keras库的安装及使用,以全连接层和手写数字识别MNIST为例
Posted 小哈里
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了keras库的安装及使用,以全连接层和手写数字识别MNIST为例相关的知识,希望对你有一定的参考价值。
1、什么是keras
什么是keras?
- keras以TensorFlow和Theano作为后端封装,是一个专门用于深度学习的python模块。
- 包含了全连接层,卷积层,池化层,循环层,嵌入层等等等,常见的深度学习模型。
包含用于定义损失函数的Losses,用于训练模型的Optimizers,评估模型的Metrics,定义激活函数的Activations,防止过拟合的Regularizers等功能 - keras不需要了解太多理论知识,可以直接使用模型,新手入门十分友好。
如何安装keras?
- 你可以直接使用pip安装它
pip install keras -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
-
也可以通过Anaconda安装它
https://gwj1314.blog.csdn.net/article/details/120818390 -
也可以使用conda安装它
conda install keras
- 也可以再Github上找到它
https://github.com/keras-team/keras
2、MNIST数据集
全连接层 mnist_mlp.py
详细数据请见:http://yann.lecun.com/exdb/mnist/
https://en.wikipedia.org/wiki/MNIST_database
数据包含:
训练集图像train-images-idx3-ubyte.gz和标签train-labels-idx1-ubyte.gz
测试集图像t10k-images-idx3-ubyte.gz和标签t10k-labels-idx1-ubyte.gz
训练目标:
基于手写数字图片预测数值。
# 加载包
import numpy as np
from keras.utils import np_utils
import keras
from keras.datasets import mnist # mnist数据集
from keras.models import Sequential #核心模型结构
from keras.layers.core import Dense, Dropout, Activation #Dense即全连接层,Dropout为防止过拟合的采样层,Activation为激活函数
# from keras.optimizers import RMSprop # 导入优化器
# from keras import optimizers
# from tensorflow.python.keras.api._v2.keras.optimizers import SGD, Adam, RMSprop
# 1、加载数据
batch_size = 128 # BGD对训练集分批时,每批数据的记录数量128条
nb_classes = 10 # 标签的类别数量,0-9共10类
nb_epoch = 20 # 训练轮数,每次选择一批记录训练,共重复10轮
# 使用keras加载已经准备好的mnist数据
(X_train, y_train), (X_test, y_test) = mnist.load_data() # 将数据集分为训练集和测试集的特征和标签
X_train = X_train.reshape(60000, 784) # 用reshape将返回的numpy array类型转数组
X_test = X_test.reshape(10000, 784) # 将三维的10000*28*28特征降为二维的10000*784
X_train = X_train.astype('float32') # 将0-255的像素点整数变位浮点数
X_test = X_test.astype('float32')
X_train /= 255 # 将像素点归化到0~1
X_test /= 255
print(X_train.shape[0], 'train samples')
print(X_test.shape[0], 'test samples')
Y_train = np_utils.to_categorical(y_train, nb_classes) # 由于原始标签是数字,所以需要对应到类别编码的对应向量
Y_test = np_utils.to_categorical(y_test, nb_classes) # 如2对应到[0,0,1,0,0,0,0,0,0,0]
# 2、定义模型
model = Sequential() # 使用Sequential()函数定义一个串联结构的模型, 使用add()函数向模型中添加网络层
model.add(Dense(512, Activation('relu'), input_shape=(784,))) # 全连接层(512个神经元,激活函数为relu, 接受大小为784的输入层)
model.add(Dropout(0.2)) # Dropout层,防止过拟合,上一层的输出有0.2的概念被忽略
model.add(Dense(512)) # 再添加一个全连接层(512个神经元)
model.add(Activation('relu'))
model.add(Dropout(0.2)) # 再一个Dropout层
model.add(Dense(10)) # 最后一个输出层
model.add(Activation('softmax')) # 使用softmax作为激活函数,对10个神经元输出进行归一化
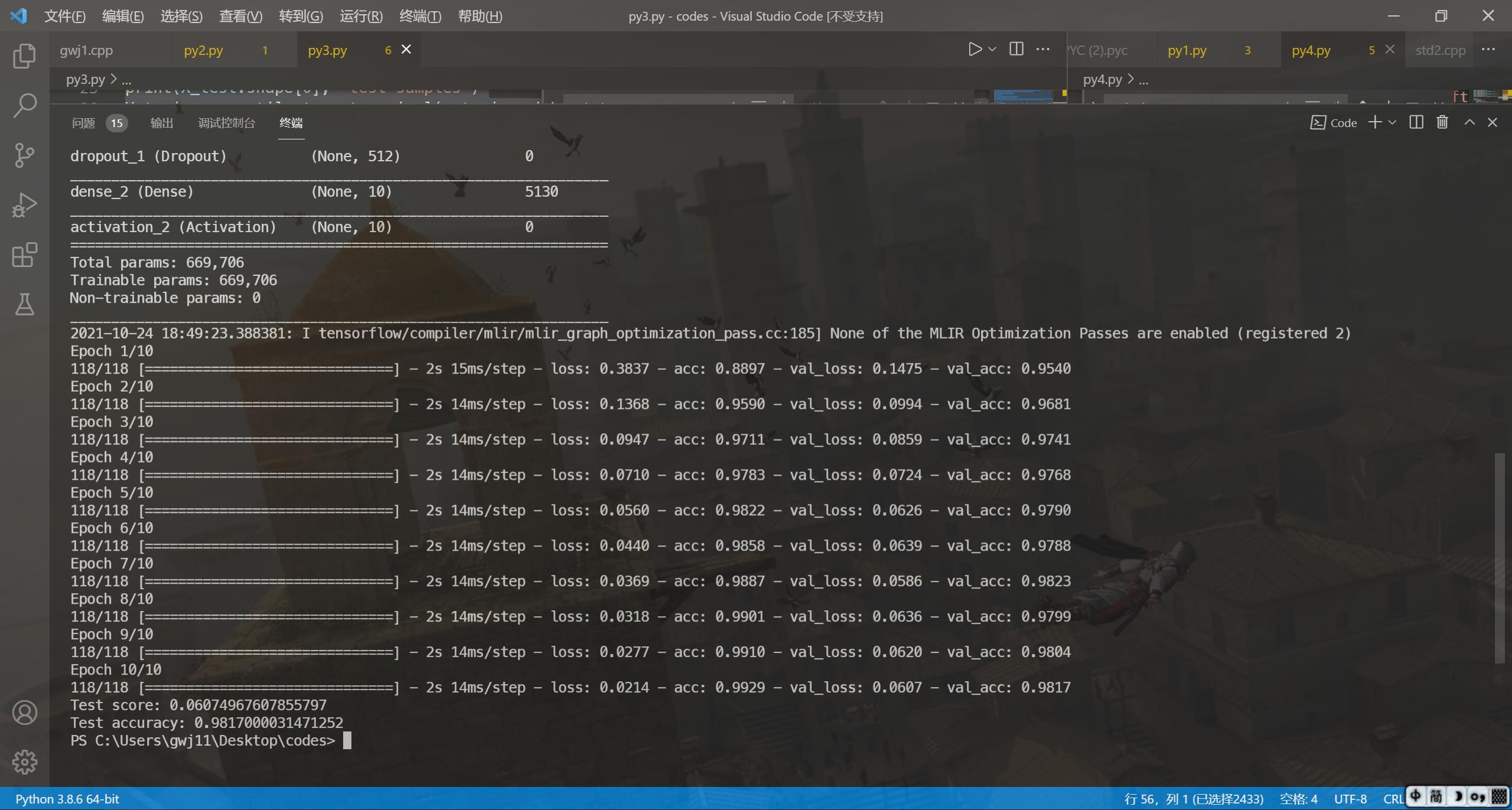
model.summary() # 查看模型总结(每一层的网络类型,输出形状,参数数量,以及模型总共的参数数量)
# 3、训练模型
model.compile(loss='sparse_categorical_crossentropy', # compile()函数编译模型,指定所需的损失函数,优化算法,评估指标
#optimizer=keras.optimizers.RMSprop(), # 这里设置为多分类交叉熵,RMSprop算法,正确率
optimizer='adam',
metrics=['acc'])
history = model.fit(x=X_train, y=y_train, # fix()函数在指定训练集上训练模型,需要指定参数batch_size和verbose
batch_size=512,
epochs=10,
#verbose=1, # verbose指定训练过程中打印信息的方式
validation_data=(X_test, y_test)) # 使用测试集作为校验数据,实时根据校验数据优化训练的方向
# 4、预测数据
score = model.evaluate(X_test, y_test, verbose=0) # 使用evaluate()函数在测试机上评估模型的性能
print('Test score:', score[0])
print('Test accuracy:', score[1])
每一轮训练结束后,都会打印出当前的模型在训练集和测试集上的损失函数和正确率。
随着训练轮数的增加,损失函数逐渐减小,正确率逐渐提高,说明模型得到了优化。
最后得到了98.1%左右准确率的模型。
以上是关于keras库的安装及使用,以全连接层和手写数字识别MNIST为例的主要内容,如果未能解决你的问题,请参考以下文章