爬虫“入侵”王者六周年,拿来吧你!
Posted 远方的星
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫“入侵”王者六周年,拿来吧你!相关的知识,希望对你有一定的参考价值。
🍑前言
王者荣耀六周年来临,有很多“丰厚”的活动及奖励,但有一个非常小的活动可能大家没有注意到,全英雄的同人Q版头像,也发布在游戏中。对于这么可爱的头像,我自然不会放过啦,但在游戏中一点一点地保存,太吃力了。于是,就想到了爬虫😆
🍇准备工作
于是,我先找到了活动的pc端网址:
https://pvp.qq.com/cp/a20211015xdtxm/
强烈建议,这个网址,双开浏览器打开!
打开后,是这个样子😂
但是不用担心,点击右上角设置,进入全屏即可
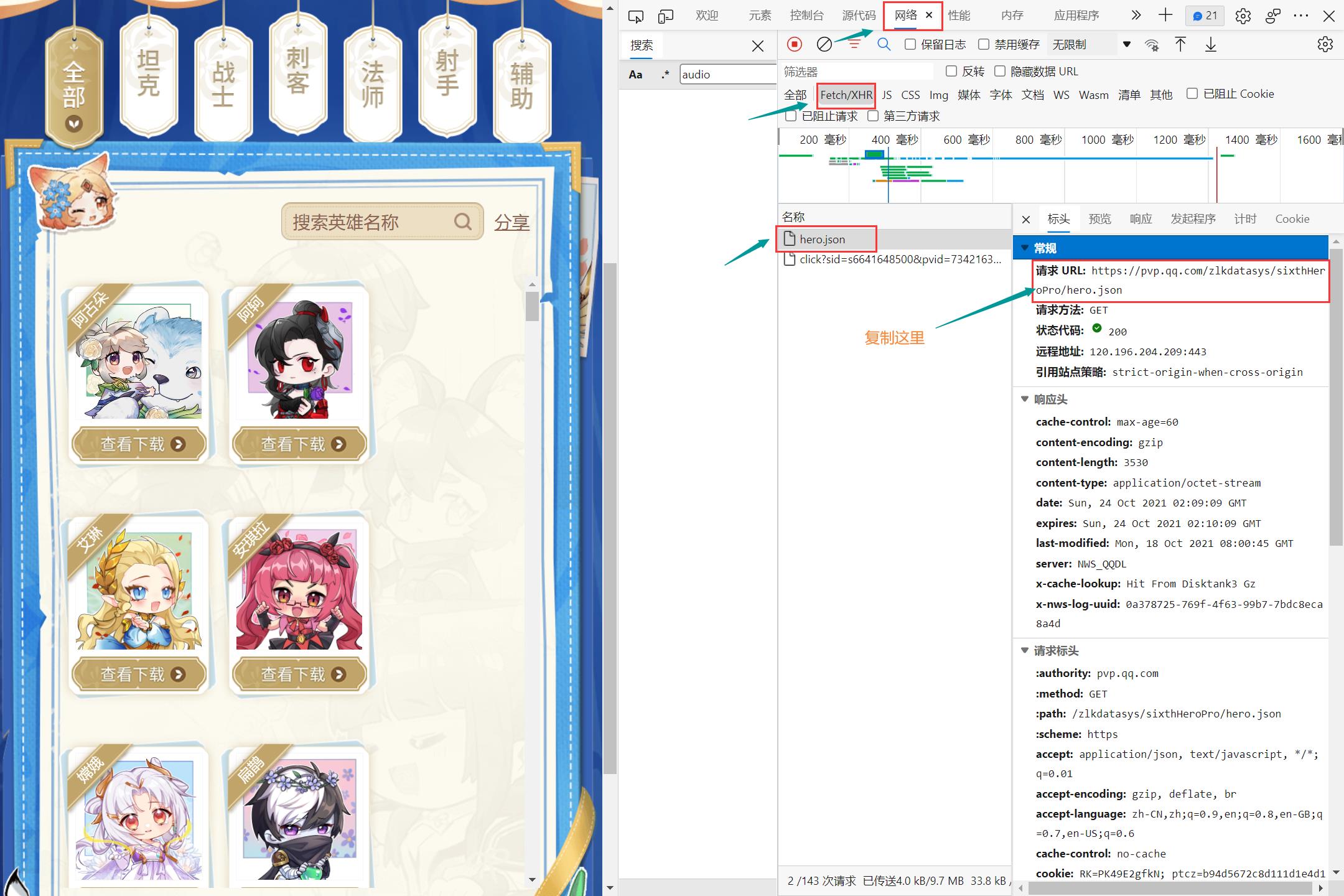
经过验证,所需数据为json类型的数据
右击检查–网络–XHR–hero.json
在预览中即可发现想要的数据。于是复制
🍋完整代码及注释如下
# -*- coding: UTF-8 -*-
"""
# @Time: 2021/10/23 18:56
# @Author: 远方的星
# @CSDN: https://blog.csdn.net/qq_44921056
"""
import json
import chardet
import requests
from tqdm import tqdm
from fake_useragent import UserAgent
# 随机产生请求头
ua = UserAgent(verify_ssl=False, path='D:/Pycharm/fake_useragent.json')
# 随机切换请求头
def random_ua():
headers = {
"user-agent": ua.random
}
return headers
# 下载图片
def download(image, image_path):
with open(image_path, 'wb') as f:
f.write(image)
f.close()
def main():
path = 'D:/Edge下载/王者头像/'
url = 'https://pvp.qq.com/zlkdatasys/sixthHeroPro/hero.json'
res = requests.get(url=url, headers=random_ua())
res.encoding = chardet.detect(res.content)['encoding'] # 统一字符编码
res = res.text
data_s = json.loads(res)['6znxdb_2403'] # json格式化,并提取数据
print('开始下载,请稍后^-^')
for i in tqdm(range(len(data_s))): # 对数据列表进行遍历
hero_name = data_s[i]['mz6zn_6616'] + '.jpg' # 获取英雄头像名称并提前构造,下载后文件的名称
image_url = 'https:' + data_s[i]['yxxt6z_6590'] # 获取图片下载链接
image = requests.get(url=image_url, headers=random_ua()).content # 获取图片
image_path = path + hero_name # 拼接下载路径
download(image, image_path) # 下载
print('下载完成 ^-^')
if __name__ == '__main__':
main()
🍉头像压缩包下载
不想动手去爬的小伙伴也不用担心,我已经爬过了,将所有的图片已压缩上传,用百度网盘下载即可。
-
提取码:
ata0
如果对你有帮助,记得点个赞👍哟,也是对作者最大的鼓励🙇♂️。
如有不足之处可以在评论区👇多多指正,我会在看到的第一时间进行修正
作者:远方的星
CSDN:https://blog.csdn.net/qq_44921056
本文仅用于交流学习,未经作者允许,禁止转载,更勿做其他用途,违者必究。
以上是关于爬虫“入侵”王者六周年,拿来吧你!的主要内容,如果未能解决你的问题,请参考以下文章