DataWhale组队学习吃瓜教程(西瓜书+南瓜书)Task03-香农信息量与信息熵
Posted 哒卜琉歪歪
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DataWhale组队学习吃瓜教程(西瓜书+南瓜书)Task03-香农信息量与信息熵相关的知识,希望对你有一定的参考价值。
本次任务是周志华老师《机器学习》第四章决策的内容,该部分在本科也有过简单接触,研一机器学习课上也进行了系统的学习,下面对决策树所涉及的基础知识——香农信息量与信息熵进行整理。
香农信息量
假设p是连续型随机变量X的概率分布,p(x)为随机变量X在X=x处的概率密度函数值(若X为离散型,则p(x)为某一具体随机事件的概率),则随机变量X 在X=x处的香农信息量定义为:
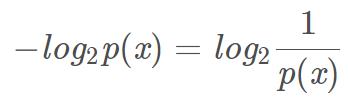
单位为比特(向上取整) 。
香农信息量用于刻画消除随机变量在处的不确定性所需的信息量的大小,即已知某事件发生的概率,(无论外部其他事件如何变化)至少需要多少比特才能完整描绘该事件。此处进行一点思考:为什么该式可以计算出信息量的大小?
这里用香农信息量在数据压缩应用的一般流程的例子进行解释说明,即对数据aaBaaaVaaaaa进行编码时,a,B,V分别至少需要1,4,4个比特。对该例可以进行更深一步的理解:本例为非均匀分布,分均匀分布比均匀分布的熵小,使用更短的编码来描述更可能的事情,使用更长的编码描述不太可能的事情。即熵是传输一个随机变量状态值所需的比特位下界(最短编码长度)。
香农信息量该式中的底数为2通过该例可以理解为比特的两种可能性,而因为二分是一个除的关系,因此自变量是概率分之一而不是概率本身;还可以从另一个角度进行理解:在数学上,所传输的消息是其出现概率的单调递减函数。例如从64个数字中选定某一个数,以“是否大于32”的问题选择,不论答案如何都消去了半数的可能事件,如此下去,只要问6次这类问题就可以从64个数字中选定这个数,则我们可以用2进制的6个位来记录该过程。
此外,该式中自变量为概率的倒数,使得某事件发生概率越小,信息量越大;且符合当两件事同时发生时,信息量相加,概率相乘。
信息熵
信息熵是香农信息量的数学期望,即所有X=x处的香农信息量的和,由于每一个x的出现概率不一样(用概率密度函数值p(x)衡量),需要用p(x)加权求和。信息熵是刻画消除随机变量X的不确定性所需要的总体信息量的大小。
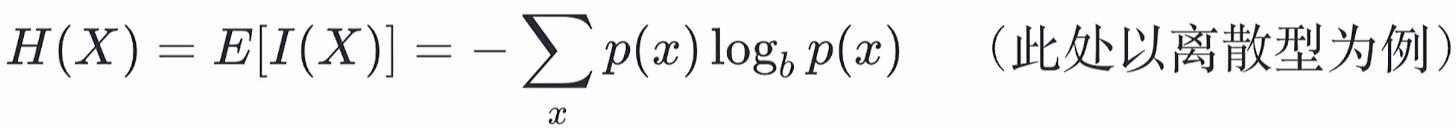
熵只依赖于r.v.的分布,而与r.v.取值无关,故也可以将X的熵记为H(p),即事件发生概率的函数。
信息熵具有三个性质:1.单调性:事件发生概率越大,携带的信息量越小;
2.非负性:信息熵可视为一种广度量;
3.累加性:多个随机事件同时发生存在的总不确定性的量度可表示为各事件不确定性的量度的和(也是广度量的体现)。
注意信息熵的公式是能够满足上述三个条件的随机变量不确定性度量函数的唯一形式。
对于两个相互独立的事件X=A,Y=B,其同时发生P(X=A,Y=B)=P(X=A)P(Y=B),其同时发生的信息熵H(P(X=A,Y=B))=H(P(X=A)P(Y=B))=H(P(X=A))+H(P(Y=B)),满足两变量乘积函数=两变量函数值的和的函数形式为对数函数。再考虑非负性,前加负号。
sum(各种可能表示出的信息量×发生的概率)表示整个系统所有信息量的期望值。
以上是关于DataWhale组队学习吃瓜教程(西瓜书+南瓜书)Task03-香农信息量与信息熵的主要内容,如果未能解决你的问题,请参考以下文章