[网络安全提高篇] 一一二.DataCon Coremail邮件安全竞赛之钓鱼邮件识别及分类
Posted Eastmount
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[网络安全提高篇] 一一二.DataCon Coremail邮件安全竞赛之钓鱼邮件识别及分类相关的知识,希望对你有一定的参考价值。
这是作者2020年参加清华大学、Coremail、奇安信DataCon举办的比赛,主要是关于钓鱼和异常邮件识别研究。非常感谢举办方让我们学到了新知识,DataCon也是我比较喜欢和推荐的大数据安全比赛,这篇文章2020年10月就进了我的草稿箱,但由于小珞珞刚出生,所以今天才发表,希望对您有所帮助!感恩同行,不负青春。

微步情报局C&C资产进行拓线关联发现 “白象三代”组织在2019年期间用于钓鱼攻击的资产域名:ioa-cstnet.org。该域名在2019年3、4月期间曾被用于伪装成中国科学院计算机网路络信息中心管理员对该所人员发起鱼叉式攻击活动,试图窃取科研人员邮箱账密。钓鱼邮件如下所示,因此鱼叉式钓鱼攻击越来越多,其安全防御也非常重要。

文章目录
作者作为网络安全的小白,分享一些自学基础教程给大家,主要是关于安全工具和实践操作的在线笔记,希望您们喜欢。同时,更希望您能与我一起操作和进步,后续将深入学习网络安全和系统安全知识并分享相关实验。总之,希望该系列文章对博友有所帮助,写文不易,大神们不喜勿喷,谢谢!如果文章对您有帮助,将是我创作的最大动力,点赞、评论、私聊均可,一起加油喔~
- 自学篇工具:https://github.com/eastmountyxz/NetworkSecuritySelf-study
- 系统安全:https://github.com/eastmountyxz/SystemSecurity-ReverseAnalysis
声明:本人坚决反对利用教学方法进行犯罪的行为,一切犯罪行为必将受到严惩,绿色网络需要我们共同维护,更推荐大家了解它们背后的原理,更好地进行防护。该安全系列原文github已开源,如果喜欢也可以支持作者,赚点奶粉钱,哈哈。
题目背景
竞赛简介
在网络空间日趋激烈的对抗和渗透活动中,电子邮件作为工作和生活中常见的一类基础应用,是网络攻击“战役”中必须暴露在炮火之下的桥头堡。事实上,电子邮件一直是网络攻击者常用的攻击渠道,也常常成为许多高级持续威胁(APT)攻击的重要一环。钓鱼邮件、勒索邮件、病毒邮件等威胁始终是网络安全面临的主要挑战之一。与邮件安全相关的攻击与检测,两者之间的博弈将长期持续。
然而,与日趋复杂的邮件攻击技术相比,邮件安全防御技术相对滞后,在安全人才方面也存在巨大的缺口。清华大学网络研究院和邮件服务提供商Coremail论客、安全厂商奇安信集团一同合作,通过大数据安全分析竞赛DataCon平台,推出了国内首个邮件安全分析竞赛。

本次竞赛旨在通过提供大量贴近于企业生产环境下的真实数据和应用场景,鼓励参赛选手充分挖掘邮件数据的安全价值,灵活运用多样化的安全检测方法,对邮件数据中不同类型安全威胁进行检测分析。本次竞赛的目的是提升参赛选手的安全能力和实战经验,培养和选拔熟练掌握数据安全分析能力的人才。
-
主办单位
清华大学 | Coremail论客 -
协办单位
奇安信集团 | DataCon社区 | InForSec论坛
赛题二:明察秋毫
1.题目介绍
赛题说明
某家企业希望根据根据邮件内容类型的不同,采取差异化的邮件过滤策略。譬如在邮件服务器上直接拦截所有勒索欺诈类邮件,而对于一般的推广营销类邮件,则移入用户邮件的垃圾箱中。
为实现上述差异化的邮件过滤策略,请参赛选手分析邮件日志数据,设计分类模型,实现针对邮件类型的分类。注意:检测方法既可以是基于规则的,也可以是基于学习的。
数据说明
赛题数据目录为 /home/datacon/coremail/challenge_2 赛题二的数据为24000封真实生产环境下的邮件日志。每个邮件日志均有唯一的ID编号,并包含非常丰富的细粒度字段信息。部分数据字段的具体含义如下表所示。
| 数字字段 | 具体含义 | 数据字段 | 具体含义 |
|---|---|---|---|
| @timestamp | 时间戳 | mid | 邮件内投最终的mid |
| attach | 邮件附件名列表 | rcpt | 收件人email列表 |
| authuser | 是否为本站用户 | recviplist | 信头的Received:提取的IP地址列表 |
| content | 邮件内容(前512字节) | regionip | 从信头提取的X-Orginal-IP之类的原始的发信人IP(而不是服务器IP) |
| doccontent | Office类型邮件附件的文档信息 | sender | 发信人 |
| dwlistcnt | 命中域名自动白名单的rcpt数量 | subject | 邮件的主题 |
| from | 信头的from信息 | url | 邮件中包含的URL链接(可能包含手机号码/qq号码和其他一些非URL信息) |
| fromname | 信头的fromname | wlistcnt | 命中自动白名单的rcpt数量 |
| htmltag | 邮件包含的html tag | xmailer | 信头xmailer信息 |
| ip | 连接到Coremail 服务器的IP | licenseid | 请求的客户端的licenseid |
| region | regionip的地理位置 |
注意事项:
- 请注意:赛事主办方不会对邮件日志中数据字段予以额外的解释说明。
- /home/jovyan 目录用于放置希望持久化的各种数据,例如选手的代码、运行所需的第三方库等等。
提交规则
请各参赛队伍自行设计算法,区分邮件日志的不同类型,将邮件的编号以及所属类型写入指定的文件中,即/home/jovyan/result2.csv。
选手应当提交CSV格式的文件,CSV的列名分别为:
- email_id, spam_type
文件之中每行均应包含两列,邮件日志编号和类型代码(用逗号进行连接),不同邮件编号按行进行分隔(分隔符为“\\n”)。指定文件目录下已经内置一个提交示例(result2.demo.csv),供参赛队伍参考。 由于邮件日志中所含有具体类型,其规模并不确定。因此请参赛队使用从1开始递增的阿拉伯数字(1,2,3,…,10,…)来表示邮件日志的不同类型。使用其它代码进行表示不得分。
请注意:同一个邮件日志不会同时属于两个及以上的类型,参赛选手提交的文件中若某个邮件日志同时包含在多个类型之中,评分时将以文件中第一条出现的结果为准。 选手在本次竞赛的持续时间内,每日提交次数不限。主办方将不定期进行阶段性评分,将队伍本题的得分以及所处的排名信息反馈给参赛队伍。在答题渠道关闭之前,参赛队伍均可根据反馈结果进一步调整检测算法。本题最终得分为参赛队伍在答题截止前最后一次提交结果的得分。
评分规则
赛题二评分的主要依据为邮件日志类型识别的准确程度,计算公式如下,赛题二的最终得分,按照30%的比重,加权计入线上积分赛的总得分。

2.解题方法
这道题目的writeup我会好好分享。一方面真诚感谢主办方举办这个比赛,这期间您们真的非常辛苦,付出很多;另一方面,自己之前一直从事NLP和大数据分析方向近八年,这是第一次应用到钓鱼邮件分析,而且这题的排名一直第一。通过这个比赛也学到很多知识,简单分享下我的方法。
此外,比赛之后,我也尝试了其他大数据分析(知识图谱)及机器学习的方法,真诚希望这个writeup能帮助到需要的人及恶意邮件黑产分析领域。当然如果没有帮助,也算是对您们付出的一种感谢。如果有错误之处,还请海涵。

(1) 基本思想
首先,我给这次比赛的思路绘制了如下的流程图。
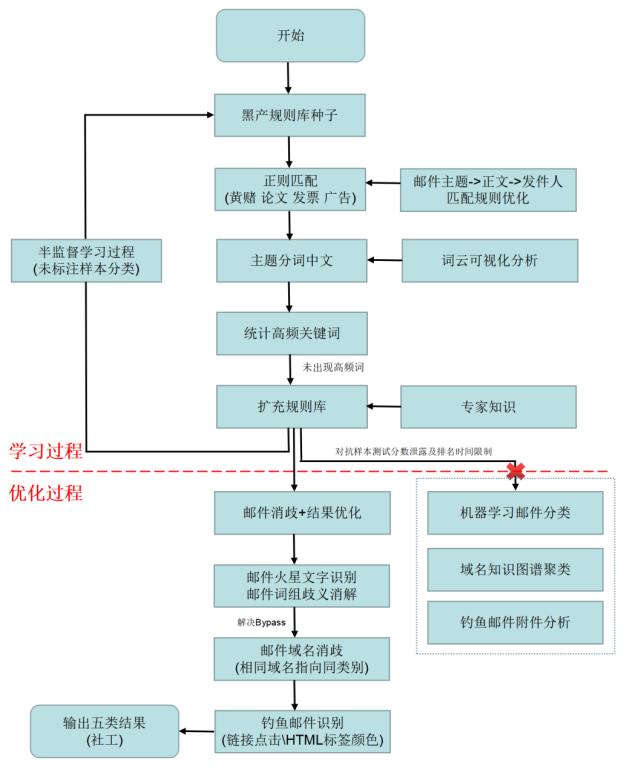
作为一个数据分析人员,我首先想到的就是邮件主题(subject)、邮件正文(content)和发件人名称(fromname)三个字段进行文本分类,然后再进行算法优化和结果改进。总体思路分为两个阶段:
- 主题规则学习过程
- 邮件分类消歧过程
主题规则学习过程
在第一阶段我们主要通过规则进行匹配,这里使用了之前DataCon黑产比赛的部分种子作为规则库,最早匹配出“涉H(中)”、“约会涉H(英)”、“论文培训”、“发票”、“广告”、“钓鱼”、“涉赌”等主题。
其核心相当于一个半监督学习的过程,初始标注之后,每次统计结果都会进一步中文分词,然后统计高频关键词,如果某个类别中没有出现过类似的关键词,则扩充规则库,并且融入专家知识进行校对,从而不断学习。
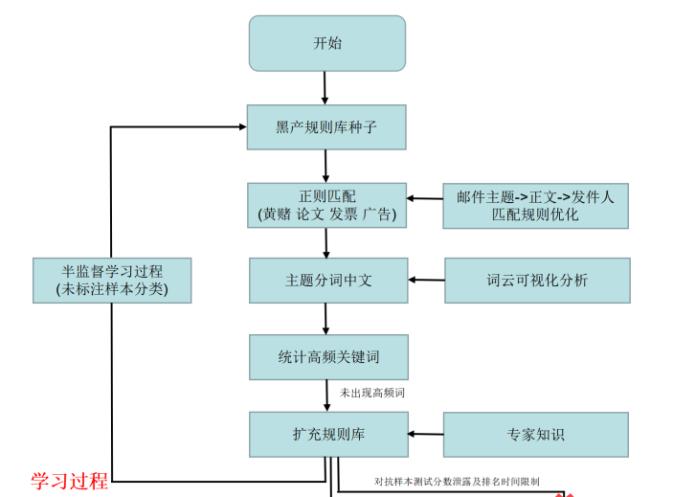
邮件分类消歧过程
在第二阶段我们主要进行优化过程,包括邮件消歧和结果优化,这里包括邮件火星文字“城人”“出兽”等,同时解决ByPass问题,这些火星文字实际上是一种对抗文本,可以尝试word2vec来识别,比如与它共现的词组通常能决定其含义,比如“出兽”和“AV”“私聊”等关键词同时出现,其很大程度就是火星文字。接着进行相关的计算解决火星文字,但这里时间关系未去实现。内容校验方法包括:
- ①新规则学习定义;
- ②邮件域名校正。
接下来我们通过社交网络或知识图谱在已经明确分类的邮件中提取邮件域名,同一个域名出现某种类别的概率大于某个阈值时,认为该域名下的邮件很可能都是某个类别,例如钓鱼邮件或涉黄邮件,这里相当于为我们的邮件建立一个黑白名单,从而进一步优化某些分类错误的邮件。
最后,我们仅仅将异常(邮箱停用、邮箱警报等)类型分为钓鱼邮件,但其实还可以通过HTML、链接点击进行深入划分,比如设置颜色背景的、下载附件exe或者引诱你点击的很大程度就是钓鱼邮件,这里可以结合另外两道题目的思路进行优化,由于时间关于,我们也未进行相关操作。

总之,作者的算法思想相当于一个半监督学习的过程,不断扩充规则库,同时解决火星文字歧义、邮箱校对,最终实验分类。
比较遗憾,作者的本意是想通过右边的三种方法 “机器学习”、“知识图谱”和“钓鱼邮件分析” 相关知识进行邮件分类,由于分数还不错,但第三题和第一题之前一直较低。所以作者放弃了其他方法,专心攻克后面的题目,但比赛结束之后我也都用机器学习和知识图谱进行了相关的实验,也算弥补自己的过失。比赛终究是比赛,但更希望能学到知识,并且今后会进一步深入研究鱼叉式钓鱼邮件攻击相关知识,加油!再次感谢主办方。
Python在处理文本数据时,也融入了一些经验,其关键点包括:
- 英文统一转化成小写再进行匹配 尽量不适用"AV"这种简单规则匹配
- 注意对抗样本火星文字,“出兽 城人” “罗莉” “燕照” 找准关键词
- 邮件域名进行相似度计算,比如word2vec共现解决火星文字
- 判断存在先后顺序,如果仅文字规则匹配,建议 title\\fromname\\content
- 国外涉黄邮件通常包含关键词+URL链接
- 单个字规则建议放最后防止出现误判情况 “发票”->“票”
- 实体消歧 private等,可能是涉黄 隐私也可能是其他
- QQ号重点分类,361xxxx70 [797封] 127xxxx73 [783],类似这种的特征需要分词来匹配,否则容易漏掉
- 当数据量较大时允许一些误判,大方向保持即可,evening -> good evening \\ SNL Evening Summary
- 已经标注的数据提取from和fromname字段,同一个邮件经常涉黄,则其他的也可以定义为相同的类别
同时补充一句,作者花了很长时间去测试最终的类别,最后测试是五个类别。但比赛前居然公布了,哈哈!一方面批评下自己,感觉没有尝试突破新方法;另一方面也弱弱吐槽下主办方,因为有的队伍可能都花时间去提升第三题,透露五类结果还是有点影响。但整体这次比赛非常赞,学到很多知识,真诚的感谢您们,也希望多多举办更多类似比赛,后续也会深入研究鱼叉式钓鱼邮件知识。

(2) 大数据分析及知识图谱展现
做这部分实验时,比赛早已结束。其实在比赛过程中我一直很纠结,到底要不要用大数据、LDA聚类、机器学习或知识图谱(社交网络)的方法进行分析。但由于我们分数一直排在前面,所以就把更多精力放到了第三题上面。这是比赛的残酷性吧!但赛后我还是迫不及待的用这些方法进行了尝试。
首先,我们前面已经分析出整个数据集包括五个类别(涉H&暴力、广告&钓鱼、论文&培训、发票&开户、约会&涉H-英),它们对应的词云图如下所示。

每个类别的核心关键词如表1所示。

某些特殊的QQ号和电话对分类结果影响较大,这些特征也可以提取出来作为黑白名单。其中发现2个比较特殊的涉黄QQ号,比如“361xxxx70”和”127xxx73”。

同理电话“135xxx8291”为发票高频电话,共748封发票邮件;同时发现2个比较特殊的发票QQ号,“958xxxx20”共550封,这些均可以作为黑白名单。
邮箱域名相当于企业的可信分数或者黑白名单,一定程度能增加钓鱼邮件的识别度,提高分类的准确率。我们前面已经分析出整个数据集包括五个类别:
- 涉黄暴力
- 广告通知
- 论文培训
- 发票开户
- 钓鱼邮件
下面补充知识图谱分析的各个主体高频域名,这些域名很大程度能决定一封邮件的类别,尤其是某些域名可能就是常年用于钓鱼。其关系如图所示。连线较粗的同样可以为企业的黑白名单,与APT攻击溯源类似,这些常用IP地址、C&C服务对我们的防御均有一定效果。所以作者上面的方法中,通过域名进行一定程度的优化,从而提升了分数。
最后,作者尝试用机器学习方法对文本内容进行聚类分析,类别设置为5类。同时,可以对邮件主题、正文聚类,再结合规则匹配及钓鱼邮件识别可能效果更好。
(3) 代码解读及运行
代码首先定义各字段变量,然后提取对应的值,这里的特点是提取了邮箱的域名作为后续的提升优化。


接着进行关键词的匹配过程,如下图所示,通过定义最简单的关键词进行匹配,用列表可能效果更好,注意所有英文字母转换成小写对比。

同时统计已分类文本的高频关键词,进行相关的规则扩充,当关键词不在已有规则中时进行扩充。这里的代码写的太差,更好的方法是定义列表进行匹配和扩充。中文分词采用Jieba工具,对应的关键词统计代码如下:

大数据分析中可视化展示也非常直观,这里可以常用词云WordCloud库进行绘制。

最后是邮件匹配校正的过程,这里简单设置某些邮件白名单进行校对。比如约会类别等。
总之,再次感谢清华大学Datacon和Coremail论坛,学到很多,感谢感谢!!!
赛题一:火眼金睛
1.题目介绍
了解常见的邮件安全协议,熟悉常见的邮件数据头部字段。在此基础上,自行设计检测算法,识别数据集中所有包含“发件人伪造(Sender Spoofing)”攻击行为的邮件。
数据为5000封左右的邮件信息,经过主办方的匿名化处理,仅保留邮件的头部字段信息。每封邮件均有唯一的ID编号,其中仅有100封左右的邮件含有发件人伪造攻击。

2.解题方法
引用北大ccgo大佬们的解析,推荐大家学习。
通过对常见邮件安全协议的学习,相关RFC【5321-SMTP、7208-SPF、6376-DKIM、7489-DMARC】的浏览,并结合文献[USENIX2020]的内容。更加了解了 DMARC,DKIM, SPF 等邮件安全协议,如 DKIM-Signature, Authentication-Results 等字段中各标志含义,总结出几条较为显著的识别发件人伪造的规则。
解题思路
看到这道题,最开始考虑的是spf字段的内容,通过遍历这五千多封邮件,判断邮件中是否包含“spf=pass”字段,找到了23封邮件。
- [184, 313, 609, 779, 1753, 2047, 2052, 2214, 2266, 2417, 2608, 3069, 3087, 3248, 3683, 3808, 3827, 3839, 4424, 4479, 4687, 4903, 5038]
根据usenix 2020(Composition Kills: A Case Study of Email Sender Authentication),重点检查“From:”和“smtp.from”字段。如果有多个From字段,则很有可能是伪造邮件;如果只有一个From字段,含有多个邮箱,也有可能是伪造邮件;如果只有一个From字段,并且From字段只有一个邮箱,但如果这个邮箱与smtp.mail的邮箱不相同,那么也可能是伪造邮件。
代码实现
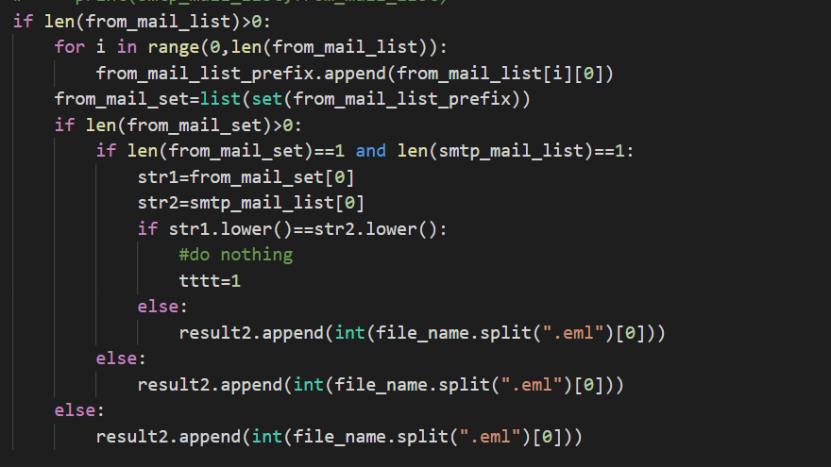
判断spf=pass和多个From字段的代码很简单,不过多介绍,这里主要介绍一下From字段和smtp.mail字段邮箱判断的代码。首先通过python的email库将DKIM-Signature和From字段的内容给提取出来,这里需要注意一个点,提取出来的字段可能有换行制表符(\\n\\t)如下图。

使用replace将制表符替换掉,再利用正则r’smtp.mail=([\\s\\S]*?);'匹配smtp.mail。在匹配From字段的邮箱时,使用了两种不同的正则方法。
第一种方法是提取<>中的内容作为邮箱,进行去重、大写转小写处理后,与smtp.mail相比较。如果不相同,则认为其是伪造邮件。这个思路其实是有缺陷的,没有考虑到其他情况(可能<>不存在,<>内不止一个邮箱,<>前面存在邮箱等),不过结合spf=pass和多个From字段的结果,共找到86个邮件,提交后全部正确,下图为部分代码。
第二种方法,主要是修改了一下From字段邮箱正则匹配,正则为r’([A-Za-z0-9_-\\u4e00-\\u9fa5.+]+@[a-zA-Z0-9_-]+(.[a-zA-Z0-9_-]+)+)’,其他思路,与第一种方法相同。将两种正则的结果加上spf=pass和多个From字段的结果,得到91封邮件(正确88封,错误3封,86.5分)
参考文献
- https://www.anquanke.com/post/id/218889
- https://i.blackhat.com/USA-20/Thursday/us-20-Chen-You-Have-No-Idea-Who-Sent-That-Email-18-Attacks-On-Email-Sender-Authentication.pdf
- https://www.usenix.org/system/files/sec20fall_chen-jianjun_prepub_0.pdf
赛题三:孤胆猎手
1.题目介绍
在真实的企业网络环境中,一些攻击者总能想方设法绕过邮件检测引擎,使攻击邮件抵达员工的收件箱,最终达到窃取用户登录凭证等目的。与此同时,企业网络安全管理团队的精力十分有限,不可能实现对企业的全部邮件进行逐一审查。
如果你是一家企业的邮件安全负责人,能否基于数据分析,利用长达三个月的企业邮件服务器日志摘要信息,设计检测模型,输出一批威胁程度较高的邮件,以便于后续的人工审查。请注意:检测模型不允许使用第三方威胁情报,检测系统必须能够离线运行。

2.解题方法
本题我们主要根据实际经验,选取重要字段,基于规则来构造检测模型,筛选威胁邮件。本题数据共798803封邮件,威胁邮件量级在5000-20000封。
数据字段含义如下表所示:

fromname字段筛选
根据FreeBuf网站博文《CNCERT钓鱼邮件攻击防范指南》,发件人地址是识别钓鱼邮件的重要信息:“如果是公务邮件,发件人多数会使用工作邮箱,如果发现对方使用的是个人邮箱帐号或者邮箱账号拼写很奇怪,那么就需要提高警惕。钓鱼邮件的发件人地址经常会进行伪造,比如伪造成本单位域名的邮箱账号或者系统管理员账号。”
我们首先筛选“fromname”(发信人名称)字段里含有管理员相关键词的邮件,筛选使用的关键词如下表所示:
- admin
- administrator
- master
- postmaster
- service
- 安全
- 管理员
筛选的代码如下(函数返回值True代表是威胁邮件,False代表不是威胁邮件。后续过滤函数返回值含义与此相同,不再赘述)。共筛选出了21611封邮件。
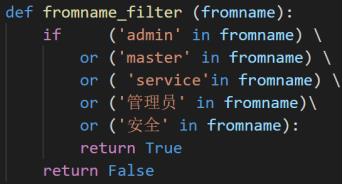
url和sender字段筛选
在这21611封邮件的基础上,我们继续筛选威胁邮件。下一个我们认为较为重要的字段为“url”字段。根据经验,钓鱼类威胁邮件通常情况下在邮件正文等地方会有链接地址,这个字段是相对比较重要的。我们发现在这21611封邮件里,存在如下图所示的,“url”为空的邮件。

我们认为“url”为空的邮件,其威胁性较小,因为从技术角度出发,不加链接的邮件成功钓鱼的可能性较小(本题无邮件的附件信息,我们这里先不考虑邮件会通过附件来实施钓鱼等恶意行为)。
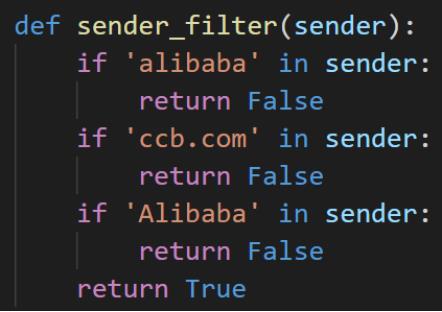
另外,我们发现有不少“url”中包含“ccb.com”(中国建设银行域名)和“alibaba”(阿里巴巴公司域名)的邮件,从中提取到的url数量较多(如下图所示),这些域名根据经验判断逻辑上是互相关联的,我们认为其是威胁邮件的可能性较小。

因此我们决定将“url”字段为空和“url”字段中包含“alibaba”和“ccb.com”的邮件从威胁邮件的集合中剔除(“fromname”字段包含“admin”关键词的邮件仍然保留),筛选的代码如下,筛选后共有13830封邮件。

类似地,我们将“sender”字段中包含“alibaba”和“ccb.com”的邮件从威胁邮件的集合中剔除。筛选后共有13828封邮件。
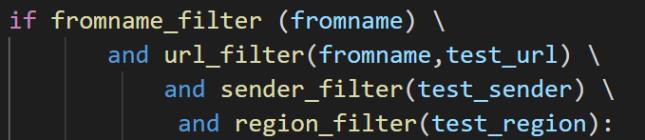
region字段筛选
最后,我们发现在邮件的“region”字段,有部分邮件存在“骨干网”和“�”字符,从数据中人工查看了几封这类邮件,我们认为其威胁性较低,故将其从威胁邮件集合中剔除。

以上规则综合,可以筛选得到我们最终提交的威胁邮件集合。共计13789封邮件。最终我们队的F1-score为0.4551671442。
其他尝试方法,但分数提高较低。
- 提取URL附件包含“.exe”的邮件,认为是钓鱼邮件
- 通过离线data和pygeoip包获取IP地址对应的地区,判断IP地址对应地区关键词,如果查询结果与提供的region不匹配存在恶意可能性
- 获取时间时区,UTC转换后区域对比,比如凌晨2-5点邮件异常(类似于APT时区检测)
- 提取乱码问号认为编码问题的钓鱼邮件
- 基于字符串相似度计算识别,统计共现或聚类的程度
- email附件 .doc .pdf .xls .exe (URL包括【】 email= 附件连接 钓鱼)
- 自己发给自己的邮件1121封,认为是恶意邮件
总结
写到这里这篇文章就介绍介绍,希望对您有所帮助。本文主要介绍了DataCon Coremail邮件安全竞赛之钓鱼邮件识别及分类知识。
- 题目背景
- 赛题二:明察秋毫
- 赛题一:火眼金睛
- 赛题三:孤胆猎手

欢迎大家讨论,是否觉得这系列文章帮助到您!任何建议都可以评论告知读者,共勉。
- 逆向分析:https://github.com/eastmountyxz/SystemSecurity-ReverseAnalysis
- 网络安全:https://github.com/eastmountyxz/NetworkSecuritySelf-study
(By:Eastmount 2021-10-26 夜于武汉 http://blog.csdn.net/eastmount/ )
推荐文章:
- [1] Coremail2020邮件安全竞赛优秀解题思路分享(北京大学ccgo战队)
- [2] https://datacon.qianxin.com/
- [3] DataCon 2020 Coremail邮件安全竞赛-赛题一满分writeup
- [4] DataCon大数据安全分析比赛冠军思路分享
- [5] DNS恶意流量分析 - DataCon 2019数据赛DNS方向第一名解题方案
- [6] https://www.freebuf.com/articles/others-articles/174617.html
- [7] 钓鱼、投递木马……一文扒尽“白象三代”APT组织攻击活动!
自学篇(链接直接跳转到正文):
- [网络安全自学篇] 一.入门笔记之看雪Web安全学习及异或解密示例
- [网络安全自学篇] 二.Chrome浏览器保留密码功能渗透解析及登录加密入门笔记
- [网络安全自学篇] 三.Burp Suite工具安装配置、Proxy基础用法及暴库示例
- [网络安全自学篇] 四.实验吧CTF实战之WEB渗透和隐写术解密
- [网络安全自学篇] 五.IDA Pro反汇编工具初识及逆向工程解密实战
- [网络安全自学篇] 六.OllyDbg动态分析工具基础用法及Crakeme逆向
- [网络安全自学篇] 七.快手视频下载之Chrome浏览器Network分析及Python爬虫探讨
- [网络安全自学篇] 八.Web漏洞及端口扫描之Nmap、ThreatScan和DirBuster工具
- [网络安全自学篇] 九.社会工程学之基础概念、IP获取、IP物理定位、文件属性
- [网络安全自学篇] 十.论文之基于机器学习算法的主机恶意代码
- [网络安全自学篇] 十一.虚拟机VMware+Kali安装入门及Sqlmap基本用法
- [网络安全自学篇] 十二.Wireshark安装入门及抓取网站用户名密码(一)
- [网络安全自学篇] 十三.Wireshark抓包原理(ARP劫持、MAC泛洪)及数据流追踪和图像抓取(二)
- [网络安全自学篇] 十四.Python攻防之基础常识、正则表达式、Web编程和套接字通信(一)
- [网络安全自学篇] 十五.Python攻防之多线程、C段扫描和数据库编程(二)
- [网络安全自学篇] 十六.Python攻防之弱口令、自定义字典生成及网站暴库防护
- [网络安全自学篇] 十七.Python攻防之构建Web目录扫描器及ip代理池(四)
- [网络安全自学篇] 十八.XSS跨站脚本攻击原理及代码攻防演示(一)
- [网络安全自学篇] 十九.Powershell基础入门及常见用法(一)
- [网络安全自学篇] 二十.Powershell基础入门及常见用法(二)
- [网络安全自学篇] 二十一.GeekPwn极客大赛之安全攻防技术总结及ShowTime
- [网络安全自学篇] 二十二.Web渗透之网站信息、域名信息、端口信息、敏感信息及指纹信息收集
- [网络安全自学篇] 二十三.基于机器学习的恶意请求识别及安全领域中的机器学习
- [网络安全自学篇] 二十四.基于机器学习的恶意代码识别及人工智能中的恶意代码检测
- [网络安全自学篇] 二十五.Web安全学习路线及木马、病毒和防御初探
- [网络安全自学篇] 二十六.Shodan搜索引擎详解及Python命令行调用
- [网络安全自学篇] 二十七.Sqlmap基础用法、CTF实战及请求参数设置(一)
- [网络安全自学篇] 二十八.文件上传漏洞和Caidao入门及防御原理(一)
- [网络安全自学篇] 二十九.文件上传漏洞和IIS6.0解析漏洞及防御原理(二)
- [网络安全自学篇] 三十.文件上传漏洞、编辑器漏洞和IIS高版本漏洞及防御(三)
- [网络安全自学篇] 三十一.文件上传漏洞之Upload-labs靶场及CTF题目01-10(四)
- [网络安全自学篇] 三十二.文件上传漏洞之Upload-labs靶场及CTF题目11-20(五)
- [网络安全自学篇] 三十三.文件上传漏洞之绕狗一句话原理和绕过安全狗(六)
- [网络安全自学篇] 三十四.Windows系统漏洞之5次Shift漏洞启动计算机
- [网络安全自学篇] 三十五.恶意代码攻击溯源及恶意样本分析
- [网络安全自学篇] 三十六.WinRAR漏洞复现(CVE-2018-20250)及恶意软件自启动劫持
- [网络安全自学篇] 三十七.Web渗透提高班之hack the box在线靶场注册及入门知识(一)
- [网络安全自学篇] 三十八.hack the box渗透之BurpSuite和Hydra密码爆破及Python加密Post请求(二)
- [网络安全自学篇] 三十九.hack the box渗透之DirBuster扫描路径及Sqlmap高级注入用法(三)
- [网络安全自学篇] 四十.phpMyAdmin 4.8.1后台文件包含漏洞复现及详解(CVE-2018-12613)
- [网络安全自学篇] 四十一.中间人攻击和ARP欺骗原理详解及漏洞还原
- [网络安全自学篇] 四十二.DNS欺骗和钓鱼网站原理详解及漏洞还原
- [网络安全自学篇] 四十三.木马原理详解、远程服务器IPC$漏洞及木马植入实验
- [网络安全自学篇] 四十四.Windows远程桌面服务漏洞(CVE-2019-0708)复现及详解
- [网络安全自学篇] 四十五.病毒详解及批处理病毒制作(自启动、修改密码、定时关机、蓝屏、进程关闭)
- [网络安全自学篇] 四十六.微软证书漏洞CVE-2020-0601 (上)Windows验证机制及可执行文件签名复现
- [网络安全自学篇] 四十七.微软证书漏洞CVE-2020-0601 (下)Windows证书签名及HTTPS网站劫持
- [网络安全自学篇] 四十八.Cracer第八期——(1)安全术语、Web渗透流程、Windows基础、注册表及常用DOS命令
- [网络安全自学篇] 四十九.Procmon软件基本用法及文件进程、注册表查看
- [网络安全自学篇] 五十.虚拟机基础之安装XP系统、文件共享、网络快照设置及Wireshark抓取BBS密码
- [网络安全自学篇] 五十一.恶意样本分析及HGZ木马控制目标服务器
- [网络安全自学篇] 五十二.Windows漏洞利用之栈溢出原理和栈保护GS机制
- [网络安全自学篇] 五十三.Windows漏洞利用之Metasploit实现栈溢出攻击及反弹shell
- [网络安全自学篇] 五十四.Windows漏洞利用之基于SEH异常处理机制的栈溢出攻击及shell提取
- [网络安全自学篇] 五十五.Windows漏洞利用之构建ROP链绕过DEP并获取Shell
- [网络安全自学篇] 五十六.i春秋老师分享小白渗透之路及Web渗透技术总结
- [网络安全自学篇] 五十七.PE文件逆向之什么是数字签名及Signtool签名工具详解(一)
- [网络安全自学篇] 五十八.Windows漏洞利用之再看CVE-2019-0708及Metasploit反弹shell
- [网络安全自学篇] 五十九.Windows漏洞利用之MS08-067远程代码执行漏洞复现及shell深度提权
- [网络安全自学篇] 六十.Cracer第八期——(2)五万字总结Linux基础知识和常用渗透命令
- [网络安全自学篇] 六十一.PE文件逆向之数字签名详细解析及Signcode、PEView、010Editor、Asn1View等工具用法(二)
- [网络安全自学篇] 六十二.PE文件逆向之PE文件解析、PE编辑工具使用和PE结构修改(三)
- [网络安全自学篇] 六十三.hack the box渗透之OpenAdmin题目及蚁剑管理员提权(四)
- [网络安全自学篇] 六十四.Windows漏洞利用之SMBv3服务远程代码执行漏洞(CVE-2020-0796)复现及详解
- [网络安全自学篇] 六十五.Vulnhub靶机渗透之环境搭建及JIS-CTF入门和蚁剑提权示例(一)
- [网络安全自学篇] 六十六.Vulnhub靶机渗透之DC-1提权和Drupal漏洞利用(二)
- [网络安全自学篇] 六十七.WannaCry勒索病毒复现及分析(一)Python利用永恒之蓝及Win7勒索加密
- [网络安全自学篇] 六十八.WannaCry勒索病毒复现及分析(二)MS17-010利用及病毒解析
- [网络安全自学篇] 六十九.宏病毒之入门基础、防御措施、自发邮件及APT28样本分析
- [网络安全自学篇] 七十.WannaCry勒索病毒复现及分析(三)蠕虫传播机制分析及IDA和OD逆向
- [网络安全自学篇] 七十一.深信服分享之外部威胁防护和勒索病毒对抗
- [网络安全自学篇] 七十二.逆向分析之OllyDbg动态调试工具(一)基础入门及TraceMe案例分析
- [网络安全自学篇] 七十三.WannaCry勒索病毒复现及分析(四)蠕虫传播机制全网源码详细解读
- [网络安全自学篇] 七十四.APT攻击检测溯源与常见APT组织的攻击案例
- [网络安全自学篇] 七十五.Vulnhub靶机渗透之bulldog信息收集和nc反弹shell(三)
- [网络安全自学篇] 七十六.逆向分析之OllyDbg动态调试工具(二)INT3断点、反调试、硬件断点与内存断点
- [网络安全自学篇] 七十七.恶意代码与APT攻击中的武器(强推Seak老师)
- [网络安全自学篇] 七十八.XSS跨站脚本攻击案例分享及总结(二)
- [网络安全自学篇] 七十九.Windows PE病毒原理、分类及感染方式详解
- [网络安全自学篇] 八十.WHUCTF之WEB类解题思路WP(代码审计、文件包含、过滤绕过、SQL注入)
- [网络安全自学篇] 八十一.WHUCTF之WEB类解题思路WP(文件上传漏洞、冰蝎蚁剑、反序列化phar)
- [网络安全自学篇] 八十二.WHUCTF之隐写和逆向类解题思路WP(文字解密、图片解密、佛语解码、冰蝎流量分析、逆向分析)
- [网络安全自学篇] 八十三.WHUCTF之CSS注入、越权、csrf-token窃取及XSS总结
- [网络安全自学篇] 八十四.《Windows hk编程技术详解》之VS环境配置、基础知识及DLL延迟加载详解
- [网络安全自学篇] 八十五.《Windows hk编程技术详解》之注入技术详解(全局钩子、远线程钩子、突破Session 0注入、APC注入)
- [网络安全自学篇] 八十六.威胁情报分析之Python抓取FreeBuf网站APT文章(上)
- [网络安全自学篇] 八十七.恶意代码检测技术详解及总结
- [网络安全自学篇] 八十八.基于机器学习的恶意代码检测技术详解
- [网络安全自学篇] 八十九.PE文件解析之通过Python获取时间戳判断软件来源地区
- [网络安全自学篇] 九十.远控木马详解及APT攻击中的远控
- [网络安全自学篇] 九十一.阿里云搭建LNMP环境及实现PHP自定义网站IP访问 (1)
- [网络安全自学篇] 九十二.《Windows hk编程技术详解》之病毒启动技术创建进程API、突破SESSION0隔离、内存加载详解(3)
- [网络安全自学篇] 九十三.《Windows hk编程技术详解》之木马开机自启动技术(注册表、计划任务、系统服务)
- [网络安全自学篇] 九十四.《Windows hk编程技术详解》之提权技术(令牌权限提升和Bypass UAC)
- [网络安全自学篇] 九十五.利用XAMPP任意命令执行漏洞提升权限(CVE-2020-11107)
提高篇:
- [网络安全提高班] 一〇一.网络空间安全普及和医疗数据安全防护总结
- [网络安全提高篇] 一〇二.Metasploit技术之基础用法万字详解及MS17-010漏洞复现
- [网络安全提高篇] 一〇三.Metasploit后渗透技术之信息收集、权限提权、移植漏洞模块和后门
- [网络安全提高篇] 一〇四.网络渗透靶场Oracle+phpStudy本地搭建万字详解(SQL注入、XSS攻击、文件上传漏洞)
- [网络安全提高篇] 一〇五.SQL注入之揭秘Oracle数据库注入漏洞和致命问题(联合Cream老师)
- [网络安全提高篇] 一〇六.SQL注入之手工注入和SQLMAP入门案例详解
- [网络安全提高篇] 一〇七.安全威胁框架理解及勒索病毒取证溯源分析(蓝队)
- [网络安全提高篇] 一〇八.Powershell和PowerSploit脚本攻击详解 (1)
- [网络安全提高篇] 一〇九.津门杯CTF的Web Write-Up万字详解(SSRF、文件上传、SQL注入、代码审计、中国蚁剑)
- [网络安全提高篇] 一一〇.强网杯CTF的Web Write-Up(上) 寻宝、赌徒、EasyWeb、pop_master
- [网络安全提高篇] 一一一.ISC会议观后感之网络安全需要新战法和新框架
- [网络安全提高篇] 一一二.DataCon Coremail邮件安全竞赛之钓鱼邮件识别及分类
以上是关于[网络安全提高篇] 一一二.DataCon Coremail邮件安全竞赛之钓鱼邮件识别及分类的主要内容,如果未能解决你的问题,请参考以下文章
[网络安全提高篇] 一一一.ISC会议观后感之网络安全需要新战法和新框架
[网络安全提高篇] 一一六.恶意代码同源分析及BinDiff软件基础用法
[网络安全提高篇] 一一五.Powershell恶意代码检测 Token关键词自动提取
[网络安全提高篇] 一一四.Powershell恶意代码检测 抽象语法树自动提取万字详解