快速掌握 深度学习(Deep Learning) 常用概念术语,常用模型
Posted 小哈里
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了快速掌握 深度学习(Deep Learning) 常用概念术语,常用模型相关的知识,希望对你有一定的参考价值。
1、什么是深度学习?
深度学习的概念:
- 深度学习是机器学习的一个分支,深度学习是使用了深度神经网络的机器学习 。
所以深度学习=深度神经网络+机器学习。 - 神经网络,也叫作人工神经网络 。是一种模拟人脑的神经网络以期能够实现类人工智能的机器学习技术。
深度神经网络通常指的是使用了两层或两层以上隐藏层 的神经网络。 - 以人脸识别为例 ,输入的数据是图片像素的RGB值,经过一层抽象以后,可以获得一些局部的边缘特征,经过两层抽象后,可以获得眼睛鼻子嘴巴等有意义的区域特征,经过三层抽象后,可以获取和人脸有关的整体特征,通过不断抽象获取更高层的概念,从而实现更准确的人脸识别等 计算机视觉任务 。
神经元模型:
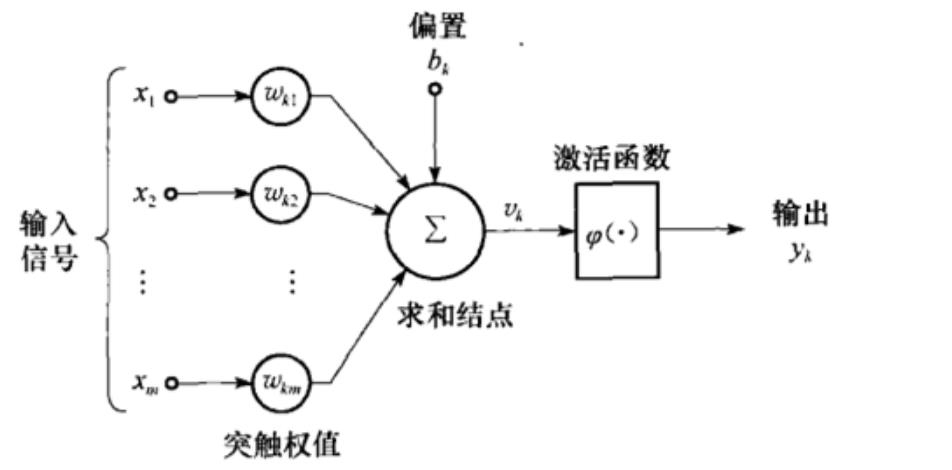
- 神经元模型是一个包含 输入,输出与计算 功能的模型。输入可以类比为神经元的树突,而输出可以类比为神经元的轴突,计算则可以类比为细胞核。
比如:人脑的一个神经元通常具有多个树突 ,主要用来接受传入信息 ;而轴突只有一条 ,轴突尾端有许多轴突末梢可以给其他多个神经元传递信息。 - 神经元的效果:我们有一个数据,称之为样本。样本有四个属性,其中三个属性已知,一个属性未知。我们需要做的就是通过三个已知属性预测未知属性 。
具体办法就是使用神经元的公式进行计算,已知三个特征,假设特征与目标之间确实是线性关系 ,并且我们已经得到表示这个关系的权值w1,w2,w3,那么,我们就可以通过神经元模型 预测新样本的目标 。 - 神经元实现:包含 输入信号、加权求和、加偏置、激活函数、输出5个部分 。输入x是一个m维向量,权重w也是一个m维向量,偏置b为一个数值,输出y是一个值。
下图是一个神经元模型:包含有m个输入,1个输出,以及3个计算功能。
神经网络/全连接层 的建立:
- 一个全连接层包括输入层、隐藏层、输出层 3个部分。
其中,输入层与输出层的节点数往往是固定的,中间层则可以自由指定节点数乃至层数。 - 结构图里的关键不是圆圈(代表“神经元”),而是连接线(代表“神经元”之间的连接)。每个连接线对应一个不同的权重 (其值称为权值),这是需要训练得到的。
- 如何训练得到权重?
- 首先,我们为全连接层定义一个损失函数loss 表示预测目标与真实目标的误差,比如loss = (yp-y)^2,那么模型的训练便是通过调整每一层的权重和偏置,使得损失函数最小。
- 然后,这个问题就被转化为一个优化问题 ,一个常用方法就是高等数学中的求导,但是这里的问题由于参数不止一个,求导后计算导数等于0的运算量很大,所以一般来说解决这个优化问题使用的是梯度下降算法 。
- 梯度下降算法 每次计算参数在当前的梯度,然后让参数向着梯度的反方向前进一段距离,不断重复,直到梯度接近零时截止。一般这个时候,所有的参数恰好达到使损失函数达到一个最低值的状态。
- 由于结构复杂,每次计算梯度的代价很大。因此还需要使用反向传播(BP)算法 ,反向传播算法的启示是数学中的链式法则 。反向传播算法是利用了神经网络的结构进行的计算。不一次计算所有参数的梯度,而是从后往前。首先计算输出层的梯度,然后是第二个参数矩阵的梯度,接着是中间层的梯度,再然后是第一个参数矩阵的梯度,最后是输入层的梯度。计算结束以后,所要的两个参数矩阵的梯度就都有了。
- 在实际应用中,大部分会使用随机梯度下降法(SGD)或批量梯度下降法(BGD) 代替梯度下降法进行训练,因为梯度下降法中的损失函数时根据全部记录数据计算的 ,迭代一次需要耗费更多的时间和运算,在全局数据上计算梯度也有可能导致收敛缓慢等问题,而SGD每轮迭代中随机在所有数据中选择一些记录,BGD则将全部数据分批并且每次只选出一部分 ,这样计算损失函数,计算量更小,迭代速度更快,并且每次迭代的记录集合各不相同,令计算出来的梯度更加灵活多样,容易找到梯度真正下降的方向。

2、深度学习常用模型?
1、用于处理图像的CNN
-
卷积神经网络CNN(Convolutional Neural Network),受到人类视觉神经系统的启发 。将大数据量的图片降维成小数据量,并且能够有效的保留图片特征,广泛的应用于人脸识别、自动驾驶、安防等计算机视觉领域CV 。
-
图像处理的两大难点:
1)图像的数据量太大,图像是由像素构成的,每个像素又是由颜色构成的,随便一张图片都有1000*1000像素*3颜色,整整3百万个参数 ,还有海量的图片数据。
2)图片数字化的传统方式就是有元素的位置保留1没有的保留0,那么图形的位置不同就会产生完全不同的数据表达,但是从视觉的角度来看,图像的内容本质并没有发生变化,所以当我们移动图像中的物体,用传统的方式的得出来的参数会差异很大。当图像做翻转,旋转或者变换位置时, 我们也需要识别出来是类似的图像。 -
人类的视觉原理:
人类视觉对物体是通过逐层分级认知 的。在最底层特征基本上是类似的,就是各种边缘 ,越往上,越能提取出此类物体的一些特征 (轮子、眼睛、躯干等),到最上层,不同的高级特征最终组合成相应的图像 ,从而能够让人类准确的区分不同的物体。
例子:从原始信号摄入开始(瞳孔摄入像素 Pixels),接着做初步处理(大脑皮层某些细胞发现边缘和方向),然后抽象(大脑判定,眼前的物体的形状,是圆形的),然后进一步抽象(大脑进一步判定该物体是只气球)。 -
CNN 的基本原理:
- 典型的 CNN 由3个部分构成:卷积层、池化层、全连接层
卷积层负责提取图像中的局部特征 ;池化层用来大幅降低参数量级(降维),防止过拟合 ;全连接层类似传统神经网络的部分,用来输出想要的结果 。 - 卷积层的通过卷积核的过滤提取出图片中局部的特征 。
即使做完了卷积,图像仍然很大,所以为了降低数据维度,池化层就进行采样 ,比如原始图片是20×20的,经过采样后就成为了一个2×2大小的特征图。
经过卷积层和池化层降维过的数据输入到全连接层,此时全连接层才能跑得动 。
- 典型的 CNN 由3个部分构成:卷积层、池化层、全连接层
-
CNN通用步骤:
原始数据:二维
卷积、子采样、卷积、子采样……
接上全连接层
接上分类层,输出 -
CNN的核心:
CNN的核心是卷积层。卷积是指将一些数线性加权,卷起来。卷积的本质,是进行滑动的融合(一维沿着一个方向滑动,二维沿着两个方向滑动)

2、用于处理序列的RNN
- 循环神经网络RNN(Recurrent Neural Network),受到人类短期记忆和表征学习启发 。通过添加一个循环解决了传统的神经网络无法从先前的信息中进行推理的困难 。被广泛的应用于文本生成、语音识别、机器翻译、生成图像描述、视频标记等自然语言处理领域NLP 。
- 序列处理的两大难点 :
对于长度可变的序列数据 ,全连接层因为只能接受固定维度大小的输入,所以无法处理。
同时全连接层中仅考虑了不同层神经元之间的连接,同一层的则无法连接,而一串序列中的数据流却是相互依赖的 。
比如小学生都会的单词填空:最好的摸鱼网站是__________。为了填好左边的空,取前面任何一个词都不合适,可是我们不但需要知道前面所有的词,还需要知道词之间的顺序。 - 人类的记忆原理:
生物拥有短期记忆的原因是因为,大脑皮层的解剖结构允许刺激在神经回路中循环传递 ,反响回路的兴奋和抑制受大脑阿尔法节律调控,并在α-运动神经中形成循环反馈系统 。 - RNN的基本原理:
- RNN 跟传统神经网络最大的区别在于每次都会将前一次的输出结果,带到下一次的隐藏层中,一起训练 。
- 比如你说了一句“what time is it?”我们需要先对这句话进行分词。
然后按照顺序输入 RNN ,我们先将 “what”作为 RNN 的输入,得到输出「01」
然后,我们按照顺序,将“time”输入到 RNN 网络,得到输出「02」
此时,输入 “time” 的时候,前面 “what” 的输出也产生了影响。
以此类推,前面所有的输入都对未来的输出产生了影响,最后的圆形隐藏层中包含了前面所有的数据运算。
- RNN的局限性:
RNN受到短期的记忆影响较大,但是长期的记忆影响就很小,所以无法处理很长的输入序列 。
同时因为需要全部记住,所以训练 RNN 需要投入极大的成本 。 - RNN通用步骤:
整理输入数据,每句文本处理成固定长度,做词嵌入Embedding
将一句话的每个词逐一输入到RNN中,得到每一步的输出
最后一步的输出可以视为整句话的一个融合
接上分类器,输出

3、长序列处理,RNN的优化——LSTM
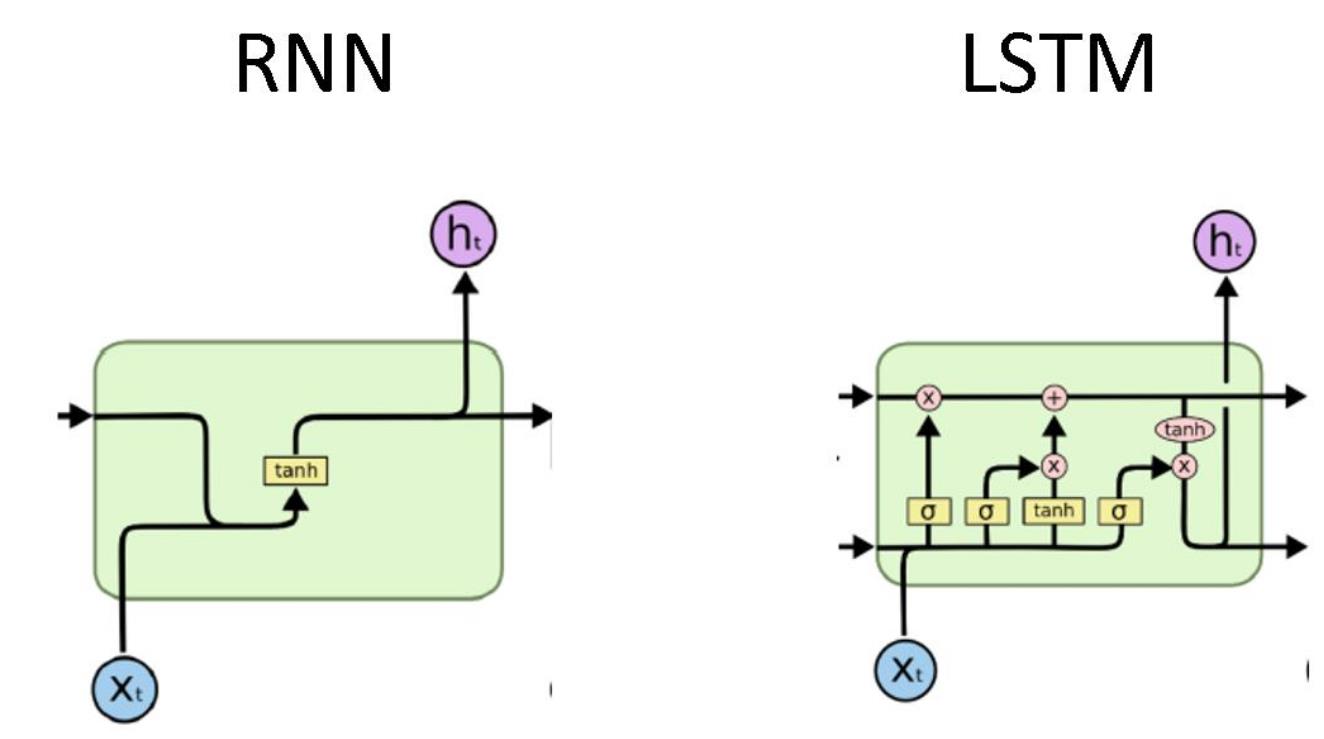
- 长短期记忆网络 LSTM(Long short-term memory),是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题 。相比普通的RNN,LSTM能够在更长的序列中有更好的表现。
- LSTM的原理:
- LSTM 相比RNN 做的最大的改变就是——只保留重要的信息。
LSTM是通过门控状态来控制传输状态,记住需要长时间记忆的,忘记不重要的信息;而不像普通的RNN那样只能够“呆萌”地仅有一种记忆叠加方式。 - LSTM内部主要有三个阶段:
1)忘记阶段 。这个阶段主要是对上一个节点传进来的输入进行选择性忘记。简单来说就是会 “忘记不重要的,记住重要的”。
2)选择记忆阶段 。这个阶段将这个阶段的输入有选择性地进行“记忆”。主要是会对输入进行选择记忆。哪些重要则着重记录下来,哪些不重要,则少记一些。
3) 输出阶段。这个阶段将决定哪些将会被当成当前状态的输出。
- LSTM 相比RNN 做的最大的改变就是——只保留重要的信息。
- LSTM的应用场景:
因为引入了很多内容,导致参数变多,也使得训练难度加大了很多。因此很多时候我们往往会使用效果和LSTM相当但参数更少的GRU来构建大训练量的模型。
以上是关于快速掌握 深度学习(Deep Learning) 常用概念术语,常用模型的主要内容,如果未能解决你的问题,请参考以下文章
Deep Learning(深度学习)之Deep Learning学习资源
Spark MLlib Deep Learning Deep Belief Network (深度学习-深度信念网络)2.3
机器学习(Machine Learning)&深度学习(Deep Learning)资料
Deep Learning(深度学习)之Deep Learning的基本思想