Java NIO (图解+秒懂+史上最全)
Posted 架构师-尼恩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java NIO (图解+秒懂+史上最全)相关的知识,希望对你有一定的参考价值。
文章很长,建议收藏起来,慢慢读! Java 高并发 发烧友社群:疯狂创客圈 奉上以下珍贵的学习资源:
-
免费赠送 经典图书:《Java高并发核心编程(卷1)》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
-
免费赠送 经典图书:《Java高并发核心编程(卷2)》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
-
免费赠送 经典图书:《Netty Zookeeper Redis 高并发实战》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
-
免费赠送 经典图书:《SpringCloud Nginx高并发核心编程》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
-
免费赠送 资源宝库: Java 必备 百度网盘资源大合集 价值>10000元 加尼恩领取
推荐:入大厂 、做架构、大力提升Java 内功 的 精彩博文
| 入大厂 、做架构、大力提升Java 内功 必备的精彩博文 | 2021 秋招涨薪1W + 必备的精彩博文 |
|---|---|
| 1:Redis 分布式锁 (图解-秒懂-史上最全) | 2:Zookeeper 分布式锁 (图解-秒懂-史上最全) |
| 3: Redis与MySQL双写一致性如何保证? (面试必备) | 4: 面试必备:秒杀超卖 解决方案 (史上最全) |
| 5:面试必备之:Reactor模式 | 6: 10分钟看懂, Java NIO 底层原理 |
| 7:TCP/IP(图解+秒懂+史上最全) | 8:Feign原理 (图解) |
| 9:DNS图解(秒懂 + 史上最全 + 高薪必备) | 10:CDN图解(秒懂 + 史上最全 + 高薪必备) |
| Java 面试题 30个专题 , 史上最全 , 面试必刷 | 阿里、京东、美团… 随意挑、横着走!!! |
|---|---|
| 1: JVM面试题(史上最强、持续更新、吐血推荐) | 2:Java基础面试题(史上最全、持续更新、吐血推荐 |
| 3:架构设计面试题 (史上最全、持续更新、吐血推荐) | 4:设计模式面试题 (史上最全、持续更新、吐血推荐) |
| 17、分布式事务面试题 (史上最全、持续更新、吐血推荐) | 一致性协议 (史上最全) |
| 29、多线程面试题(史上最全) | 30、HR面经,过五关斩六将后,小心阴沟翻船! |
| 9.网络协议面试题(史上最全、持续更新、吐血推荐) | 更多专题, 请参见【 疯狂创客圈 高并发 总目录 】 |
| SpringCloud 精彩博文 | |
|---|---|
| nacos 实战(史上最全) | sentinel (史上最全+入门教程) |
| SpringCloud gateway (史上最全) | 更多专题, 请参见【 疯狂创客圈 高并发 总目录 】 |
特别说明:本文所属书籍已经更新啦,最新内容以书籍为准(书籍也免费送哦)
下面的内容,来自于《Java高并发核心编程卷1》一书,此书的最新电子版,已经免费赠送,大家找尼恩领取即可。
而且,《Java高并发核心编程卷1》的电子书,会不断优化和迭代。最新一轮的迭代,增加了 消息驱动IO模型的内容,这是之前没有的,使得在 Java NIO 底层原理这块,书的内容变得非常全面。
另外,如果出现内容需要更新,到处要更新的话,工作量会很大,所以后续的更新,都会统一到电子书哦。
核心基础:Java NIO核心详解
高性能的Java通信,绝对离不开Java
NIO组件,现在主流的技术框架或中间件服务器,都使用了Java NIO组件,譬如Tomcat、Jetty、Netty。
学习和掌握Java NIO组件,已经不是一项加分技能,而是一项必备技能。
不管是面试,还是实际开发,作为Java“攻城狮”(工程师的谐音),都必须掌握NIO的原理和开发实践技能。
NIO的起源
NIO技术是怎么来的?为啥需要这个技术呢?先给出一份在Java NIO出来之前,服务器端同步阻塞I/O处理(也就是BIO,Blocking I/O)的参考代码:
class ConnectionPerThreadWithPool implements Runnable
{
public void run()
{
//线程池
//注意,生产环境不能这么用,具体请参考《java高并发核心编程卷2》
ExecutorService executor = Executors.newFixedThreadPool(100);
try
{
//服务器监听socket
ServerSocket serverSocket =
new ServerSocket(NioDemoConfig.SOCKET_SERVER_PORT);
//主线程死循环, 等待新连接到来
while (!Thread.interrupted())
{
Socket socket = serverSocket.accept();
//接收一个连接后,为socket连接,新建一个专属的处理器对象
Handler handler = new Handler(socket);
//创建新线程来handle
//或者,使用线程池来处理
new Thread(handler).start();
}
} catch (IOException ex)
{ /* 处理异常 */ }
}
static class Handler implements Runnable
{
final Socket socket;
Handler(Socket s)
{
socket = s;
}
public void run()
{
//死循环处理读写事件
boolean ioCompleted=false;
while (!ioCompleted)
{
try
{
byte[] input = new byte[NioDemoConfig.SERVER_BUFFER_SIZE];
/* 读取数据 */
socket.getInputStream().read(input);
// 如果读取到结束标志
// ioCompleted= true
// socket.close();
/* 处理业务逻辑,获取处理结果 */
byte[] output = null;
/* 写入结果 */
socket.getOutputStream().write(output);
} catch (IOException ex)
{ /*处理异常*/ }
}
}
}
}
以上示例代码中,对于每一个新的网络连接,都通过线程池分配给一个专门线程去负责IO处理。每个线程都独自处理自己负责的socket连接的输入和输出。当然,服务器的监听线程也是独立的,任何的socket连接的输入和输出处理,不会阻塞到后面新socket连接的监听和建立,这样,服务器的吞吐量就得到了提升。早期版本的Tomcat服务器,就是这样实现的。
这是一个经典的每连接每线程的模型——Connection Per Thread模式。这种模型,在活动连接数不是特别高(小于单机1000)的情况下,这种模型是比较不错的,可以让每一个连接专注于自己的I/O并且编程模型简单,也不用过多考虑系统的过载、限流等问题。此模型往往会结合线程池使用,线程池本身就是一个天然的漏斗,可以缓冲一些系统处理不了的连接或请求。
不过,这个模型最本质的问题在于,严重依赖于线程。但线程是很”贵”的资源,主要表现在:
-
1 线程的创建和销毁成本很高,线程的创建和销毁都需要通过重量级的系统调用去完成。
-
2.线程本身占用较大内存,像Java的线程的栈内存,一般至少分配512K~1M的空间,如果系统中的线程数过千,整个JVM的内存将被耗用1G。
-
3.线程的切换成本是很高的。操作系统发生线程切换的时候,需要保留线程的上下文,然后执行系统调用。过多的线程频繁切换带来的后果是,可能执行线程切换的时间甚至会大于线程执行的时间,这时候带来的表现往往是系统CPU sy值特别高(超过20%以上)的情况,导致系统几乎陷入不可用的状态。
说 明
CPU利用率为CPU在用户进程、内核、中断处理、IO等待以及空闲时间五个部分使用百分比。人们往往通过五个部分的各种组合,用来分析CPU消耗情况的关键指标。CPU sy值表示内核线程处理所占的百分比。
如果使用linux 的top命令去查看当前系统的资源,会输出下面的一些指标:
top - 23:22:02 up 5:47, 1 user, load average: 0.00, 0.00, 0.00
Tasks: 107 total, 1 running, 106 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.3%us, 0.3%sy, 0.0%ni, 99.3%id, 0.0%wa, 0.0%hi, 0.0%si,0.0%st
Mem: 1017464k total, 359292k used, 658172k free, 56748k buffers
Swap: 2064376k total, 0k used, 2064376k free, 106200k cached
这里关注的是输出信息的第三行,其中:0.4%us表示用户进程所占的百分比;0.3%sy表示内核线程处理所占的百分比;0.0%ni表示被nice命令改变优先级的任务所占的百分比;99.3%id表示CPU空闲时间所占的百分比;0.0%wa表示等待IO所占的百分比;0.0%hi表示硬件中断所占的百分比,0.0%si表示为软件中断所占的百分比。
所以,当 CPU sy 值高时,表示系统调用耗费了较多的 CPU,对于 Java 应用程序而言,造成这种现象的主要原因是启动的线程比较多,并且这些线程多数都处于不断的等待(例如锁等待状态)和执行状态的变化过程中,这就导致了操作系统要不断的调度这些线程,切换执行。
- 4.容易造成锯齿状的系统负载。因为系统负载是用活动线程数或CPU核心数,一旦线程数量高但外部网络环境不是很稳定,就很容易造成大量请求同时到来,从而激活大量阻塞线程从而使系统负载压力过大。
说 明
系统负载(System
Load),指当前正在被CPU执行和等待被CPU执行的进程数目总和,是反映系统忙闲程度的重要指标。当load值低于CPU数目时,表示CPU有空闲,资源存在浪费;当load值高于CPU数目时,表示进程在排队等待CPU,表示系统资源不足,影响应用程序的执行性能。
总之,当面对十万甚至百万级连接的时候,传统的BIO模型是无能为力的。
但是,高并发的需求却越来越普通,随着移动端应用的兴起和各种网络游戏的盛行,百万级长连接日趋普遍,此时,必然需要一种更高效的I/O处理组件——这就是Java的NIO编程组件。
Java NIO简介
在1.4版本之前,JavaIO类库是阻塞式IO;从1.4版本开始,引进了新的异步IO库,被称为Java New IO类库,简称为Java NIO。
Java NIO类库的目标,就是要让Java支持非阻塞IO,基于这个原因,更多的人喜欢称Java NIO为非阻塞IO(Non-Block IO),称“老的”阻塞式Java IO为OIO(Old IO)。总体上说,NIO弥补了原来面向流的OIO同步阻塞的不足,它为标准Java代码提供了高速的、面向缓冲区的IO。
Java NIO类库包含以下三个核心组件:
-
Channel(通道)
-
Buffer(缓冲区)
-
Selector(选择器)
如果理解了第2章的四种IO模型,大家一眼就能识别出来,Java NIO,属于第三种模型—— IO 多路复用模型。只不过,Java
NIO组件提供了统一的应用开发API,为大家屏蔽了底层的操作系统的差异。
后面的章节,我们会对以上的三个Java NIO的核心组件,展开详细介绍。先来看看Java的NIO和OIO的简单对比。
NIO和OIO的对比
在Java中,NIO和OIO的区别,主要体现在三个方面:
(1)OIO是面向流(Stream Oriented)的,NIO是面向缓冲区(Buffer Oriented)的。
问题是:什么是面向流,什么是面向缓冲区呢?
在面向流的OIO操作中,IO的 read() 操作总是以流式的方式顺序地从一个流(Stream)中读取一个或多个字节,因此,我们不能随意地改变读取指针的位置,也不能前后移动流中的数据。
而NIO中引入了Channel(通道)和Buffer(缓冲区)的概念。面向缓冲区的读取和写入,都是与Buffer进行交互。用户程序只需要从通道中读取数据到缓冲区中,或将数据从缓冲区中写入到通道中。NIO不像OIO那样是顺序操作,可以随意地读取Buffer中任意位置的数据,可以随意修改Buffer中任意位置的数据。
(2)OIO的操作是阻塞的,而NIO的操作是非阻塞的。
OIO的操作是阻塞的,当一个线程调用read() 或 write()时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了。例如,我们调用一个read方法读取一个文件的内容,那么调用read的线程会被阻塞住,直到read操作完成。
NIO如何做到非阻塞的呢?当我们调用read方法时,系统底层已经把数据准备好了,应用程序只需要从通道把数据复制到Buffer(缓冲区)就行;如果没有数据,当前线程可以去干别的事情,不需要进行阻塞等待。
NIO的非阻塞是如何做到的呢?
其实在上一章,答案已经揭晓了,根本原因是:NIO使用了通道和通道的IO多路复用技术。
(3)OIO没有选择器(Selector)概念,而NIO有选择器的概念。
NIO技术的实现,是基于底层的IO多路复用技术实现的,比如在Windows中需要select多路复用组件的支持,在Linux系统中需要select/poll/epoll多路复用组件的支持。所以NIO的需要底层操作系统提供支持。而OIO不需要用到选择器。
通道(Channel)
前面提到,Java NIO类库包含以下三个核心组件:
-
Channel(通道)
-
Buffer(缓冲区)
-
Selector(选择器)
首先说一下Channel,国内大多翻译成“通道”。Channel的角色和OIO中的Stream(流)是差不多的。在OIO中,同一个网络连接会关联到两个流:一个输入流(Input Stream),另一个输出流(Output Stream),Java应用程序通过这两个流,不断地进行输入和输出的操作。
在NIO中,一个网络连接使用一个通道表示,所有的NIO的IO操作都是通过连接通道完成的。一个通道类似于OIO中的两个流的结合体,既可以从通道读取数据,也可以向通道写入数据。
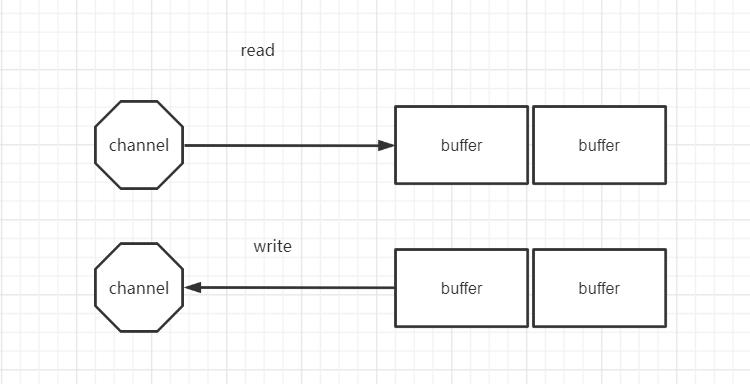
Channel和Stream的一个显著的不同是:Stream是单向的,譬如InputStream是单向的只读流,OutputStream是单向的只写流;而Channel是双向的,既可以用来进行读操作,又可以用来进行写操作。
NIO中的Channel的主要实现有:
-
1.FileChannel 用于文件IO操作
-
2.DatagramChannel 用于UDP的IO操作
-
3.SocketChannel 用于TCP的传输操作
-
4.ServerSocketChannel 用于TCP连接监听操作
选择器(Selector)
首先,回顾一个前面介绍的基础知识,什么是IO多路复用模型?
IO多路复用指的是一个进程/线程可以同时监视多个文件描述符(含socket连接),一旦其中的一个或者多个文件描述符可读或者可写,该监听进程/线程能够进行IO事件的查询。
在Java应用层面,如何实现对多个文件描述符的监视呢?
需要用到一个非常重要的Java NIO组件——Selector 选择器。Selector选择器可以理解为一个IO事件的监听与查询器。通过选择器,一个线程可以查询多个通道的IO事件的就绪状态。
在介绍Selector选择器之前,首先介绍一下这个前置的概念:IO事件。
什么是IO事件呢?
表示通道某种IO操作已经就绪、或者说已经做好了准备。
例如,如果一个新Channel链接建立成功了,就会在Server Socket Channel上发生一个IO事件,代表一个新连接一个准备好,这个IO事件叫做“接收就绪”事件。
再例如,一个Channel通道如果有数据可读,就会发生一个IO事件,代表该连接数据已经准备好,这个IO事件叫做“读就绪”事件。
Java NIO将NIO事件进行了简化,只定义了四个事件,这四种事件用SelectionKey的四个常量来表示:
-
SelectionKey.OP_CONNECT
-
SelectionKey.OP_ACCEPT
-
SelectionKey.OP_READ
-
SelectionKey.OP_WRITE
说 明
各个操作系统定义的IO事件,复杂得多,Java NIO 底层完成了操作系统IO事件,到Java NIO 事件的映射。这部分底层原理比较深奥,如果有兴趣,可以去看我的视频。
在大家了解了IO事件之后,再回头来看Selector选择器。Selector的本质,就是去查询这些IO就绪事件,所以,它的名称就叫做
Selector查询者。
从编程实现维度来说,IO多路复用编程的第一步,是把通道注册到选择器中,第二步则是通过选择器所提供的事件查询(select)方法,这些注册的通道是否有已经就绪的IO事件(例如可读、可写、网络连接完成等)。
由于一个选择器只需要一个线程进行监控,所以,我们可以很简单地使用一个线程,通过选择器去管理多个连接通道。
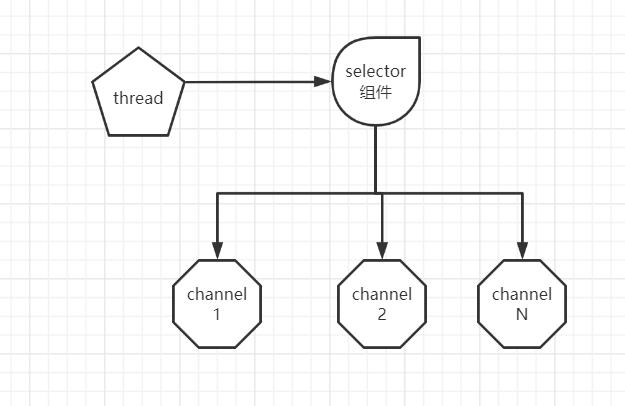
与OIO相比,NIO使用选择器的最大优势:系统开销小,系统不必为每一个网络连接(文件描述符)创建进程/线程,从而大大减小了系统的开销。
总之,通过Java NIO可以达到一个线程负责多个连接通道的IO处理,这是非常高效的。这种高效,恰恰就来自于Java的选择器组件Selector以及其底层的操作系统IO多路复用技术的支持。
缓冲区(Buffer)
应用程序与通道(Channel)主要的交互,主要是进行数据的read读取和write写入。为了完成NIO的非阻塞读写操作,NIO为大家准备了第三个重要的组件——NIO Buffer(NIO缓冲区)。
Buffer顾名思义:缓冲区,实际上是一个容器,一个连续数组。Channel提供从文件、网络读取数据的渠道,但是读写的数据都必须经过Buffer。
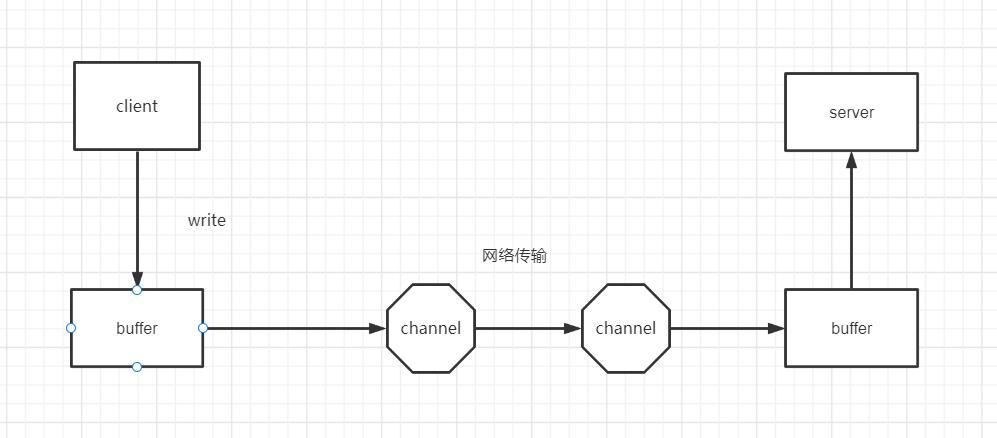
所谓通道的读取,就是将数据从通道读取到缓冲区中;所谓通道的写入,就是将数据从缓冲区中写入到通道中。缓冲区的使用,是面向流进行读写操作的OIO所没有的,也是NIO非阻塞的重要前提和基础之一。
接下来笔者从缓冲区开始,为大家详细介绍NIO的Buffer(缓冲区)、Channel(通道)、Selector(选择器)三大核心组件。
详解NIO Buffer类及其属性
NIO的Buffer(缓冲区)本质上是一个内存块,既可以写入数据,也可以从中读取数据。Java NIO中代表缓冲区的Buffer类是一个抽象类,位于java.nio包中。
NIO的Buffer的内部是一个内存块(数组),此类与普通的内存块(Java数组)不同的是:NIO Buffer对象,提供了一组比较有效的方法,用来进行写入和读取的交替访问。
说 明
Buffer类是一个非线程安全类。
Buffer类
Buffer类是一个抽象类,对应于Java的主要数据类型,在NIO中有8种缓冲区类,分别如下:ByteBuffer、CharBuffer、DoubleBuffer、FloatBuffer、IntBuffer、LongBuffer、ShortBuffer、MappedByteBuffer。
前7种Buffer类型,覆盖了能在IO中传输的所有的Java基本数据类型。第8种类型MappedByteBuffer是专门用于内存映射的一种ByteBuffer类型。不同的Buffer子类,其能操作的数据类型能够通过名称进行判断,比如IntBuffer只能操作Integer类型的对象。
实际上,使用最多的还是ByteBuffer二进制字节缓冲区类型,后面会看到。
Buffer类的重要属性
Buffer的子类会拥有一块内存,作为数据的读写缓冲区,但是读写缓冲区并没有定义在Buffer基类,而是定义在具体的子类中。如ByteBuf子类就拥有一个byte[]类型的数组成员final byte[] hb,作为自己的读写缓冲区,数组的元素类型与Buffer子类的操作类型相互对应。
说 明
在本书的上一个版本中,这里的内容为:Buffer内部有一个byte[]类型的数组作为数据的读写缓冲区。咋看上去没有什么错误,实际上是这个结论是错误的。具体原因:作为读写缓冲区的数组,并没有定义在Buffer类中,而是定义在各具体子类中。
感谢社群小伙伴 @炬,是他发现了这个藏得比较隐蔽的编写错误。
为了记录读写的状态和位置,Buffer类额外提供了一些重要的属性,其中有以下三个重要的成员属性:
-
capacity(容量)
-
position(读写位置)
-
limit(读写的限制)
接下来对以上三个成员属性,进行比较详细的介绍。
- capacity属性
Buffer类的capacity属性,表示内部容量的大小。一旦写入的对象数量超过了capacity容量,缓冲区就满了,不能再写入了。
Buffer类的capacity属性一旦初始化,就不能再改变。原因是什么呢?Buffer类的对象在初始化时,会按照capacity分配内部数组的内存,在数组内存分配好之后,它的大小当然就不能改变了。
前面讲到,Buffer类是一个抽象类,Java不能直接用来新建对象。在具体使用的时候,必须使用Buffer的某个子类,例如DoubleBuffer子类,该子类能写入的数据类型是double类型,如果在创建实例时其capacity是100,那么我们最多可以写入100个double类型的数据。
说 明
capacity容量并不是指内部的内存块byte[]数组的字节数量,而是指能写入的数据对象的最大限制数量。
- position属性
Buffer类的position属性,表示当前的位置。position属性的值与缓冲区的读写模式有关。在不同的模式下,position属性值的含义是不同的,在缓冲区进行读写的模式改变时,position值会进行相应的调整。
在写入模式下,position的值变化规则如下:
(1)在刚进入到写入模式时,position值为0,表示当前的写入位置为从头开始。
(2)每当一个数据写到缓冲区之后,position会向后移动到下一个可写的位置。
(3)初始的position值为0,最大可写值为limit–1。当position值达到limit时,缓冲区就已经无空间可写了。
在读模式下,position的值变化规则如下:
(1)当缓冲区刚开始进入到读取模式时,position会被重置为0。
(2)当从缓冲区读取时,也是从position位置开始读。读取数据后,position向前移动到下一个可读的位置。
(3)在读模式下,limit表示可以读上限。position的最大值,为最大可读上限limit,当position达到limit时,表明缓冲区已经无数据可读。
Buffer的读写模式具体如何切换呢?当新建了一个缓冲区实例时,缓冲区处于写入模式,这时是可以写数据的。在数据写入完成后,如果要从缓冲区读取数据,这就要进行模式的切换,可以使用(即调用)flip翻转方法,将缓冲区变成读取模式。
在从写入模式到读取模式的flip翻转过程中,position和limit属性值会进行调整,具体的规则是:
(1)limit属性被设置成写入模式时的position值,表示可以读取的最大数据位置;
(2)position由原来的写入位置,变成新的可读位置,也就是0,表示可以从头开始读。
- limit属性
Buffer类的limit属性,表示可以写入或者读取的最大上限,其属性值的具体含义,也与缓冲区的读写模式有关,在不同的模式下,limit的值的含义是不同的,具体分为以下两种情况:
(1)在写入模式下,limit属性值的含义为可以写入的数据最大上限。在刚进入到写入模式时,limit的值会被设置成缓冲区的capacity容量值,表示可以一直将缓冲区的容量写满。
(2)在读取模式下,limit的值含义为最多能从缓冲区中读取到多少数据。
一般来说,在进行缓冲区操作时,是先写入然后再读取的。当缓冲区写入完成后,就可以开始从Buffer读取数据,可以使用flip翻转方法,这时,limit的值也会进行调整。具体如何调整呢?将写入模式下的position值,设置成读取模式下的limit值,也就是说,将之前写入的最大数量,作为可以读取的上限值。
Buffer在flip翻转时的属性值调整,主要涉及position、limit两个属性,但是这种调整比较微妙,不是太好理解,下面是一个简单例子:
首先,创建缓冲区。新创建的缓冲区处于写入模式,其position值为0,limit值为最大容量capacity。
然后,向缓冲区写数据。每写入一个数据,position向后面移动一个位置,也就是position的值加1。这里假定写入了5个数,当写入完成后,position的值为5。
最后,使用flip方法将缓冲区切换到读模式。limit的值,先会被设置成写入模式时的position值,所以新的limit值是5,表示可以读取的最大上限是5。之后调整position值,新的position会被重置为0,表示可以从0开始读。
缓冲区切换到读模式后,就可以从缓冲区读取数据了,一直到缓冲区的数据读取完毕。
除了以上capacity(容量)、position(读写位置)、limit(读写的限制)三个重要属性之外,Buffer还有一个比较重要的标记属性:mark(标记)属性。该属性的大致作用为:在缓冲区操作过程当中,可以将当前的position的值临时存入mark属性中;需要的时候,可以再从mark中取出暂存的标记值,恢复到position属性中,重新从position位置开始处理。
Buffer的4个属性小结
除了capacity(容量)、position(读写位置)、limit(读写的限制)三个重要属性,第4个属性mark(标记)比较简单,该属性是一个暂存属性,用于暂存position的值,方便后面的重复使用。
下面用一个表格总结一下 Buffer类的4个重要属性,参见表3-1。
表3-1 Buffer四个重要属性的取值说明
| 属性 | 说明 |
|---|---|
| capacity | 容量,即可以容纳的最大数据量;在缓冲区创建时设置并且不能改变 |
| limit | 上限,缓冲区中当前的数据量 |
| position | 位置,缓冲区中下一个要被读或写的元素的索引 |
| mark | 调用mark()方法来设置mark=position,再调用reset()可以让position恢复到mark标记的位置,即position=mark |
详解NIO Buffer类的重要方法
本小节将详细介绍Buffer类常用的几个方法,包含Buffer实例创建、对Buffer实例的写入、读取、重复读、标记和重置等。
allocate()创建缓冲区
在使用Buffer(缓冲区)实例之前,我们首先需要获取Buffer子类的实例对象,并且分配内存空间。如果需要获取一个Buffer实例对象,并不是使用子类的构造器来创建一个实例对象,而是调用子类的allocate()方法。
下面的程序片段,演示如何获取一个整型的Buffer实例对象,代码如下:
package com.crazymakercircle.bufferDemo;
import com.crazymakercircle.util.Logger;
import java.nio.IntBuffer;
public class UseBuffer
{
//一个整型的Buffer静态变量
static IntBuffer intBuffer = null;
public static void allocateTest()
{
//创建了一个Intbuffer实例对象
intBuffer = IntBuffer.allocate(20);
Logger.debug("------------after allocate------------------");
Logger.debug("position=" + intBuffer.position());
Logger.debug("limit=" + intBuffer.limit());
Logger.debug("capacity=" + intBuffer.capacity());
}
//...省略其他代码
}
例子中,IntBuffer是具体的Buffer子类,通过调用IntBuffer.allocate(20),创建了一个Intbuffer实例对象,并且分配了20*4个字节的内存空间。运行程序之后,通过程序的输出结果,我们可以查看一个新建缓冲区实例对象的主要属性值,如下所示:
allocatTest \\|\\> ------------after allocate------------------
allocatTest \\|\\> position=0
allocatTest \\|\\> limit=20
allocatTest \\|\\> capacity=20
从上面的运行结果,可以看出:一个缓冲区在新建后,处于写入的模式,position属性(代表写入位置)的值为0,缓冲区的capacity容量值也是初始化时allocate方法的参数值(这里是20),而limit最大可写上限值也为的allocate方法的初始化参数值。
put()写入到缓冲区
在调用allocate方法分配内存、返回了实例对象后,缓冲区实例对象处于写模式,可以写入对象,而如果要写入对象到缓冲区,需要调用put方法。put方法很简单,只有一个参数,即为所需要写入的对象。只不过,写入的数据类型要求与缓冲区的类型保持一致。
接着前面的例子,向刚刚创建的intBuffer缓存实例对象中,写入的5个整数,代码如下:
package com.crazymakercircle.bufferDemo;
…省略import
public class UseBuffer
{
//一个整型的Buffer静态变量
static IntBuffer intBuffer = null;
//...省略了创建缓冲区的代码,具体查看前面小节的内容和随书源码
public static void putTest()
{
for (int i = 0; i < 5; i++)
{
//写入一个整数到缓冲区
intBuffer.put(i);
}
//输出缓冲区的主要属性值
Logger.debug("------------after putTest------------------");
Logger.debug("position=" + intBuffer.position());
Logger.debug("limit=" + intBuffer.limit());
Logger.debug("capacity=" + intBuffer.capacity());
}
//...省略其他代码
}
写入5个元素后,同样输出缓冲区的主要属性值,输出的结果如下:
putTest |> ------------after putTest------------------
putTest |> position=5
putTest |> limit=20
putTest |> capacity=20
从结果可以看到,写入了5个元素之后,缓冲区的position属性值变成了5,所以指向了第6个(从0开始的)可以进行写入的元素位置。而limit最大可写上限、capacity最大容量两个属性的值,都没有发生变化。
flip()翻转
向缓冲区写入数据之后,是否可以直接从缓冲区中读取数据呢?呵呵,不能。为什么呢?这时缓冲区还处于写模式,如果需要读取数据,还需要将缓冲区转换成读模式。flip()翻转方法是Buffer类提供的一个模式转变的重要方法,它的作用就是将写入模式翻转成读取模式。
接着前面的例子,演示一下flip()方法的使用:
package com.crazymakercircle.bufferDemo;
…省略import
public class UseBuffer
{
//一个整型的Buffer静态变量
static IntBuffer intBuffer = null;
//...省略了缓冲区的创建、写入数据的代码,具体查看前面小节的内容和随书源码
public static void flipTest()
{
//翻转缓冲区,从写入模式翻转成读取模式
intBuffer.flip();
//输出缓冲区的主要属性值
Logger.info("------------after flip ------------------");
Logger.info("position=" + intBuffer.position());
Logger.info("limit=" + intBuffer.limit());
Logger.info("capacity=" + intBuffer.capacity());
}
//...省略其他代码
}
在调用flip方法进行缓冲区的模式翻转之后,通过程序的输出内容可以看到,缓冲区的属性有了奇妙的变化,具体如下:
flipTest |> ------------after flipTest ------------------
flipTest |> position=0
flipTest |> limit=5
flipTest |> capacity=20
调用flip方法后,新模式下可读上限limit的值,变成了之前写入模式下的position属性值,也就是5;而新的读取模式下的position值,简单粗暴地变成了0,表示从头开始读取。
对flip()方法的从写入到读取转换的规则,再一次详细的介绍如下:
(1)首先,设置可读上限limit的属性值。将写入模式下的缓冲区中内容的最后写入位置position值,作为读取模式下的limit上限值。
(2)其次,把读的起始位置position的值设为0,表示从头开始读。
(3)最后,清除之前的mark标记,因为mark保存的是写入模式下的临时位置,发生模式翻转后,如果继续使用旧的mark标记,会造成位置混乱。
有关上面的三步,其实可以查看Buffer.flip()方法的源代码,具体代码如下:
public final Buffer flip() {
limit = position; //设置可读的长度上限limit,设置为写入模式下的position值
position = 0; //把读的起始位置position的值设为0,表示从头开始读
mark = UNSET_MARK; // 清除之前的mark标记
return this;
}
当然,新的问题来了:在读取完成后,如何再一次将缓冲区切换成写入模式呢?答案是:可以调用Buffer.clear()
清空或者Buffer.compact()压缩方法,它们可以将缓冲区转换为写模式。总体的Buffer模式转换,大致如图3-1所示。
图3-1 缓冲区读写模式的转换
get()从缓冲区读取
使用调用flip方法将缓冲区切换成读取模式之后,就可以开始从缓冲区中进行数据读取了。读取数据的方法很简单,可以调用get方法每次从position的位置读取一个数据,并且进行相应的缓冲区属性的调整。
接着前面flip的使用实例,演示一下缓冲区的读取操作,代码如下:
package com.crazymakercircle.bufferDemo;
…省略import
public class UseBuffer
{
//一个整型的Buffer静态变量
static IntBuffer intBuffer = null;
//…省略了缓冲区的创建、写入、翻转的代码,具体查看前面小节的内容和随书源码
public static void getTest()
{
//先读2个数据
for (int i = 0; i< 2; i++)
{
int j = intBuffer.get();
Logger.info("j = " + j);
}
//输出缓冲区的主要属性值
Logger.info("---------after get 2 int --------------");
Logger.info(“position=” + intBuffer.position());
Logger.info(“limit=” + intBuffer.limit());
Logger.info(“capacity=” + intBuffer.capacity());
//再读3个数据
for (int i = 0; i< 3; i++)
{
int j = intBuffer.get();
Logger.info("j = " + j);
}
//输出缓冲区的主要属性值
Logger.info("---------after get 3 int ---------------");
Logger.info(“position=” + intBuffer.position());
Logger.info(“limit=” + intBuffer.limit());
Logger.info(“capacity=” + intBuffer.capacity());
}
//…
}
//…省略其他代码
}
以上代码调用get方法从缓冲实例中先读取2个,再读取3个元素,运行后,输出的结果如下:
getTest |> ------------after get 2 int ------------------
getTest |> position=2
getTest |> limit=5
getTest |> capacity=20
getTest |> ------------after get 3 int ------------------
getTest |> position=5
getTest |> limit=5
getTest |> capacity=20
从程序的输出结果,我们可以看到,读取操作会改变可读位置position的属性值,而limit可读上限值并不会改变。在position值和limit的值相等时,表示所有数据读取完成,position指向了一个没有数据的元素位置,已经不能再读了。此时再读,会抛出BufferUnderflowException异常。
那么,在读完之后是否可以立即对缓冲区进行数据写入呢?答案是不能。现在还处于读取模式,我们必须调用Buffer.clear()或Buffer.compact()方法,即清空或者压缩缓冲区,将缓冲区切换成写入模式,让其重新可写。
此外还有一个问题:缓冲区是不是可以重复读呢?答案是可以的,既可以通过倒带方法rewind()去完成,也可以通过mark(
)和reset( )两个方法组合实现。
rewind()倒带
已经读完的数据,如果需要再读一遍,可以调用rewind()方法。rewind()也叫倒带,就像播放磁带一样倒回去,再重新播放。
接着前面的示例代码,继续rewind方法使用的演示,示例代码如下:
package com.crazymakercircle.bufferDemo;
…省略import
public class UseBuffer
{
//一个整型的Buffer静态变量
static IntBuffer intBuffer = null;
//…省略了缓冲区的写入和读取等代码,具体查看前面小节的内容和随书源码
public static void rewindTest() {
//倒带
intBuffer.rewind();
//输出缓冲区属性
Logger.info("------------after rewind ------------------");
Logger.info(“position=” + intBuffer.position());
Logger.info(“limit=” + intBuffer.limit());
Logger.info(“capacity=” + intBuffer.capacity());
}
//…省略其他代码
}
这个范例程序的执行结果如下:
rewindTest |> ------------after rewind ------------------
rewindTest |> position=0
rewindTest |> limit=5
rewindTest |> capacity=20
rewind
()方法,主要是调整了缓冲区的position属性与mark标记属性,具体的调整规则如下:
(1)position重置为0,所以可以重读缓冲区中的所有数据;
(2)limit保持不变,数据量还是一样的,仍然表示能从缓冲区中读取的元素数量;
(3)mark标记被清理,表示之前的临时位置不能再用了。
从JDK中可以查阅到Buffer.rewind()方法的源代码,具体如下:
public final Buffer rewind() {
position = 0;//重置为0,所以可以重读缓冲区中的所有数据
mark = -1; // mark标记被清理,表示之前的临时位置不能再用了
return this;
}
通过源代码,我们可以看到rewind()方法与flip()很相似,区别在于:倒带方法rewind()不会影响limit属性值;而翻转方法flip()会重设limit属性值。
在rewind倒带之后,就可以再一次读取,重复读取的示例代码如下:
package com.crazymakercircle.bufferDemo;
…省略import
public class UseBuffer
{
//一个整型的Buffer静态变量
static IntBuffer intBuffer = null;
//…省略了缓冲区的写入和读取、倒带等代码,具体查看前面小节的内容和随书源码
public static void reRead() {
for (int i = 0; i< 5; i++) {
if (i == 2) {
//临时保存,标记一下第3个位置
intBuffer.mark();
}
//读取元素
int j = intBuffer.get();
Logger.info("j = " + j);
}
//输出缓冲区的属性值
Logger.info("------------after reRead------------------");
Logger.info(“position=” + intBuffer.position());
Logger.info(“limit=” + intBuffer.limit());
Logger.info(“capacity=” + intBuffer.capacity());
}
//…省略其他代码
}
这段代码,和前面的读取示例代码基本相同,只是增加了一个mark调用。大家可以通过随书源码工程执行以上代码并观察输出结果,具体的输出与前面的类似,这里不做赘述。
mark( )和reset( )
mark( )和reset(
)两个方法是成套使用的:Buffer.mark()方法将当前position的值保存起来,放在mark属性中,让mark属性记住这个临时位置;之后,可以调用Buffer.reset()方法将mark的值恢复到position中。
说 明
Buffer.mark()和Buffer.reset()两个方法都涉及到mark属性的使用。mark()方法与mark属性,二者的名字虽然相同,但是一个是Buffer类的成员方法,另一个是Buffer类的成员属性,不能混淆。
例如,可以在前面重复读取的示例代码中,在读到第3个元素(i为2时)时,可以调用mark()方法,把当前位置position的值保存到mark属性中,这时mark属性的值为2。
然后,就可以调用reset(
)方法,将mark属性的值恢复到position中,这样就可以从位置2(第三个元素)开始重复读取。
继续接着前面重复读取的代码,进行mark( )方法和reset( )方法的示例演示,代码如下:
package com.crazymakercircle.bufferDemo;
…省略import
public class UseBuffer
{
//一个整型的Buffer静态变量
static IntBuffer intBuffer = null;
//…省略了缓冲区的倒带、重复读取等代码,具体查看前面小节的内容和随书源码
//演示前提:
//在前面的reRead()演示方法中,已经通过mark()方法,暂存了position值
public static void afterReset() {
Logger.info("------------after reset------------------");
//把前面保存在mark中的值恢复到position
intBuffer.reset();
//输出缓冲区的属性值
Logger.info(“position=” + intBuffer.position());
Logger.info(“limit=” + intBuffer.limit());
Logger.info(“capacity=” + intBuffer.capacity());
//读取并且输出元素
for (int i =2; i< 5; i++) {
int j = intBuffer.get();
Logger.info("j = " + j);
}
}
//…省略其他代码
}
在上面的代码中,首先调用reset()把mark中的值恢复到position中,因此读取的位置position就是2,表示可以再次开始从第3个元素开始读取数据。上面的程序代码的输出结果是:
afterReset |> ------------after reset------------------
afterReset |> position=2
afterReset |> limit=5
afterReset |> capacity=20
afterReset |> j = 2
afterReset |> j = 3
afterReset |> j = 4
调用reset方法之后,position的值为2,此时去读取缓冲区,输出了后面的三个元素为2、3、4。
clear( )清空缓冲区
在读取模式下,调用clear()方法将缓冲区切换为写入模式。此方法的作用:
(1)会将position清零;
(2)limit设置为capacity最大容量值,可以一直写入,直到缓冲区写满。
接着上面的实例,演示一下clear( )方法的使用,大致的代码如下:
package com.crazymakercircle.bufferDemo;
…省略import
public class UseBuffer
{
//一个整型的Buffer静态变量
static IntBuffer intBuffer = null;
//…省略了缓冲区的创建、写入、读取等代码,具体查看前面小节的内容和随书源码
public static void clearDemo() {
Logger.info("------------after clear------------------");
//清空缓冲区,进入写入模式
intBuffer.clear();
//输出缓冲区的属性值
Logger.info(“position=” + intBuffer.position());
Logger.info(“limit=” + intBuffer.limit());
Logger.info(“capacity=” + intBuffer.capacity());
}
//…省略其他代码
}
这个程序运行之后,结果如下:
main |>清空
clearDemo |> ------------after clear------------------
clearDemo |> position=0
clearDemo |> limit=20
clearDemo |> capacity=20
在缓冲区处于读取模式时,调用clear(),缓冲区会被切换成写入模式。调用clear()之后,我们可以看到清空了position(写入的起始位置)的值,其值被设置为0,并且limit值(写入的上限)为最大容量。
使用Buffer类的基本步骤
总体来说,使用Java NIO Buffer类的基本步骤如下:
(1)使用创建子类实例对象的allocate( )方法,创建一个Buffer类的实例对象。
(2)调用put( )方法,将数据写入到缓冲区中。
(3)写入完成后,在开始读取数据前,调用Buffer.flip(
)方法,将缓冲区转换为读模式。
(4)调用get( )方法,可以从缓冲区中读取数据。
(5)读取完成后,调用Buffer.clear(
)方法或Buffer.compact()方法,将缓冲区转换为写入模式,可以继续写入。
详解NIO Channel(通道)类
前面提到,Java
NIO中,一个socket连接使用一个Channel(通道)来表示。然而,从更广泛的层面来说,一个通道可以表示一个底层的文件描述符,例如硬件设备、文件、网络连接等。然而,远远不止如此,除了可以对应到底层文件描述符。所以,文件描述符相对应,Java
NIO的通道可以更加细化。例如,对应不同的网络传输协议类型,在Java中都有不同的NIO
Channel(通道)实现。
Channel(通道)的主要类型
这里不对Java
NIO全部通道类型进行过多的描述,仅仅聚焦于介绍其中最为重要的四种Channel(通道)实现:FileChannel、SocketChannel、ServerSocketChannel、DatagramChannel。
对于以上四种通道,说明如下:
(1)FileChannel文件通道,用于文件的数据读写;
(2)SocketChannel套接字通道,用于Socket套接字TCP连接的数据读写;
(3)ServerSocketChannel服务器套接字通道(或服务器监听通道),允许我们监听TCP连接请求,为每个监听到的请求,创建一个SocketChannel套接字通道;
(4)DatagramChannel数据报通道,用于UDP协议的数据读写。
这个四种通道,涵盖了文件IO、TCP网络、UDP
IO三类基础IO读写操作。下面从通道的获取、读取、写入、关闭四个重要的操作入手,对四种通道进行简单的介绍。
FileChannel文件通道
FileChannel是专门操作文件的通道。通过FileChannel,既可以从一个文件中读取数据,也可以将数据写入到文件中。特别申明一下,FileChannel为阻塞模式,不能设置为非阻塞模式。
下面分别介绍:FileChannel的获取、读取、写入、关闭四个操作。
- 获取FileChannel通道
可以通过文件的输入流、输出流获取FileChannel文件通道,示例如下:
//创建一个文件输入流
FileInputStream fis = new FileInputStream(srcFile);
//获取文件流的通道
FileChannel inChannel = fis.getChannel();
//创建一个文件输出流
FileOutputStream fos = new FileOutputStream(destFile);
//获取文件流的通道
FileChannel outchannel = fos.getChannel();
也可以通过RandomAccessFile文件随机访问类,获取FileChannel文件通道实例,代码如下:
// 创建RandomAccessFile随机访问对象
RandomAccessFile rFile = new RandomAccessFile(“filename.txt”,“rw”);
//获取文件流的通道(可读可写)
FileChannel channel = rFile.getChannel();
- 读取FileChannel通道
在大部分应用场景,从通道读取数据都会调用通道的int
read(ByteBufferbuf)方法,它从通道读取到数据写入到ByteBuffer缓冲区,并且返回读取到的数据量。
RandomAccessFile aFile = new RandomAccessFile(fileName, “rw”);
//获取通道(可读可写)
FileChannel channel=aFile.getChannel();
//获取一个字节缓冲区
ByteBuffer buf = ByteBuffer.allocate(CAPACITY);
int length = -1;
//调用通道的read方法,读取数据并买入字节类型的缓冲区
while ((length = channel.read(buf)) != -1) {
//……省略buf中的数据处理
}
说明:以上代码channel.read(buf)虽然是读取通道的数据,对于通道来说是读取模式,但是对于ByteBuffer缓冲区来说则是写入数据,这时,ByteBuffer缓冲区处于写入模式。
说 明
以上代码中channel.read(buf)读取通道的数据时,虽然对于通道来说是读取模式,但是对于ByteBuffer缓冲区来说则是写入数据,这时,ByteBuffer缓冲区处于写入模式。
- 写入FileChannel通道
写入数据到通道,在大部分应用场景,都会调用通道的write(ByteBuffer)方法,此方法的参数是一个ByteBuffer缓冲区实例,是待写数据的来源。
write(ByteBuffer)方法的作用,是从ByteBuffer缓冲区中读取数据,然后写入到通道自身,而返回值是写入成功的字节数。
//如果buf处于写入模式(如刚写完数据),需要flip翻转buf,使其变成读取模式
buf.flip();
int outlength = 0;
//调用write方法,将buf的数据写入通道
while ((outlength = outchannel.write(buf)) != 0) {
System.out.println(“写入的字节数:” + outlength);
}
在以上的outchannel.write(buf)调用中,对于入参buf实例来说,需要从其中读取数据写入到outchannel通道中,所以入参buf必须处于读取模式,不能处于写入模式。
4.关闭通道
当通道使用完成后,必须将其关闭。关闭非常简单,调用close( )方法即可。
//关闭通道
channel.close( );
5.强制刷新到磁盘
在将缓冲区写入通道时,出于性能原因,操作系统不可能每次都实时将写入数据落地(或刷新)到磁盘,完成最终的数据保存。
如果在将缓冲数据写入通道时,需要保证数据能落地写入到磁盘,可以在写入后调用一下FileChannel的force()方法。
//强制刷新到磁盘
channel.force(true);
使用FileChannel完成文件复制的实践案例
下面是一个简单的实战案例:使用文件通道复制文件。其具体的功能是:使用FileChannel文件通道,将原文件复制一份,把原文中的数据都复制到目标文件中。完整代码如下:
package com.crazymakercircle.iodemo.fileDemos;
//…省略import的类,具体请参见源代码工程
public class FileNIOCopyDemo {
public static void main(String[] args) {
//演示复制资源文件
nioCopyResouceFile();
}
/**
* 复制两个资源目录下的文件
*/
public static void nioCopyResouceFile() {
//源
String sourcePath = NioDemoConfig.FILE_RESOURCE_SRC_PATH;
String srcPath = IOUtil.getResourcePath(sourcePath);
Logger.info(“srcPath=” + srcPath);
//目标
String destPath = NioDemoConfig.FILE_RESOURCE_DEST_PATH;
String destDecodePath = IOUtil.builderResourcePath(destPath);
Logger.info(“destDecodePath=” + destDecodePath);
//复制文件
nioCopyFile(srcDecodePath, destDecodePath);
}
/**
* nio方式复制文件
* @param srcPath 源路径
* @param destPath 目标路径
*/
public static void nioCopyFile(String srcPath, String destPath){
File srcFile = new File(srcPath);
File destFile = new File(destPath);
try {
//如果目标文件不存在,则新建
if (!destFile.exists()) {
destFile.createNewFile();
}
long startTime = System.currentTimeMillis();
FileInputStream fis = null;
FileOutputStream fos = null;
FileChannel inChannel = null; //输入通道
FileChannel outchannel = null; //输出通道
try {
fis = new FileInputStream(srcFile);
fos = new FileOutputStream(destFile);
inChannel = fis.getChannel();
outchannel = fos.getChannel();
int length = -1;
//新建buf,处于写入模式
ByteBufferbuf = ByteBuffer.allocate(1024);
//从输入通道读取到buf
while ((length = inChannel.read(buf)) != -1) {
//buf第一次模式切换:翻转buf,从写入模式变成读取模式
buf.flip();
int outlength = 0;
//将buf写入到输出的通道
while ((outlength = outchannel.write(buf)) != 0) {
System.out.println(“写入的字节数:” + outlength);
}
//buf第二次模式切换:清除buf,变成写入模式
buf
以上是关于Java NIO (图解+秒懂+史上最全)的主要内容,如果未能解决你的问题,请参考以下文章