练手练到阅文集团作家中心了,python crawlspider 二维抓取学习
Posted 梦想橡皮擦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了练手练到阅文集团作家中心了,python crawlspider 二维抓取学习相关的知识,希望对你有一定的参考价值。
本篇博客学习使用 CrawlSpider 进行二维抓取。
目标站点分析
本次要采集的目标站点为:阅文集团作家中心
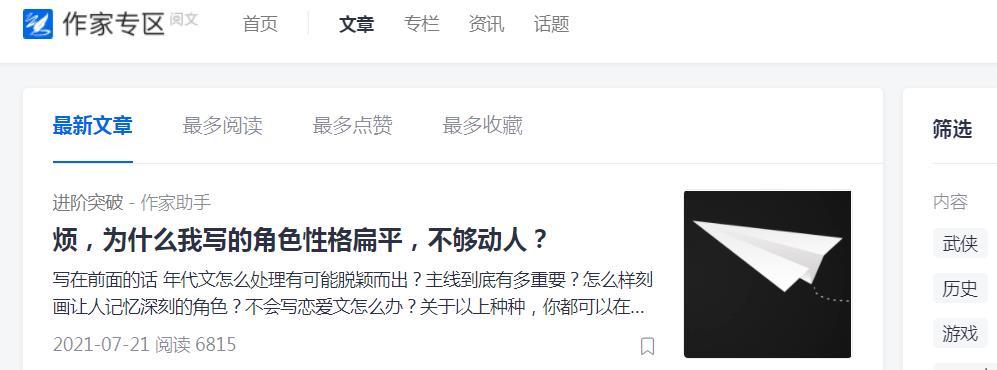
分页地址具备一定规则,具体如下:
https://write.qq.com/portal/article?filterType=0&page={页码}
由于本文重点学习内容为简单操作 scrapy 实现爬虫,所以目标详情页仅提取标题即可。
知识说明
本篇博客生成爬虫文件,使用 scrapy genspider -t crawl yw write.qq.com,默认生成的代码如下所示:
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class CbSpider(CrawlSpider):
name = 'yw'
allowed_domains = ['write.qq.com']
start_urls = ['https://write.qq.com/portal/article?filterType=0&page=1']
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
item = {}
#item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()
#item['name'] = response.xpath('//div[@id="name"]').get()
#item['description'] = response.xpath('//div[@id="description"]').get()
return item
其中 CrawlSpider 继承自 Spider ,派生该类的原因是为了简化爬取编码,其中增加了类属性 rules ,其值为Rule 对象的集合元组,用于匹配目标网站并排除干扰。
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
** Rule 类的构造函数原型如下**
Rule(link_extractor, callback=None, cb_kwargs=None, follow=None, process_links=None, process_request=None)
参数说明如下:
link_extractor:LinkExtractor 对象,定义了如何从爬取到的页面提取链接;callback:回调函数,也可以是回调函数的字符串名。接收 Response 对象作为参数,返回包含 Item 或者 Request 对象列表;cb_kwargs:用于作为**kwargs参数,传递给callback;follow:布尔值,默认是 False,用于判断是否继续从该页面提取链接;process_links:指定该spider中哪个函数将会被调用,从link_extractor中获取到链接列表后悔调用该函数,该方法主要用来过滤 url;process_request:回调函数,也可以是回调函数的字符串名。用来过滤 Request ,该规则提取到每个 Request 时都会调用该函数。
** LinkExtractor 类构造函数原型如下**
LinkExtractor(allow=(), deny=(), allow_domains=(), deny_domains=(), restrict_xpaths=(), tags=('a', 'area'),
attrs=('href',), canonicalize=False, unique=True, process_value=None, deny_extensions=None,
restrict_css=(), strip=True, restrict_text=None,
)
其中比较重要的参数如下所示:
allow:正则表达式,满足的会被提取,默认为空,表示提取全部超链接;deny:正则表达式,不被提取的内容;allow_domains:允许的 domains;deny_domains:不允许的 domains;restrict_xpaths:xpath 表达式tags:提取的标签;attrs:默认属性值;restrict_css:css 表达式提取;restrict_text:文本提取。
编码时间
在 rules 变量中,设置两个 URL 提取规则。
# URL 提取规则
rules = (
Rule(LinkExtractor(allow=r'.*/portal/content\\?caid=\\d+&feedType=2&lcid=\\d+$'), callback="parse_item"),
# 寻找下一页 url 地址
Rule(LinkExtractor(restrict_xpaths="//a[@title='下一页']"), follow=True),
)
代码重点在寻找下一页部分,使用的是 restrict_xpaths 方法,即基于 xpath 提取,原因是由于使用正则表达式提取下一页地址,写起来略微繁琐。
第一个 Rule 规则是获取内容详情页数据,回调函数 callback 是 parse_item。
完整代码如下所示:
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class CbSpider(CrawlSpider):
name = 'yw'
allowed_domains = ['write.qq.com']
start_urls = ['https://write.qq.com/portal/article?filterType=0&page=1']
# URL 提取规则
rules = (
Rule(LinkExtractor(allow=r'.*/portal/content\\?caid=\\d+&feedType=2&lcid=\\d+$'), callback="parse_item"),
# 寻找下一页 url 地址
Rule(LinkExtractor(restrict_xpaths="//a[@title='下一页']"), follow=True),
)
def parse_item(self, response):
print("测试输出")
print(response.url)
title = response.css('title::text').extract()[0]
print(title)
item = {}
# item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()
# item['name'] = response.xpath('//div[@id="name"]').get()
# item['description'] = response.xpath('//div[@id="description"]').get()
return item
编写完毕,在 settings.py 文件中修改如下内容:
ROBOTSTXT_OBEY = False # 关闭 robots.txt 文件请求
LOG_LEVEL = 'WARNING' # 调高日志输出级别
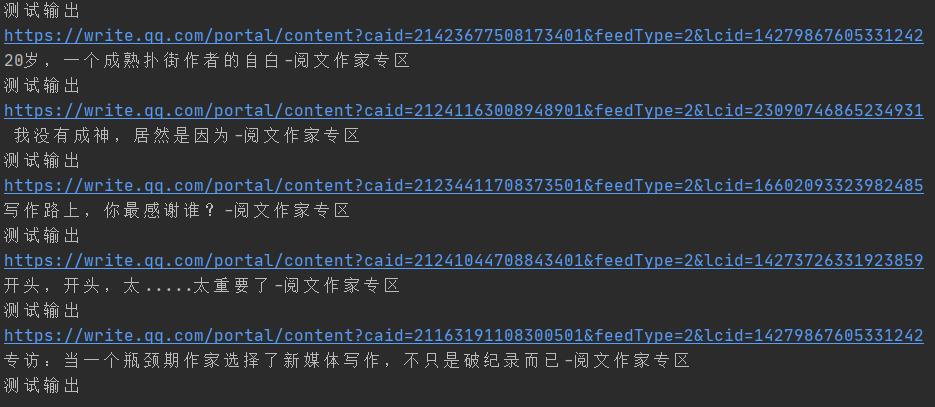
最后得到的结果如下所示。
知识再次补充
在 CrawlSpider 的派生类中,你还可以重写如下方法:
parse_start_url():在采集前对start_urls进行覆盖修改;process_results():数据返回时进行再次加工,该函数需要配合callback参数设定的函数使用。
def parse_start_url(self, response):
print("---process_results---")
yield scrapy.Request('https://write.qq.com/portal/article?filterType=0&page=1')
def process_results(self, response, results):
print("---process_results---")
print(results)
def parse_item(self, response):
print("---parse_item---")
print(response.url)
title = response.css('title::text').extract()[0].strip()
item = {}
item["title"] = title
yield item
写在后面
今天是持续写作的第 248 / 365 天。
期待 关注,点赞、评论、收藏。
更多精彩

以上是关于练手练到阅文集团作家中心了,python crawlspider 二维抓取学习的主要内容,如果未能解决你的问题,请参考以下文章