从中台模式的式微,到ChatGPT的兴起
Posted dotNET跨平台
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从中台模式的式微,到ChatGPT的兴起相关的知识,希望对你有一定的参考价值。
LLM如ChatGPT近期红的发紫,一线研发人员都感到了巨大的机会和危机感。但本文打算另辟蹊径,探讨这类技术,对互联网公司算法研发架构上的影响。
本文试图回答两个问题:近两年中台模式,尤其是算法中台逐渐地淡出。其背后原因是什么? 在chatGPT大红大紫和LLM爆发前夜,对中台和算法团队组织架构的影响是什么?
中台模式在2017年后大红大紫,成为一些大型互联网公司重要的组织能力经验对外输出。讨论此话题的文章汗牛充栋。 几年前,笔者也写过一篇《中台模式的爱与恨》,其中的观点在此处不再赘述。
笔者认为,就像生产力决定生产关系一样,算法研发模式,与技术和业务发展状态密不可分,从这个角度入手能回答这个问题。我们可以将技术业务的发展绘制成如下的曲线。如果你对中台发展历史的梳理不感兴趣,可直接跳到本文最后一节,我们会谈大型语言模型对算法研发可能带来的颠覆。

中台兴起(2015-2018):技术和业务的先后崛起
2011年移动互联网浪潮兴起,大众创业万众创新,而在2014年-2015年,人工智能尤其是深度学习,有了革命性的突破。彼时的“大数据”还不是个贬义词,很多传统行业逐步完成了数字化转型,但还远远谈不上“智能化”。在互联网科技公司,这股风潮从CV开始,刮向推荐系统和NLP等等。
人们的换机潮,伴随着移动互联网的起飞和以及技术红利,正值各个公司的业务遍地开花,多得做不过来:个性化搜索推荐,图像/视频智能识别,物联网,智能硬件等等,成为智能化的标准名片。
深度学习人才需求旺盛,但人才供给却跟不上;在业务上如何智能化,是每个管理者必须回答的问题,但又很难在短时间内组建算法团队适应需求。上面的业务可以通过领域拆分成多个横向和纵向,进而有相当大的部分可被复用。因为中台团队可以以很低的成本,快速复用和试错, 成为了中台兴起的关键原因。
中台的出现还有一些必备条件,在一些公司,那些强势话语权业务比如百度的搜索,一定会自建强大的技术团队,反而就难于新成立中台,反倒是后续会承担一部分中台角色给其他团队。 业务驱动而非技术驱动的,以及各个业务相对平均的地方,更容易孵化出中台团队。
如《中台模式的爱与恨》所述,那些有一定的壁垒,但离业务很近的算法技术最容易沉淀到中台。 而通用微服务化,docker化,使得组件复用变得更加容易。太高端还无法大规模应用的技术就不太行,比如量子计算和类脑接口,那是研究院干的事情了。
中台是中心化的,它服务业务,与此同时培养人才,沉淀能力和平台,算法中台甚至是一家公司的技术名片,有着相当中台特色的阿里达摩院也在2017年成立。这是中台的黄金时代:一个中台算法同学支持的业务,在6年后,反而需要30个人来支持。
中台式微(2018-2020)
在技术上,AI的核心架构,在2018-2019 年趋于成熟,主要的范式如在线学习,强化学习等等也得到了比较充分的验证。但此时AI的关键创新技术落地却慢了下来:以目标检测为例,新算法更快更准,但并不会对之前的方案产生颠覆性的变化。
在业务上,逐渐从技术引领转换为业务引领。大家更关注于技术的落地情况, 增长和盈利能力。 业务开始变得成熟, 智能化浪潮席卷方方面面:绝大部分核心流量场景接入算法。业务线开始变得强势。由于业务线承担主要的盈利能力,更容易形成逻辑闭环,技术推进更容易。
在人才方面,以三年为单位,大量研究生转战算法,人才缺口补上了,甚至有些供过于求了,算法校招常见“灰飞烟灭”的词语。 由于中台的很多技术已经得到了验证,而中台能做的事情,业务线招几个人一样能搞,搞的还不一定比你差。业务线逐渐对中台形成了人才虹吸效应。中台老板在年会上淡淡地说,“我们培养一批,送走一批。”
为了进一步提升中台的服务能力和稳定性,中台开始全面的平台化,产品化,直到商业化,总结起来就是:对内封闭,对外开放。将诸多产品能力进行组合打包,提升接入效率,并通过一整套工具链绑定用户。除了服务内部用户,也逐渐开始服务外部合作伙伴,以提升影响力。
关于中台模式,引发了很多的撕扯和故事。最经典的吐槽是这样的:提需求给你,你排期遥遥无期;我们自己做,你又投诉我们重复建设和抢活,你要我怎么做?好不容易等到排期了,啊,说好的现炒呢?怎么成了预制菜了?食之无味弃之可惜,一套能力改都不改到处拿来用,忽悠人呢? 而中台则同样不爽, 还把我们当高级外包?我要接几十个需求,怎么能忙得过来?
后中台时代(2021-):去中心化的委员会模式
中台模式的没落,同样与技术和业务情况密不可分。
在技术上,技术方向的拆解远比几年前精细,全面内卷,从用户到供给理解,连多任务都被解构成N个方向分别优化,业务团队也逐渐追求技术原创性,大量发论文已经不是稀罕事情;AI通过开源运动,已经民主化了,当路边大爷都知道Bert的时候(这是笔者亲历的真事儿),算法本身的门槛已经很低了,变成了算力和数据的竞争。那些没有业务的纯服务型团队逐渐凋零,这种例子数不胜数。
在业务上,2020年的短暂股价狂欢后。疫情和经济下行,互联网业务开始下滑,去肥增瘦成为主旋律。肉都不够分,公司还要养中台?最后,监管合规要求,非公司实体员工,在法律上无法接触对应的数据,这成为了压倒中台的最大一根稻草。那么,索性就让我们打平吧!
具体地,组织结构开始扁平化+ 去中心化,变成了各个垂线+ 技术委员会。 如下图所示,一个团队在业务初期可成为技术需求方,接受其他团队的帮助;在业务成熟,技术模式跑通之后,便成了技术提供方,反哺他人。所谓穷则独善其身,达则兼济天下。通过委员会模式,它与组织结构与业务松绑, 跑下来有着相当的灵活性。
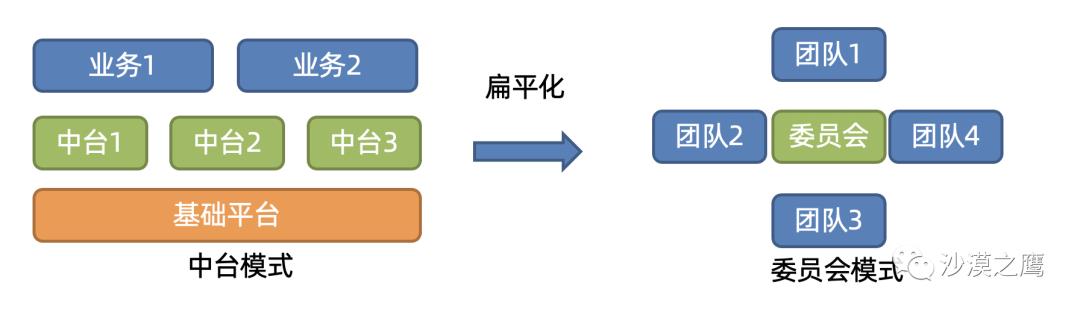
委员会模式一定程度解决了信息互通,大家会互相知道在做什么,有什么需求和问题。这相比于中台是一个巨大的进步。因为中台本质上是CS架构,卖家并没有动力让买家之间相互沟通联系。而委员会提供了互相合作的土壤,当发现有共同的命题,就会促使团队间紧密合作。开源代码 + benchmark框架+ 论文,就成了委员会的公共财产。
其弱点也很明显,我们也不清楚,技术委员会有没有业务决策权。因为似乎委员会很难对项目和方向节奏做干预,更多是一种信息的单向传播。因为在商业公司,业务和利润是王道,没有业务决策权,那就只剩技术沟通了。大家坐在一起聊聊最近的技术成长和心得,如同开学术会议一样,简单纯粹而美好。但相信我,重复建设是一定会重复建设的,只不过之前互相撕扯,抢地盘抢得飞起;现在互相客客气气地介绍经验,你有是么?啊呀我也有!一切都是那么美好。
然而,问题并没有被解决
不论是中台还是委员会模式,都是在特定的技术业务条件下产生的。那委员会是否就是终点?中台还能否再次兴起?是否还有更好的技术合作组织形式? 这些问题,本质是关于人员沟通和算法复用的,有几个关键问题:
首先,算法的复用是很艰难的。工程合作是非常明确的,大家面向接口,各司其职,如同建筑工地一样对系统进行组装。算法合作不然,算法同学很独立,这是因为人们沟通效率的限制,每个协作者必须清晰地理解算法里面的逻辑,否则就是瞎帮忙。同时,几种优化的叠加不一定是线性的,可能会起到副作用,难于拆分具体的贡献。
其次,可复用组件,必须满足使用者可理解和可优化。解决问题只是一方面,而让技术同学理解,改进和提升模型,则是另一个刚需,没人愿意做调包侠。这也是晋升要求反向梯度回传导致的必然结果。完全的黑盒看似屏蔽了调用复杂性,但却难于被理解,进而一定会被摒弃,算法同学很快就会自己开发一个新的模块出来代替它。
那不复用行不行?不行! 在扁平化的委员会后后,人们依然呼唤复用:很容易看到,公司养着这么多的算法团队,带来了极高的人力成本;而绿色计算和可信公平成为共识。分散式的多小队并行开发,不可避免地追求复杂化,导致越来越大的人力和计算消耗。完全松散的模式变得不可持续。
那么,未来是怎样的?
未来:大型统一模型的颠覆?
对未来算法研发模式的判断, 笔者站在2023年年初,提出了三种可能性。
一种可能性是,疫情结束,经济形势全面复苏,业务重新开始爆发式增长。那么就能复刻前面第一和第二阶段的故事,传统意义上的算法中台重新崛起。但从现状来看,这种可能性在3年内很低。
第二种可能性,也是笔者认为可能性更大的,就是革命性的算法解耦技术在业务上的落地。现有的pretrain+ finetune范式已经在CV/NLP领域大规模应用,但其缺点还是明显的:可解释性较差,我们并不非常清楚模型是怎么工作的;数据有效性较低,下游需要大量的数据才能finetune出可用的结果;在搜推广(ASR)上并不好用,而ASR是比CV/NLP更直接的业务落地方式。
2023年年初,chatGPT这样的LLM像一声惊雷,其超强的零样本泛化、上下文学习,以及复杂推理和人类指令响应能力让无数从业者惊叹。这让从业者意识到,拒绝回答和公平性等特性的引入,让模型本身不再成为玩具;多个小模型分别优化,远远没有在一个大模型上进行微调和反馈来得强大;思维链实现的数学和符号推理,甚至让传统的符号系统颤抖,工业控制,商业决策等等的方向的落地似乎不是幻想。一个全新的、颠覆性的技术变革,可能即将来临。
让我们大胆畅想下,一个统一的,基础算法服务团队,能够将基础知识图谱,自然语言和全域用户行为进行深度编码,构建一个通用的,组合式的,可分别升级和调试的基础统一模型。这个团队,就是新研发范式下的“新中台”!他们维护和优化着大型模型,超大规模数据和算力。按照《中台模式的爱与恨》一文所述,中台会变得下沉和“左倾”。
基础统一模型变成了像数据库一样的模块,而上层应用团队仅通过一套专用的DSL(领域定义语言)书写业务逻辑,和仅收集少量的高质量样本。在超大规模统一模型的基础之上, 即可构建可解释的,无偏的,绿色的领域模型。此时, “算法架构”被赋予新的含义,姐夫的“pathways”可能所言不虚,人力和资源消耗可能能减少90%以上。 就像docker模式改变工程架构开发一样,它会颠覆现代算法设计的方方面面 。
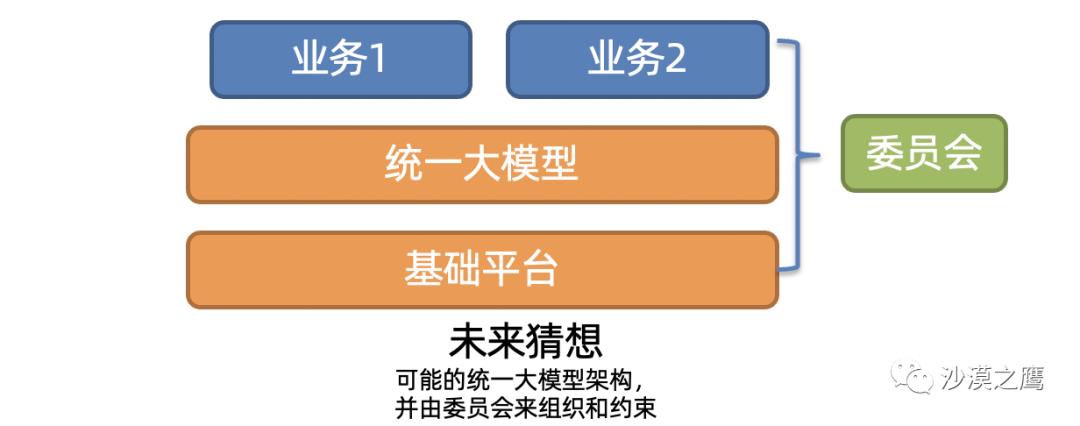
在可见的未来,如果One-model(统一大模型)+ model as service(模型即服务)+ 配合内源/开源+ 委员会的统一协调模式,能够获得大规模的应用,如果基础模型和其他部分能插件式拼接,算法效果能够达到甚至超过线性叠加。那必然会引起新的算法合作的升级迭代。 笔者预期,这个目标会在两年内实现。
让我们更大胆一点, 向10年-20年后预测。 复杂的业务,算法和平台语义可能会被人类全部抽象成语言和指令,进而可由LLM处理和优化,算法工程师被大规模代替;更近一步,就像《流浪地球2》那样,超强算力的量子计算机通过观察,直接生成了操作系统,亦即生成了语言本身,并直接在上层进行控制和优化,那么就会像电影表现的那样,生产力极大提升,同时伴随着社会大规模的失业; 然而语言只是形式,而非世界运行的本质,而目前大型模型为了支持人类语言对齐,反而拉低了其性能;最终,大型模型就会抛弃“语言”这种与人类沟通的低效形式,成为人类无法理解的黑盒,通过自反射甚至自编译,不断优化自身,进而走向真正的强人工智能,末世电影中的情节可能终成现实。
第三种可能性,如果连统一大模型都没有更多进展呢? 那,那,拉回到现实,大家就在委员会模式下,赶紧看看手头到底推全了几次,水了多少论文,接着卷吧。

以上是关于从中台模式的式微,到ChatGPT的兴起的主要内容,如果未能解决你的问题,请参考以下文章