义的。确实,那些真迹是人为鉴定过的,通常情况下,电脑会捕捉专家们在判断一幅画的作者时所依赖的特征。以《救世主》为例,选定的切片部分覆盖了耶 稣的脸、侧面卷发和手,这些全是学者们对这幅画的作者进行争论时的焦点。
接下来要考虑的是切片的大小。在标准硬件上运行的常用CNN可以轻松处理从100 × 100像素到600 × 600像素的图像。小一些的切片可以把分析限制在精细的细节上,而使用大的切片会有导致CNN过度拟合到训练数据上的风险。但最终只有通过反复训练和测试,我们才能为特定的图像确定最佳的切片大小。对于伦勃朗的肖像画,我们的系统使用450 × 450像素的切片效果最好,这大约是主体的脸的大小,所有的其他切片都会缩放到相同的分辨率。
我们还发现简单的CNN设计比更复杂(和更常见)的设计效果更好。所以我们决定使用只有五层的CNN。安德莉亚精心挑选的数据集包括76幅伦勃朗和非伦勃朗画作的图像,我们将这些图像以四种不同的方式组合成了51幅训练图像和25幅测试图像。这允许我们“交叉验证”结果,以确保跨数据集的一致性。我们的五层CNN学会了将伦勃朗与他的学生、模仿者和其他肖像画家区分开来,准确率超过90%。
受到这次成功的鼓舞,我们打趣地给勇敢的小CNN起了个名字叫“A-Eye”,并把它用在另一位荷兰天才画家文森特·梵高的风景画上。我们选择梵高是因为他的作品与伦勃朗的截然不同。梵高更在意情感而非考究,所以他的笔触大胆而富有表现力。这一次,我们的数据集包括了152幅梵高的和非梵高的画作,用四种不同的方式把他们分成了100幅训练图像和52幅测试图像。
A-Eye在梵高的作品中表现得很好,在我们的测试中再次表现了很高的准确性,但必须要用小得多的切片。表现最好的那一部分只有100 x 100的像素,大约只是一笔的大小。艺术家作品的“经典”尺度——也就是CNN对其进行准确分类的尺度——对不同艺术家来说是独特的,至少在肖像画和风景画等流派中如此。
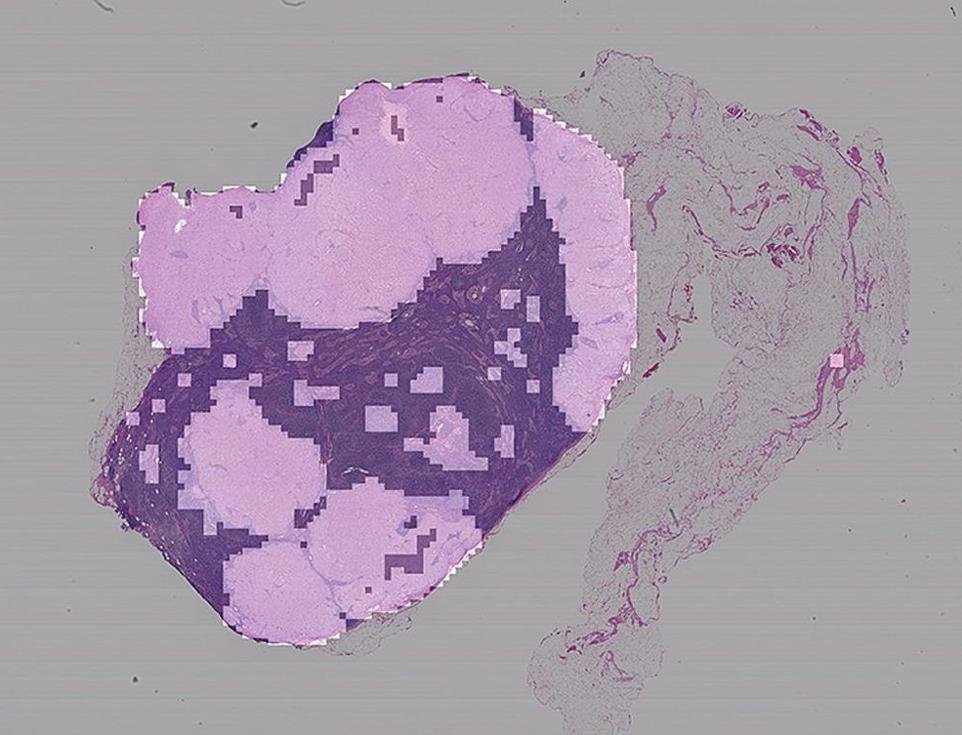
在显微镜载片上,粉红色部分表示神经网络认为的可能是病变的组织。图片来源:史蒂文·弗兰克
使用CNN来分析艺术品的挑战也困扰着医学图像的自动化分析,尤其是病理学家用来分析癌症和其他疾病迹象的大量组织样本的全幻灯片图像(WSIs)。这些图像可能有数十亿像素大小,通常需要在功能强大的工作站上观看,这些工作站可能直接由幻灯片扫描仪集成。目前,人工智能的应用还需要向全尺寸图像努力,研发更专业的硬件,如强大的图形处理单元来进行处理分析。这些努力也受到“黑匣子”问题的影响:如果计算机只是对切片进行分类,病理学家们该如何确定它是否找对了地方?
相对于一个巨大的WSI而言,CNN能分析的最大的切片的大小也是远远不够的。病理学家该如何确定他们可以准确捕捉到那些对诊断至关重要的解剖结构?肿瘤细胞可以熟练地伪装自己,疾病的线索可能潜伏在它们的外部,其形式可能是周围组织的组成变化或附近免疫细胞异常,因此判断性特征并不总是可用于判断的。
图像熵可能会有所帮助。图像缩放和切片大小可以作为“旋钮”,不断调整直到达到分类精度的峰值。训练和测试一系列图像和切片大小,就像我们对绘画作品所做的那样,可以让CNN区分病变和正常组织,甚至是各种形式的疾病。虽然我们已经在用图像熵来确定最具判断力的切片,并用他们来训练我们的神经网络,但在医学领域,以肿瘤为例,以这种方式识别的切片甚至可以在CNN分析之前,以组合的方式提供相当不错的判断。——S.J.F.
CNN到底是如何找到关键细节的,它在做判断时“看到”了什么?这些都不好确定。CNN的business端(实际上是它的中间部分)是一系列卷积层,逐步将图像消化成细节,然后以某种不可思议的方式进行分类。这一黑箱特性是人工神经网络面临的一个众所周知的挑战,尤其是那些分析图像的神经网络。我们所知道的是,当对大小合适的切片进行训练时,CNN可以可靠地估计出与每个切片对应的画布区域为真迹的概率,我们可以根据不同切片的概率将这幅画作为一个整体进行分类——最简单的方法是找到它们的总体平均值。
为了更精细地计算每一个像素为真迹的概率,我们可以计算包含这个像素的所有切片的平均真迹概率,以确定该像素最终的真迹概率,然后得到一幅概率图,显示不同的像素有多大的几率是出自目标画家之手的。
画布上的概率分布具有指导意义,特别是对于已知(或怀疑)曾与助手合作的艺术家,或那些画作被损坏后又被修复的艺术家。例如,伦勃朗的妻子萨斯奇亚·范·尤伦伯格的肖像画在我们的概率图中就有一些令人生疑的地方,尤其是脸部和背景。这与研究伦勃朗的学者们观点一致,他们认为这些区域后来被伦勃朗以外的人覆盖过。
尽管这些发现具有启发性,但那些被计算机划分为真迹概率低的区域并不代表一定就不是真迹,因为这些区域可能是艺术家大胆的、不符合平时风格的实验的结果,甚至有可能只是因为那天艺术家的心情不太好,或者是简单的分类错误。毕竟,没有一个系统是完美的。
我们对自己的系统进行了测试,对伦勃朗和梵高的10幅作品进行了评估,专家们一直在激烈争论这些作品的归属问题。不过,我们的分类标准符合当前学术界的共识。因此,我们有勇气迎接更大的挑战----评估《救世主》。我们认为这项任务极具挑战性的原因是目前确定属于达·芬奇的画作太少了(不到20幅)。
最终,我们还是得到了一些切片,并生成了一张概率图。我们的研究结果认为这幅画的背景和祝福之手可能并不是达芬奇画的,这与这幅画经历过大规模的修复的说法是一致的,其中包括对背景的彻底重绘。同时,专家们在谁画了祝福之手这个问题上存在严重分歧。

2017年花4.5亿美元买下《救世主》的买家是匿名的,这幅画目前下落不明。但有报道称,它现在在沙特王储穆罕默德·本·萨勒曼的超级游艇“宁静”号上。图片来源:颜孟德/法新社盖蒂图片社
在我们的方法建立了一定的可信度之后,我们的野心也逐渐增长。我们系统检测出来的结果与目前学界普遍认为的结果之间差距较大的是一幅名为《戴金色头盔的人》(the Man With the Golden Helmet)的画作。长期以来,这幅画一直受到人们的喜爱,因为它是伦勃朗的一幅特别引人注目的作品。1985年,它的所有者柏林国家博物馆(Staatliche Museum)不再认为这幅画出于伦勃朗之手,因为博物馆的学者们认为这幅画在绘画处理上和伦勃朗已知的工作方式很不符。
这幅画现在被认为是一位不知名的“伦勃朗圈子”画家的作品,在公众的心目中,它的光彩已经褪色,只剩下那个忧郁的士兵戴着的那顶壮观的头盔还在闪闪发光。但我们的CNN系统强烈认为这幅画出自伦勃朗之手。此外,我们的整体研究结果提醒我们不要将伦勃朗的作品归因在精细的表面特征上,因为将CNN的分析范围缩小到这些特征的做法会使得整个预测结果跟瞎猜的一样。我们希望,有一天,画中的这名士兵可以重拾自己的荣耀。
图像熵是一个多功能的助手。它可以识别出复杂图像中最能代表整体的部分,使即使是最大的图像——包括医学图像(参见上文)——也能接受计算机分析和分类。随着训练的简化和对大数据集的需求的减少,小型CNN也可以发挥更大的作用。

史蒂文和安德烈·弗兰克 图片来源:IEEE
译者:36氪 神译局 扣人心
以上是关于一幅画是不是真迹?AI比专家看得更明白的主要内容,如果未能解决你的问题,请参考以下文章