深度学习-神经网络卷积核理解
Posted Tc.小浩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习-神经网络卷积核理解相关的知识,希望对你有一定的参考价值。
一、前言
- 卷积核(convolutional kernel):可以看作对某个局部的加权求和;它是对应局部感知,它的原理是在观察某个物体时我们既不能观察每个像素也不能一次观察整体,而是先从局部开始认识,这就对应了卷积。卷积核的大小一般有1x1,3x3和5x5的尺寸(一般是奇数x奇数)。
卷积核的个数就对应输出的通道数(channels),这里需要说明的是对于输入的每个通道,输出每个通道上的卷积核是不一样的。比如输入是28x28x192(WxDxK,K代表通道数),然后在3x3的卷积核,卷积通道数为128,那么卷积的参数有3x3x192x128,其中前两个对应的每个卷积里面的参数,后两个对应的卷积总的个数(一般理解为,卷积核的权值共享只在每个单独通道上有效,至于通道与通道间的对应的卷积核是独立不共享的,所以这里是192x128)。
- 池化(pooling):卷积特征往往对应某个局部的特征。要得到global的特征需要将全局的特征执行一个aggregation(聚合)。池化就是这样一个操作,对于每个卷积通道,将更大尺寸(甚至是global)上的卷积特征进行pooling就可以得到更有全局性的特征。这里的pooling当然就对应了cross region。
与1x1的卷积相对应,而1x1卷积可以看作一个cross channel的pooling操作。pooling的另外一个作用就是升维或者降维,后面我们可以看到1x1的卷积也有相似的作用。

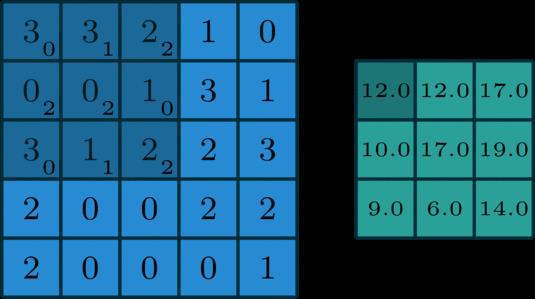
第一层有6个神经元,分别是a1—a6,通过全连接之后变成5个,分别是b1—b5,第一层的六个神经元要和后面五个实现全连接,本图中只画了a1—a6连接到b1的示意,可以看到,在全连接层b1其实是前面6个神经元的加权和,权对应的就是w1—w6,到这里就很清晰了。
第一层的6个神经元其实就相当于输入特征里面那个通道数:6,而第二层的5个神经元相当于1*1卷积之后的新的特征通道数:5。
w1—w6是一个卷积核的权系数,若要计算b2—b5,显然还需要4个同样尺寸的卷积核。
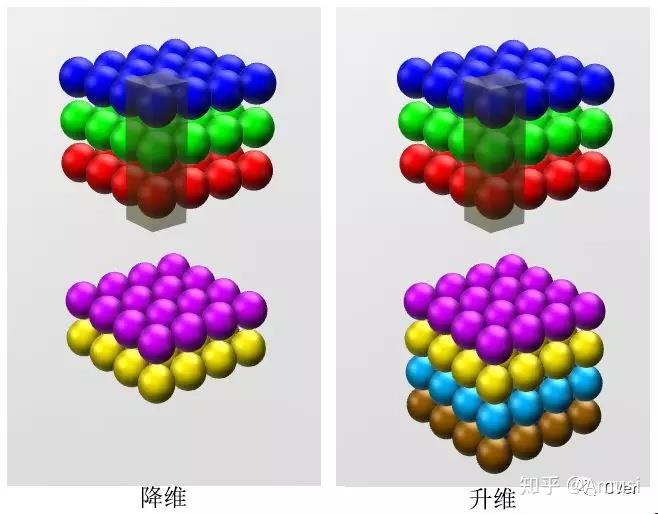
二、降维/升维
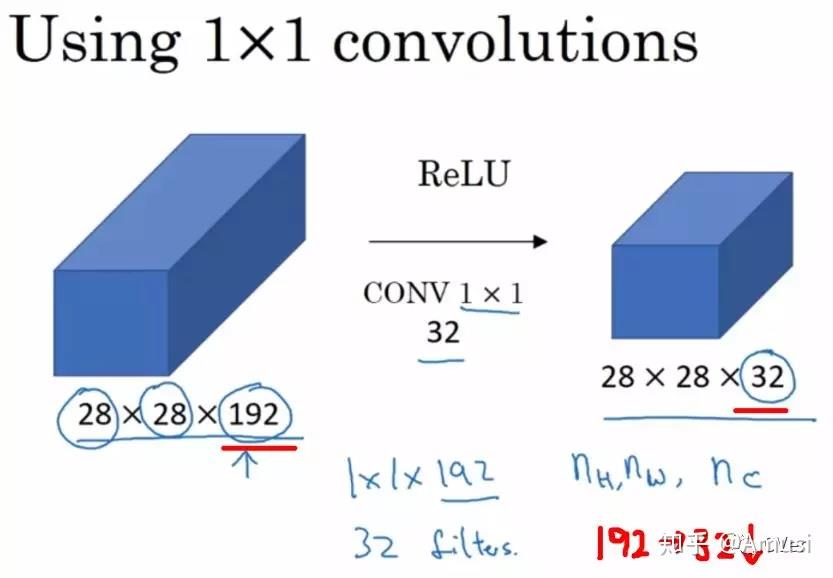
由于 1×1 并不会改变 height 和 width,改变通道的第一个最直观的结果,就是可以将原本的数据量进行增加或者减少。这里看其他文章或者博客中都称之为升维、降维。
增加非线性
1*1卷积核,可以在保持feature map尺度不变的(即不损失分辨率)的前提下大幅增加非线性特性(利用后接的非线性激活函数),把网络做的很deep。
备注:一个filter对应卷积后得到一个feature map,不同的filter(不同的weight和bias),卷积以后得到不同的feature map,提取不同的特征,得到对应的specialized neuron。
跨通道信息交互
使用1x1卷积核,实现降维和升维的操作其实就是channel间信息的线性组合变化,3x3x64channels的输入后面添加一个1x1x28channels的卷积核,就变成了3x3x28channels的输出,原来的64个channels就可以理解为跨通道线性组合变成了28channels,这就是通道间的信息交互。
注意:只是在channel维度上做线性组合,W和H上是共享权值的sliding window
三、 应用实例
ResNet
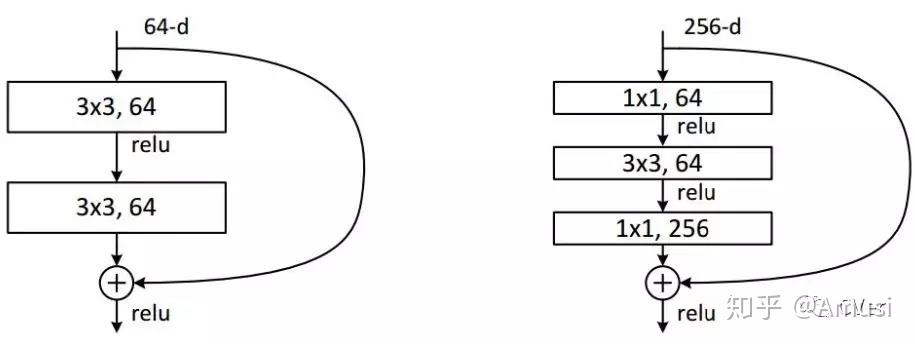
ResNet同样也利用了1×1卷积,并且是在3×3卷积层的前后都使用了,不仅进行了降维,还进行了升维,参数数量进一步减少,如上图的结构。
其中右图又称为”bottleneck design”,目的一目了然,就是为了降低参数的数目,第一个1x1的卷积把256维channel降到64维,然后在最后通过1x1卷积恢复,整体上用的参数数目:1x1x256x64 + 3x3x64x64 + 1x1x64x256 = 69632,而不使用bottleneck的话就是两个3x3x256的卷积,参数数目: 3x3x256x256x2 = 1179648,差了16.94倍。
对于常规ResNet,可以用于34层或者更少的网络中,对于Bottleneck Design的ResNet通常用于更深的如101这样的网络中,目的是减少计算和参数量(实用目的)。
四、卷积计算
我们现在知道如何处理卷积中的深度。让我们继续讨论如何处理其他两个方向(高度和宽度)的卷积,以及重要的卷积算法。
- 卷积核大小:卷积核大小决定了卷积的感受野大小。
- 步长:它定义了卷积核扫过特征图时的步长大小。步长为1表示卷积核逐个扫过特征图的像素。步长为2表示卷积核以每步移动2个像素(即跳过一个元素)扫描特征图。我们可以用步长(>=2)对特征图进行向下采样。
- 填充:它定义了如何处理特征图的边框。如果必要的话,在输入边界进行全0填充,填充卷积(Tersorflow中padding=‘same’)将保持输出和输入的特征图尺寸相同。另一方面,完全不使用填充的卷积( Tersorflow中padding=‘valid’)只对输入的像素执行卷积,而不在输入边界填充0。输出的特征图尺寸小于输入的特征图尺寸。
下图展示了一个卷积核大小为3、步长为1和填充为1的二维卷积。
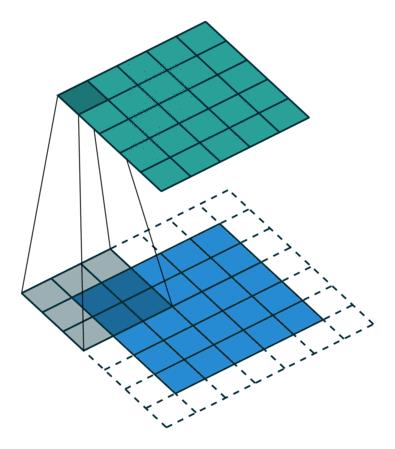
对于尺寸为i、卷积核大小为k、填充为p、步长为s的输入图像,卷积后的输出图像尺寸o:
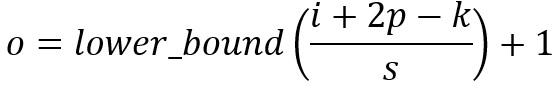
为什么卷积核都是奇数呢?
- 更容易padding:
在卷积时,我们有时候需要卷积前后的尺寸不变。这时候我们就需要用到padding。假设图像的大小,也就是被卷积对象的大小为n×n,卷积核大小为k,padding设定为 (k-1)/2时,我们由计算公式可知 o=(n-k+2((k-1)/2))/1 +1 = n ,即保证了卷积输出也为n×n。保证了卷积前后尺寸不变。
但是如果k是偶数的话,(k-1)/2就不是整数了。 - 更容易找到卷积锚点
在CNN中,进行卷积操作时一般会以卷积核模块的一个位置为基准进行滑动,这个基准通常就是卷积核模块的中心。若卷积核为奇数,卷积锚点很好找,自然就是卷积模块中心,但如果卷积核是偶数,这时候就没有办法确定了,让谁是锚点似乎都不怎么好。
以上是关于深度学习-神经网络卷积核理解的主要内容,如果未能解决你的问题,请参考以下文章
卷积填充步长;卷积神经网络的卷积核大小个数,卷积层数如何确定呢;深度学习如何调参;