epoll 或者 kqueue 的原理是什么?
Posted 菠萝科技
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了epoll 或者 kqueue 的原理是什么?相关的知识,希望对你有一定的参考价值。
作者:张彦飞
链接:https://www.zhihu.com/question/20122137/answer/2134896876
刚回答完一个 epoll,又刷到一个,那我就再来回答一遍吧。
仔细看了一下问题,题主的主要困惑是就是没有看过内核源码,不清楚 epoll 内部究竟是咋工作的。其实我之前和题主一样,也是这个困惑。由于实在是好奇心太强,所以我就抽空撸起袖子,把 epoll 的源码给扒了一遍。
我把我分析 epoll 的过程都放在我的这本电子书里了,《理解了实现再谈网络性能》。需要的同学戳这里下载,传送门:《理解了实现再谈网络性能》

在介绍 epoll 的实现之前。我想先聊聊传统的同步阻塞 IO。
深入理解高性能网络开发路上的绊脚石 - 同步阻塞网络 IO - 知乎
这种网络 IO 模型在对网络性能要求不高的地方现在用的也还是挺多的,我把这个整体流程画了一个图。
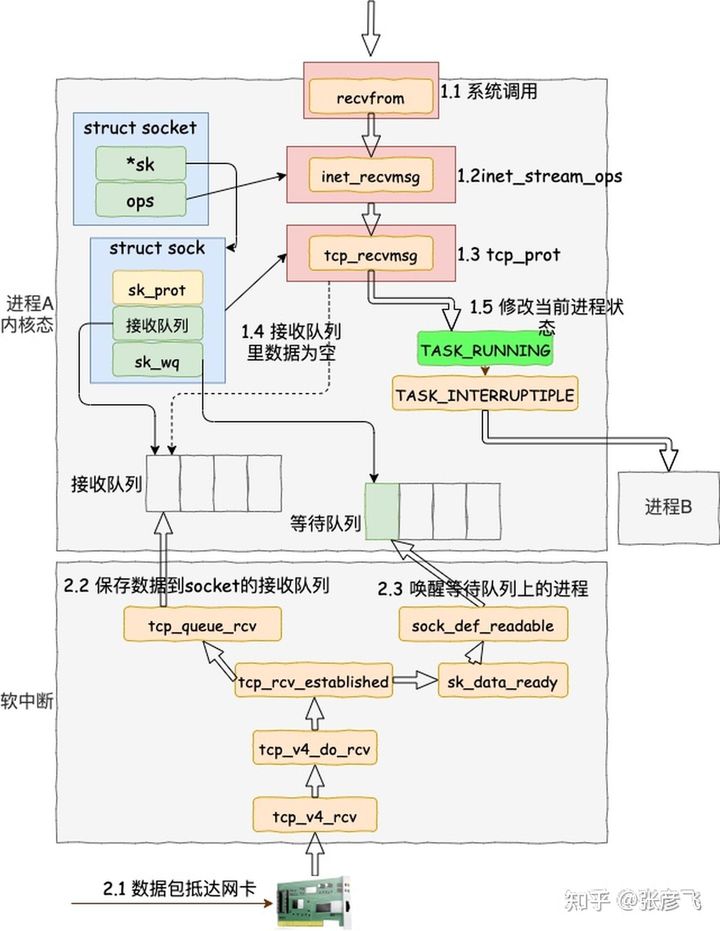
这种网络IO模型的问题是每次一个进程专门为了等一个 socket 上的数据就得被从 CPU 上拿下来。然后再换上另一个进程。等到数据 ready 了,睡眠的进程又会被唤醒。总共两次进程上下文切换开销,根据之前的测试来看,每一次切换大约是 3-5 us(微秒)左右。 如果是网络 IO 密集型的应用的话,CPU 就不停地做进程切换这种无用功。

所以多路IO复用,包括 epoll 就是为了解决上述问题而生的。当然 epoll 由于要支持海量的连接,为了高效地插入和删除 socket,在2.6 以后的版本里引入了红黑树。
epoll 作为多路复用技术中的代表,和传统的阻塞网络 IO 相比,最大的性能提升就是节约掉了大量的进程上下文切换。 epoll 内部又涉及出了一套复杂的数据结构,包括一棵红黑树和一个就绪链表(以及一个epollwait等待队列)。全部都工作在内核态。
使用 epoll 大体上由三个函数配合而成,分别是 epoll_create 、epollctl 和 epoll_wait,另外内核的网络模块也会参与其中。接下来我就分这四块来讲。这些都是我看过源码后整理出来的,源码版本是 3.10.0。
一、epoll_create 创建 epoll 内核对象
在用户进程调用 epoll_create 时,内核会创建一个 struct eventpoll 的内核对象。当然了这个对象,并不是由一个结构体构成的,而是一组数据结构。它的结构如下。
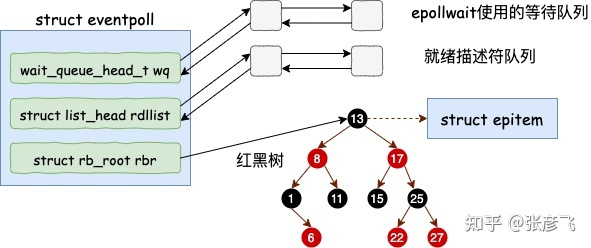
当然了,刚刚创建的 epoll 中就绪队列、红黑树都是空的,我画出来是为了方便大家理解。
就绪队列中存放事件发生,需要处理的 socket。这样后面和用户进程协作的时候就非常的容易了,简单地去就绪队列中查看有没有 Ready,需要被处理的 socket。有就拿走处理。
通过红黑树,高效地管理海量的连接,这样即使有百万条连接,插入和删除起来也是能保证效率。
二、epoll_ctl 添加 socket
epoll_ctl 所做的事情包括如下三件:
- 1.分配一个红黑树节点对象 epitem,
- 2.添加等待事件到 socket 的等待队列中,其回调函数是 ep_poll_callback
- 3.将 epitem 插入到 epoll 对象的红黑树里
通过 epoll_ctl 添加两个 socket 以后,这些内核数据结构最终在进程中的关系图大致如下:
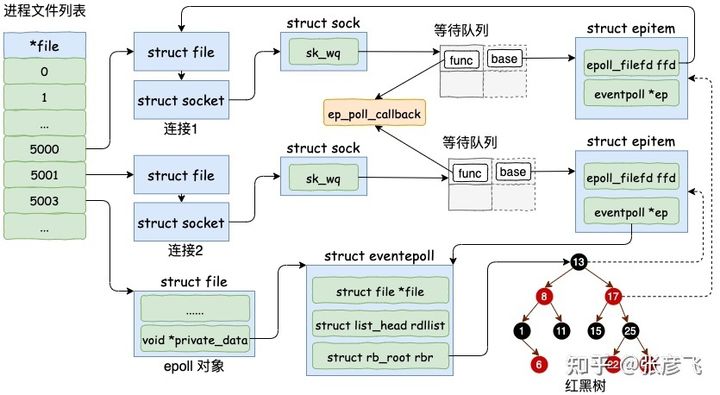
当内核将数据收到 socket 的接收队列后,将会通过 socket 上注册的这个 ep_poll_callback 函数来回调,进而通知到 epoll 对象。然后进一步将Ready 的socket 放到就绪链表中。
三、epoll_wait 等待事件
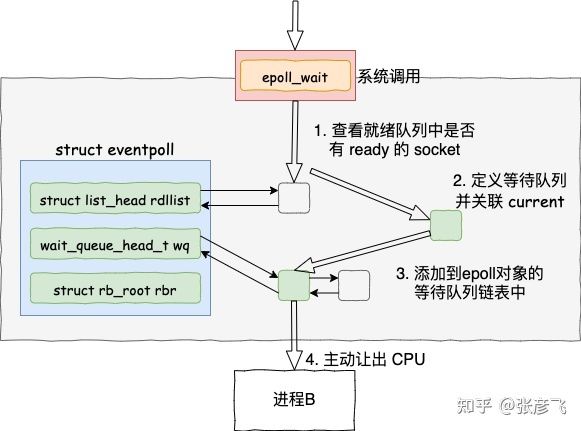
epoll_wait 做的事情其实不复杂,当它被调用时它观察 eventpoll->rdllist 就绪链表里有没有数据即可。有数据就返回,没有数据就创建一个等待队列项,将其添加到 eventpoll 的等待队列上,然后把自己阻塞掉就完事。
四、内核网络模块接收过程
内核的网络模块要做很多工作。首先是接收数据到 socket 的接收队列
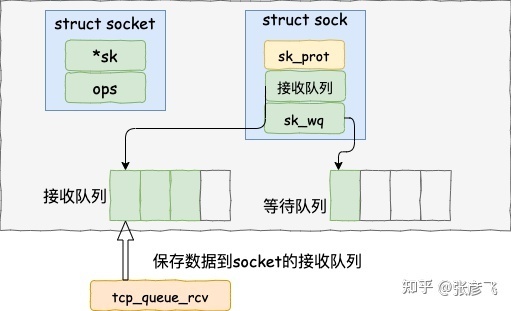
接着需要查找 socket 上的就绪回调函数
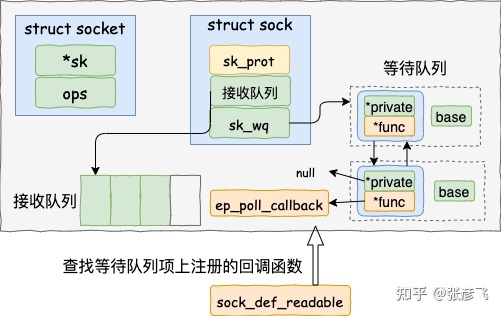
找到了 socket 等待队列项里注册的函数 ep_poll_callback后调用该函数,把当前的 epitem 添加到 epoll 的就绪队列中。接着它又会查看 eventpoll 对象上的等待队列里是否有等待项,如果没有进程阻塞在 epoll 上,内核的一次工作就算是完成了。如果有进程在阻塞,那就唤醒它。
五、epoll 整体工作流程图
我们来总结一下,这是 epoll_wait 的工作流程图。
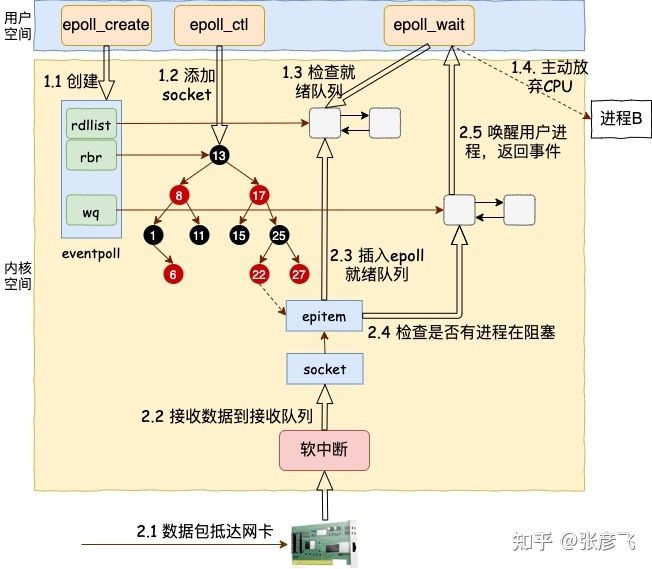
在这种模型下,只需要一个进程就可以维护成千上万甚至是百万级别的连接。正常情况下只要活儿足够的多,用户进程会一直干活,一直干活。大量地减少了进程切换次数,这就是 epoll 高效的地方所在!除非这个进程的除非实在是没有需要处理的连接了,epoll_wait才会将当前进程阻塞掉。
回答篇幅所限,很多内核源码就没办法贴了。想更详细地理解 epoll 的话建议把我这本《理解了实现再谈网络性能》下载下来慢慢看。这本 PDF 里除了 epoll 以外,还有很多关于网络是如何收包的,如何使用 CPU,如何使用内存的技术细节,非常值得一读。
下载链接传送门:《理解了实现再谈网络性能》
公众号:开发内功修炼
以上是关于epoll 或者 kqueue 的原理是什么?的主要内容,如果未能解决你的问题,请参考以下文章