PCS2021:基于CNN的后处理进行质量增强
Posted Dillon2015
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PCS2021:基于CNN的后处理进行质量增强相关的知识,希望对你有一定的参考价值。
本文来自PCS2021论文《Model Selection CNN-based VVC Quality Enhancement》

论文提出了适用于VVC的基于CNN的后处理方法来进行质量增强(QE),并且在编码端提供了多个训练好的模型,可以在帧级和块级使用模型选择(MS)策略选择最优的模型,并传到解码端。基于CNN的后处理方法在RA配置下BD-Rate增益为1.3%,加上MS策略又可以获得0.5%的BD-Rate增益。
质量增强算法
编码信息
时域、空域特征和带宽限制等能反映信号的特点,因此在论文的QE算法中利用了下面两个编码信息来帮助CNN更好的去除压缩失真:
1)QP map:QP通过控制量化步长来平衡视频的码率和失真。较大的QP会导致较长的量化步长,使得变换系数丢失更高高频信息从而降低码率同时引入更多失真。
在论文的QE算法中,会为每帧构建一个归一化的QP map,并将它和重建帧一起送入网络。对宽为W,高为H的帧,QP map 计算如下:
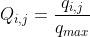
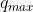 是最大的QP值,对于VVC即为63。对于CQP模式,整帧的QP map都为相同的常数;对于CBR模式,QP map中不同位置块处的值不同。
是最大的QP值,对于VVC即为63。对于CQP模式,整帧的QP map都为相同的常数;对于CBR模式,QP map中不同位置块处的值不同。
2)预测信号:重建信号由预测信号和残差信号相加得到。对于不同的编码方式(帧内或帧间),会有不同的预测方法:帧内、单向帧间、双向帧间、skip等。无论采用何种方式,论文的QE算法将预测信号作为第二个编码信息用于CNN中。且预测信号和重建帧尺寸一样,被一起送入CNN网络。
QE网络
网络结构如Fig.2所示,
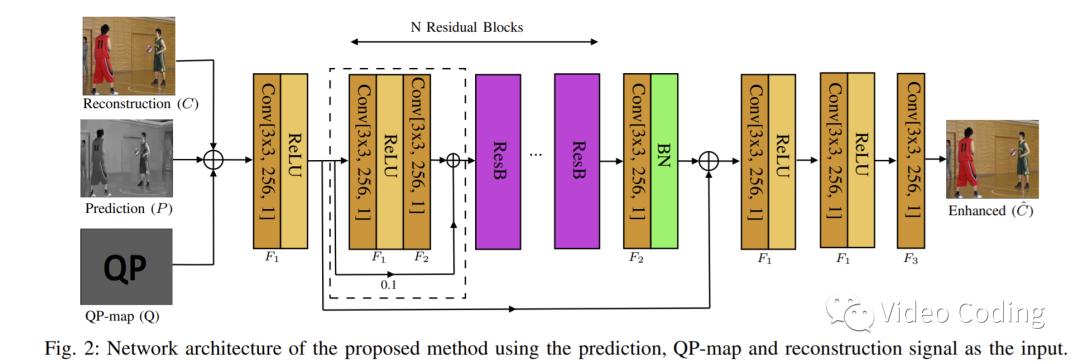
是连接后的输入信号, 是网络的输出。整个过程可用如下公式描述,
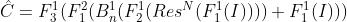
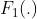 和
和 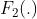 是3x3x256的卷积层, 带有ReLU激活层, 不带。
是3x3x256的卷积层, 带有ReLU激活层, 不带。 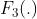 是带ReLU的3x3x1的卷积层。上角标表示对应层在网络中连续重复的次数。
是带ReLU的3x3x1的卷积层。上角标表示对应层在网络中连续重复的次数。
基于上面的网络结构和编码信息,一共训练了4个模型。前两个模型 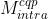 和
和 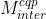 的输入是由重建信号C,QP map 和预测信号P连接而成,
的输入是由重建信号C,QP map 和预测信号P连接而成,
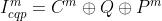
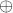 表示连接操作,m表示模式(帧内或帧间)。另外两个模型
表示连接操作,m表示模式(帧内或帧间)。另外两个模型 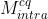 和
和 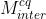 的输入不包含预测信号P,
的输入不包含预测信号P,
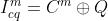
表1中是4个模型的详细信息。

模型使用L1损失函数,如下:
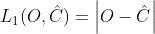
模型选择MS
帧类型不同,预测信号也会有差别。对于I帧,所有块都采用帧内预测,而对于P/B帧既可能有帧内预测块也可能有帧间预测块。同一帧中可能存在不同类型的失真,需要不同的模型进行质量增强。因此,论文基于前面的4个模型提出帧级和CTB级模型选择MS。
在CTB级,使用前面的4个模型分别增强,选择MSE最小的,
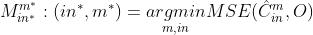
为了告诉解码器使用了哪个模型,需要在码流中传输帧级和CTB级标志位。帧级标志位 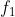 表示码流中是否有CTB级标志位,如果
表示码流中是否有CTB级标志位,如果  则解码器根据帧类型使用默认模型
则解码器根据帧类型使用默认模型 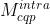 和
和 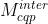 。否则,根据CTB级标志位
。否则,根据CTB级标志位 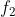 和
和 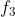 选择模型。
选择模型。
编码端MS过程如下,

整个QE流程如Fig.3所示,

实验结果
数据集和训练配置
使用BVI-DVC数据集训练网络,其中包含800条视频。DIV2K和Fliker2K数据集被用来训练帧内编码的帧,分别包含900和2650个高质量图片。这些视频和图像都被转为10bit 420格式,仅用亮度分量来训练模型。
为训练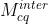 和 ,将视频使用VTM10编码,配置为RA (Main10 profile),QP={22, 27, 32, 37}。为训练
和 ,将视频使用VTM10编码,配置为RA (Main10 profile),QP={22, 27, 32, 37}。为训练 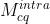 和 ,DIV2K和Fliker2K数据集使用All Intra (AI)配置编码。最终,获得了16000个帧间和7500个帧内图像用于训练对应模型。
和 ,DIV2K和Fliker2K数据集使用All Intra (AI)配置编码。最终,获得了16000个帧间和7500个帧内图像用于训练对应模型。
测试序列选用JVET CTC中的19条序列。
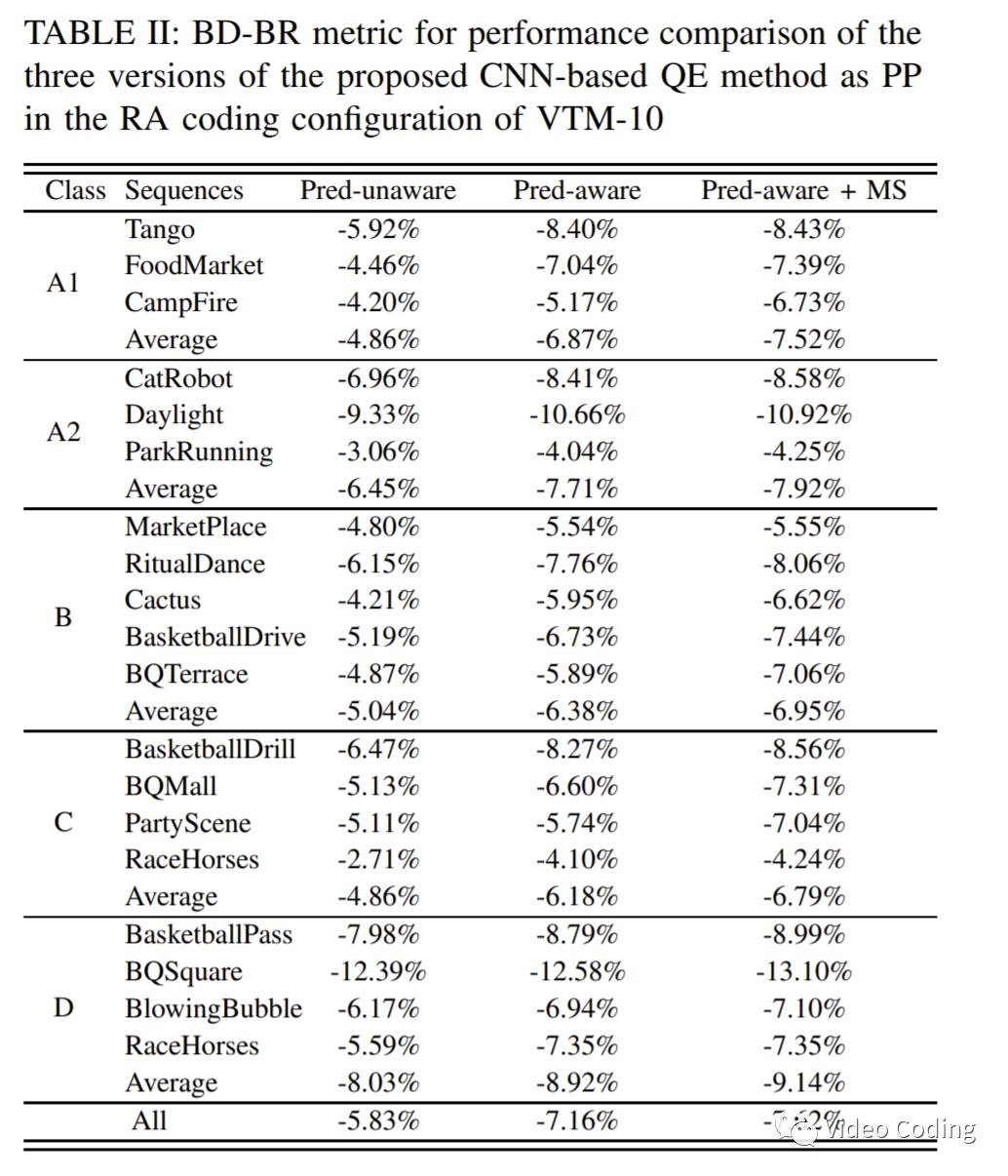
实验结果如表2所示,不带预测信息的QE、带预测信息的QE、带预测信息和MS的QE的BD-Rate增益分别为5.83%,7.16%,7.62%,可以看见添加预测信息后码率节省了1.33%,增加MS后又节省了0.46%的码率。
感兴趣的请关注微信公众号Video Coding

以上是关于PCS2021:基于CNN的后处理进行质量增强的主要内容,如果未能解决你的问题,请参考以下文章