树模型与集成学习(task4)两种并行集成的树模型
Posted 山顶夕景
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了树模型与集成学习(task4)两种并行集成的树模型相关的知识,希望对你有一定的参考价值。
学习总结
(1)随机森林中的随机主要来自三个方面:
- 其一为bootstrap抽样导致的训练集随机性,
- 其二为每个节点随机选取特征子集进行不纯度计算的随机性,
- 其三为当使用随机分割点选取时产生的随机性(此时的随机森林又被称为Extremely Randomized Trees)。
(2)孤立森林算法类比在切蛋糕,点密度稠密的一块需要切很多刀才能分割完,而那些很早能分割完的应该是异常点(我们要把每个点都单独存在一个子空间中)。
孤立森林通过随机选择特征,然后随机选择特征的分割值,递归地生成数据集的分区。和数据集中「正常」的点相比,要隔离的异常值所需的随机分区更少,因此异常值是树中路径更短的点,路径长度是从根节点经过的边数。
【内容概要】理解随机森林的训练和预测流程,特征重要性和oob得分计算,孤立森林的原理以及训练和预测流程
【打卡内容】侧边栏练习,知识回顾后三题,实现孤立森林算法和用于分类的随机森林算法(可以用sklearn的决策树或task2中自己实现的分类cart树)
文章目录
一、随机森林
1.1 算法介绍
随机森林是以决策树(常用CART树)为基学习器的bagging算法。
(1)随机森林当处理回归问题时,输出值为各学习器的均值;
(2)随机森林当处理分类问题时有两种策略:
- 第一种是原始论文中使用的投票策略,即每个学习器输出一个类别,返回最高预测频率的类别;
- 第二种是sklearn中采用的概率聚合策略,即通过各个学习器输出的概率分布先计算样本属于某个类别的平均概率,在对平均的概率分布取 arg max \\arg\\max argmax以输出最可能的类别。
随机森林中的随机主要来自三个方面:
- 其一为bootstrap抽样导致的训练集随机性,
- 其二为每个节点随机选取特征子集进行不纯度计算的随机性,
- 其三为当使用随机分割点选取时产生的随机性(此时的随机森林又被称为Extremely Randomized Trees)。
随机森林中特征重要性的计算方式为:利用相对信息增益来度量单棵树上的各特征特征重要性(与决策树计算方式一致),再通过对所有树产出的重要性得分进行简单平均来作为最终的特征重要性。
【练习】
r2_score和均方误差的区别是什么?它具有什么优势?
r2_score是判定系数:回归模型的方差系数。
r2_score的计算公式如下:(本质上是以均值模型作为baseline model,计算该模型相较于它的好坏) R 2 ( y , y ^ ) = 1 − ∑ i = 0 n − 1 ( y i − y i ^ ) 2 ∑ i = 0 n − 1 ( y i − y ‾ ) 2 R^2(y,\\hat{y})=1-\\frac{\\sum_{i=0}^{n-1}(y_i-\\hat{y_i})^2}{\\sum_{i=0}^{n-1}(y_i-\\overline{y})^2} R2(y,y^)=1−∑i=0n−1(yi−y)2∑i=0n−1(yi−yi^)2MSE是均方误差,即线性回归的损失函数,计算公式如下: M S E ( y , y ^ ) = 1 n ∑ i = 0 n − 1 ( y i − y ^ i ) 2 MSE(y,\\hat{y})=\\frac{1}{n}\\sum_{i=0}^{n-1}(y_i-\\hat{y}_i)^2 MSE(y,y^)=n1i=0∑n−1(yi−y^i)2其中分子是训练出的模型的所有误差,分母是使用y真=y真平均 预测产生的误差。
二者的区别是 R 2 ( y , y ^ ) = 1 − M S E ( y , y ^ ) σ 2 R^2(y,\\hat{y})=1-\\frac{MSE(y,\\hat{y})}{\\sigma^2} R2(y,y^)=1−σ2MSE(y,y^),其中 σ \\sigma σ表示y的标准差。
MSE是带量纲的,而且结果为量纲的平方,而r2_score是不带量纲的,可以比较模型在不同量纲数据(不同问题)上的好坏。
【oob样本】:在训练时,一般而言我们总是需要对数据集进行训练集和验证集的划分,但随机森林由于每一个基学习器使用了重复抽样得到的数据集进行训练,因此总存在比例大约为 e − 1 e^{-1} e−1的数据集没有参与训练,这一部分数据称为out-of-bag样本(即oob样本)。
对每一个基学习器训练完毕后,我们都对oob样本进行预测,每个样本对应的oob_prediction_值为所有没有采样到该样本进行训练的基学习器预测结果均值,这一部分的逻辑参见此处的源码实现。
在得到所有样本的oob_prediction_后:
(1)对于回归问题,使用r2_score来计算对应的oob_score_;
(2)而对于分类问题,直接使用accuracy_score来计算oob_score_。
1.2 Totally Random Trees Embedding
介绍一种Totally Random Trees Embedding方法,它能够基于每个样本在各个决策树上的叶节点位置,得到一种基于森林的样本特征嵌入。
【栗子】假设现在有4棵树且每棵树有4个叶子节点(共16个节点),依次对它们进行从0至15的编号,记样本 i i i在4棵树叶子节点的位置编号为 [ 0 , 7 , 8 , 14 ] [0,7,8,14] [0,7,8,14],样本 j j j的编号为 [ 1 , 7 , 9 , 13 ] [1,7,9,13] [1,7,9,13],此时这两个样本的嵌入向量即为 [ 1 , 0 , 0 , 0 , 0 , 0 , 0 , 1 , 1 , 0 , 0 , 0 , 0 , 0 , 1 , 0 ] [1,0,0,0,0,0,0,1,1,0,0,0,0,0,1,0] [1,0,0,0,0,0,0,1,1,0,0,0,0,0,1,0]和 [ 0 , 1 , 0 , 0 , 0 , 0 , 0 , 1 , 0 , 1 , 0 , 0 , 0 , 1 , 0 , 0 ] [0,1,0,0,0,0,0,1,0,1,0,0,0,1,0,0] [0,1,0,0,0,0,0,1,0,1,0,0,0,1,0,0]
假设样本 k k k对应的编号为 [ 0 , 6 , 8 , 14 ] [0,6,8,14] [0,6,8,14],那么其对应嵌入向量的距离应当和样本 i i i 较近,而离样本 j j j 较远,即两个样本在不同树上分配到相同的叶子结点次数越多,则越接近。因此,这个方法巧妙地利用树结构获得了样本的隐式特征。
【练习】假设使用闵氏距离来度量两个嵌入向量之间的距离,此时对叶子节点的编号顺序会对距离的度量结果有影响吗?
没有关系。
闵式距离为: D ( x , y ) = ( ∑ u = 1 n ∣ x u − y u ∣ p ) 1 p D(x,y)=(\\sum_{u=1}^n|x_u-y_u|^p)^{\\frac{1}{p}} D(x,y)=(u=1∑n∣xu−yu∣p)p1 嵌入向量是依据决策森林样本叶节点落位而进行multi_hot encoding的一个结果(对应位取值为1,其他为0),只要叶子节点编号的每个维度的权重一样(这里都是1)。
二、孤立森林
孤立森林算法是基于 Ensemble 的异常检测方法,因此具有线性的时间复杂度。且精准度较高,在处理大数据时速度快,所以目前在工业界的应用范围比较广。常见的场景包括:网络安全中的攻击检测、金融交易欺诈检测、疾病侦测、噪声数据过滤(数据清洗)等。
孤立森林是基于决策树的算法。从给定的特征集合中随机选择特征,然后在特征的最大值和最小值间随机选择一个分割值,来隔离离群值。这种特征的随机划分会使异常数据点在树中生成的路径更短,从而将它们和其他数据分开。孤立森林不通过显式地隔离异常,来隔离了数据集中的异常点。
孤立森林的基本思想是:多次随机选取特征和对应的分割点以分开空间中样本点,那么异常点很容易在较早的几次分割中就已经与其他样本隔开,正常点由于较为紧密故需要更多的分割次数才能将其分开。
孤立森林的优势:
- Partial models:在训练过程中,每棵孤立树都是随机选取部分样本;
- No distance or density measures:不同于 KMeans、DBSCAN 等算法,孤立森林不需要计算有关距离、密度的指标,可大幅度提升速度,减小系统开销;
- Linear time complexity:因为基于 ensemble,所以有线性时间复杂度。通常树的数量越多,算法越稳定;
- Handle extremely large data size:由于每棵树都是独立生成的,因此可部署在大规模分布式系统上来加速运算。
2.1 异常得分的计算
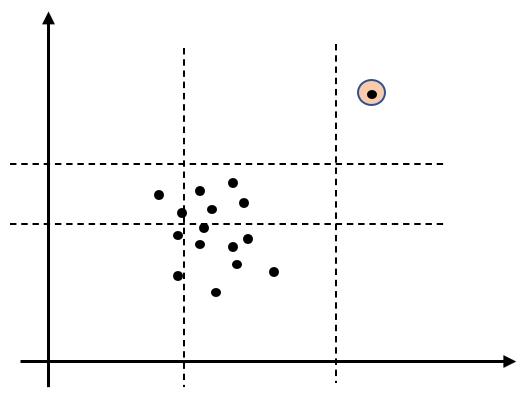
下图中体现了两个特征下的4次分割过程,可见右上角的异常点已经被单独隔离开。
对于 n n n 个样本而言,我们可以构建一棵在每个分支进行特征大小判断的树来将样本分派到对应的叶子节点,为了定量刻画异常情况,在这篇文献中证明了树中的平均路径(即树的根节点到叶子结点经过的节点数)长度 c c c为
c ( n ) = 2 H ( n − 1 ) − 2 ( n − 1 ) n c(n) = 2H(n-1)-\\frac{2(n-1)}{n} c(n)=2H(n−1)−n2(n−1)
其中 H ( k ) H(k) H(k)为调和级数 ∑ p = 1 k 1 p \\sum_{p=1}^k\\frac{1}{p} p=1∑kp1
此时对于某个样本 x x x,假设其分派到叶子节点的路径长度为 h ( x ) h(x) h(x),我们就能用 h ( x ) c ( n ) \\frac{h(x)}{c(n)} c(n)h(x)的大小来度量异常的程度,该值越小则越有可能为异常点。由于单棵树上使用的是随机特征的随机分割点,稳健度较差,因此孤立森林将建立 t t t棵树(默认100),每棵树上都在数据集上抽样出 ψ \\psi