传统目标检测方法研究
Posted 开始学AI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了传统目标检测方法研究相关的知识,希望对你有一定的参考价值。
1 传统算法目标检测
区域选择 --> 特征提取 --> 特征分类
1.1 区域选择 python 实现 图像滑动窗口
区域选取:首先选取图像中可能出现物体的位置,由于物体位置、大小都不固定,因此传统算法通常使用滑动窗口(Sliding Windows)算法,但这种算法会存在大量的冗余框,并且计算复杂度高。
滑动窗口: 固定一个窗口,截取图片
1.1.1 以滑动窗口方式切分图像
import cv2
def sliding_window(src_img,step,windowsize):
'''
src_img : 源图像
out_img : 输出图像
step : 步进步长 元组类型
windowsize :窗口大小 元组类型
'''
cnt = 0 # 记录滑动窗口数目
for y in range(0,src_img.shape[0],step[1]):
for x in range(0,src_img.shape[1],step[0]):
image_patch = src_img[y:y+windowsize[0],x:x+windowsize[1]]
cnt += 1
cv2.imwrite("image/sliding_img/"+str(cnt)+".png",image_patch)
if __name__ == "__main__":
img = cv2.imread("image/src_img/1.jpg")
step = (50,50)
windowsize = (100,100)
sliding_window(img,step,windowsize)
1.1.2 滑动窗口简单动画演示
import cv2
import numpy as np
import matplotlib.pyplot as plt
def sliding_window(path,step,windowsize):
'''
src_img : 源图像
out_img : 输出图像
step : 步进步长 元组类型
windowsize :窗口大小 元组类型
'''
# cv2.fillConvexPoly()函数可以用来填充凸多边形,只需要提供凸多边形的顶点即可.
src_img = cv2.imread(path)
for y in range(0,src_img.shape[0],step[1]):
for x in range(0,src_img.shape[1],step[0]):
# 先计算坐标
x_min = x
y_min = y
x_max = x + windowsize[1]
y_max = y + windowsize[0]
src_img1 = cv2.imread(path)
src_img2 = cv2.cvtColor(src_img1,cv2.COLOR_BGR2RGB)
rectangle = np.array([[x_min,y_min],[x_min,y_max],[x_max,y_max],[x_max,y_min]])
# cv2.fillConvexPoly 单个多边形填充
cv2.fillConvexPoly(src_img2,rectangle,(0,0,0)) # (0,0,0) 颜色填充
plt.imshow(src_img2)
plt.show()
plt.pause(0.1)
plt.clf()
if __name__ == "__main__":
plt.ion() # 使得plt.show()显示后不暂停,交互模式,可以使用plt.ioff()停止
path = "image/src_img/1.jpg"
step = (50,50)
windowsize = (200,200)
sliding_window(path,step,windowsize)
1.2 特征提取
特征提取:在得到物体位置后,通常使用人工精心设计的提取器进行特征提取,如SIFT和HOG等。由于提取器包含的参数较少,并且人工设计的鲁棒性较低,因此特征提取的质量并不高。
1.2.1 python提取图像SIFT特征
SIFT(Scale-invariant feature transform),也叫尺度不变特征变换算法,是David Lowe于1999年提出的局部特征描述子(Descriptor),并于2004年进行了更深入的发展和完善。Sift特征匹配算法可以处理两幅图像之间发生平移、旋转、仿射变换情况下的匹配问题,具有很强的匹配能力。Mikolajczyk对包括Sift算子在内的十种局部描述子所做的不变性对比实验中,Sift及其扩展算法已被证实在同类描述子中具有最强的健壮性。
其应用范围包含物体辨识、机器人地图感知与导航、影像缝合、3D模型建立、手势辨识、影像追踪和动作比对。局部影像特征的描述与侦测可以帮助辨识物体,SIFT 特征是基于物体上的一些局部外观的兴趣点而与影像的大小和旋转无关。对于光线、噪声、些微视角改变的容忍度也相当高。基于这些特性,它们是高度显著而且相对容易撷取,在母数庞大的特征数据库中,很容易辨识物体而且鲜有误认。
python-opencv提取SIFT特征为以下步骤:
import cv2
import numpy as np
from matplotlib import pyplot as plt
img = cv2.imread('image/src_img/1.jpg')
cv2.imshow("original",img)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
sift = cv2.xfeatures2d.SIFT_create() # 创建sift对象
keypoints, descriptor = sift.detectAndCompute(gray, None) # 检测单通道图像特征点
# 绘制特征点
cv2.drawKeypoints(image = img,
outImage = img,
keypoints = keypoints,
flags = cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS,
color = (51,163,236))
cv2.imshow("SIFT",img)
cv2.waitKey(0)
cv2.destroyAllWindows()

为了体现SIFT特征的作用,我将图片加入旋转,看是否能实现图像匹配。
import cv2
import numpy as np
from matplotlib import pyplot as plt
img = cv2.imread('image/src_img/1.jpg')
img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
# 为了能够在任意位置进行旋转变换,OpenCV提供了一个函数:cv2.getRotationMarix2D( ),这个函数需要三个参数,旋转中心,旋转角度,旋转后图像的缩放比例:
rows, cols = img.shape[:2]
M1 = cv2.getRotationMatrix2D((cols/2, rows/2), 45, 0.5)
# cv2.warpAffine(img, rot_mat, (img.shape[1], img.shape[0]))
# 参数说明: img表示输入的图片,rot_mat表示仿射变化矩阵,(image.shape[1], image.shape[0])表示变换后的图片大小
img1 = cv2.warpAffine(img, M1, (cols, rows))
gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
gray1 = cv2.cvtColor(img1, cv2.COLOR_RGB2GRAY)
sift = cv2.ORB_create() # 创建sift对象
keypoints, descriptor = sift.detectAndCompute(gray, None) # 检测单通道图像特征点和描述符
keypoints1, descriptor1 = sift.detectAndCompute(gray1, None) # 检测单通道图像特征点和描述符
# 创建BFMatcher对象
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
mathces = bf.match(descriptor,descriptor1) #匹配描述子
mathces=sorted(mathces,key=lambda x:x.distance) #据距离来排序
# 绘制特征点
img2 = cv2.drawMatches(img1=img,
keypoints1=keypoints,
img2=img1,
keypoints2=keypoints1,
matches1to2=mathces[:10],
outImg = None
) #画出匹配关系
plt.imshow(img2)
plt.show()
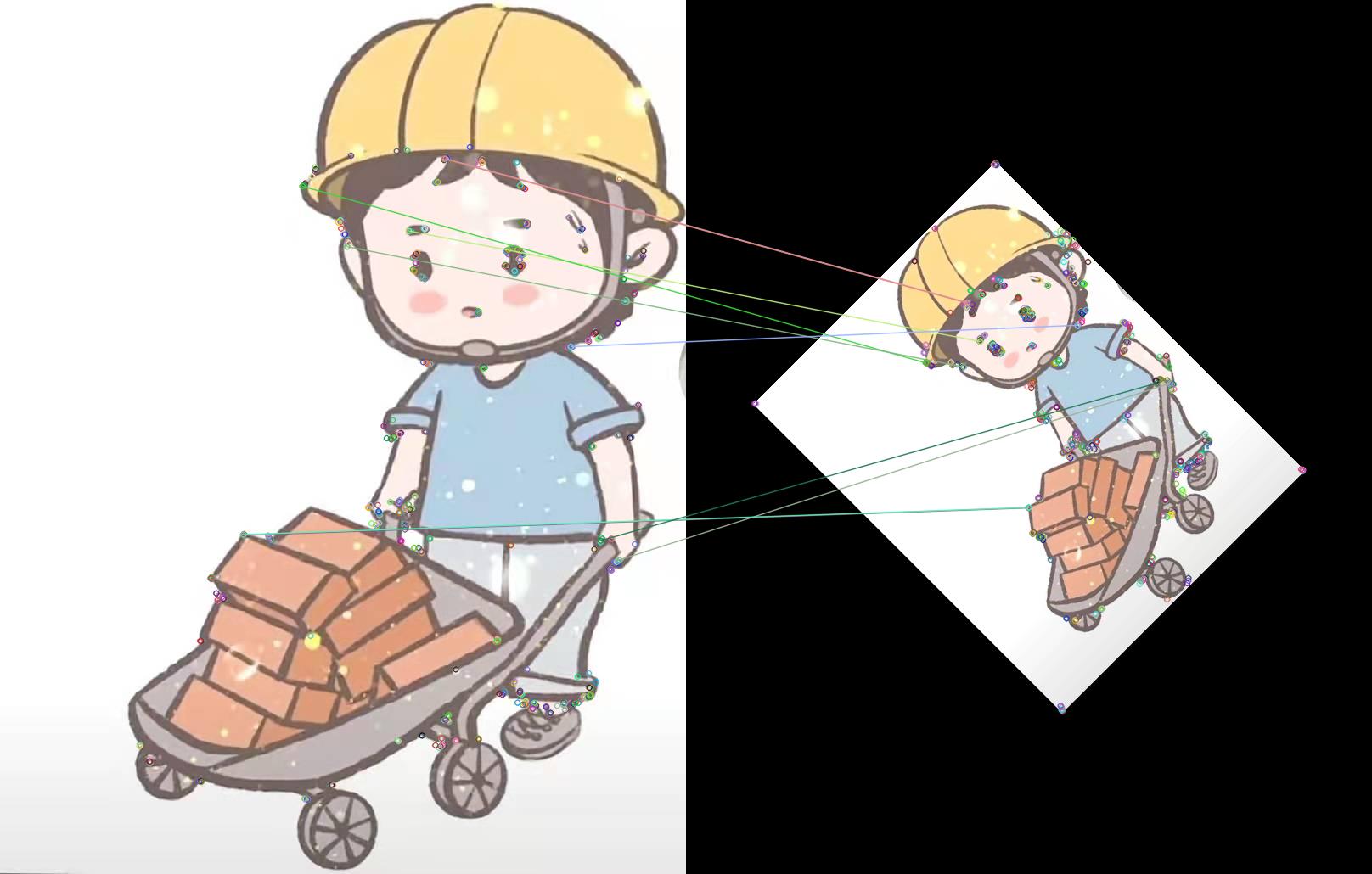
从结果可以看出,SIFT特征能有效应对几何变换,能够很好实现图像匹配。
1.2.2 python提取图像HOG特征
方向梯度直方图(Histogram of Oriented Gradient, HOG)特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子。它通过计算和统计图像局部区域的梯度方向直方图来构成特征。Hog特征结合SVM分类器已经被广泛应用于图像识别中,尤其在行人检测中获得了极大的成功。需要提醒的是,HOG+SVM进行行人检测的方法是法国研究人员Dalal在2005的CVPR上提出的,而如今虽然有很多行人检测算法不断提出,但基本都是以HOG+SVM的思路为主。
HOG特征提取步骤:
1)灰度化(将图像看做一个x,y,z(灰度)的三维图像);
2)采用Gamma校正法对输入图像进行颜色空间的标准化(归一化);目的是调节图像的对比度,降低图像局部的阴影和光照变化所造成的影响,同时可以抑制噪音的干扰;
3)计算图像每个像素的梯度(包括大小和方向);主要是为了捕获轮廓信息,同时进一步弱化光照的干扰。
4)将图像划分成小cells(例如6*6像素/cell);
5)统计每个cell的梯度直方图(不同梯度的个数),即可形成每个cell的descriptor;
6)将每几个cell组成一个block(例如3*3个cell/block),一个block内所有cell的特征descriptor串联起来便得到该block的HOG特征descriptor。
7)将图像image内的所有block的HOG特征descriptor串联起来就可以得到该image(你要检测的目标)的HOG特征descriptor了。这个就是最终的可供分类使用的特征向量了。
python-opencv 提取HOG特征
HOG特征介绍参考视频
HOG特征介绍参考资料,这篇文章对过程讲得很清楚,重点看
通过opencv中的cv2.HOGDescriptor(winSize,blockSize,blockStride,cellSize,Bin)可以方便直接地获得HOG特征描述算子。
import cv2
import numpy as np
from matplotlib import pyplot as plt
img = cv2.imread('image/src_img/1.jpg')
# 创建HOG对象,参数使用默认参数
hog = cv2.HOGDescriptor()
winStride = (8, 8)
padding = (8, 8)
hog_feature = hog.compute(img,winStride,padding) # 一定要有后面两个参数
print(hog_feature.shape) # 张量
print(hog_feature.reshape((-1,))) # 转变为向量
print(hog_feature.reshape((-1,)).shape)
为了更好展示HOG特征可视化结果,这里采用了scikit-image包展示,参考链接
使用scikit-image之前,需要pip install scikit-image 进行安装
pip install scikit-image
可视化代码如下:
import matplotlib.pyplot as plt
import cv2
from skimage.feature import hog
from skimage import exposure
image = cv2.imread('image/src_img/1.jpg')
image = cv2.cvtColor(image,cv2.COLOR_BGR2RGB)
fd, hog_image = hog(image, orientations=8, pixels_per_cell=(16, 16),
cells_per_block=(1, 1), visualize=True)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(8, 4), sharex=True, sharey=True)
ax1.axis('off')
ax1.imshow(image, cmap=plt.cm.gray)
ax1.set_title('Input image')
# Rescale histogram for better display
hog_image_rescaled = exposure.rescale_intensity(hog_image, in_range=(0, 10))
ax2.axis('off')
ax2.imshow(hog_image_rescaled, cmap=plt.cm.gray)
ax2.set_title('Histogram of Oriented Gradients')
plt.savefig("HOG_image.png")
plt.show()
可视化结果如下:

以上是关于传统目标检测方法研究的主要内容,如果未能解决你的问题,请参考以下文章