数据清洗之异常值处理的常用方法(**盖帽法)
Posted 卖山楂啦prss
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据清洗之异常值处理的常用方法(**盖帽法)相关的知识,希望对你有一定的参考价值。
原文链接:https://zhuanlan.zhihu.com/p/358944859
作者:manny,数据分析师一枚
异常值是指那些在数据集中存在的不合理的值,需要注意的是,不合理的值是偏离正常范围的值,不是错误值。比如人的身高为-1m,人的体重为1吨等,都属于异常值的范围。虽然异常值不常出现,但是又会对实际项目分析有影响,造成结果的偏差,所以在数据挖掘的过程中不能不重视。
异常值出现的原因:数据集中的异常值可能是由于传感器故障、人工录入错误或异常事件导致。如果忽视这些异常值,在某些建模场景下就会导致结论的错误(如线性回归模型、K均值聚类等),所以在数据的探索过程中,有必要识别出这些异常值并处理好它们。
异常值检测
1.简单统计分析:最常用的统计量是最大值和最小值,用来判断这个变量的取值是否超出合理的范围。
2:3σ原则:3σ原则是建立在正态分布的等精度重复测量基础上而造成奇异数据的干扰或噪声难以满足正态分布。
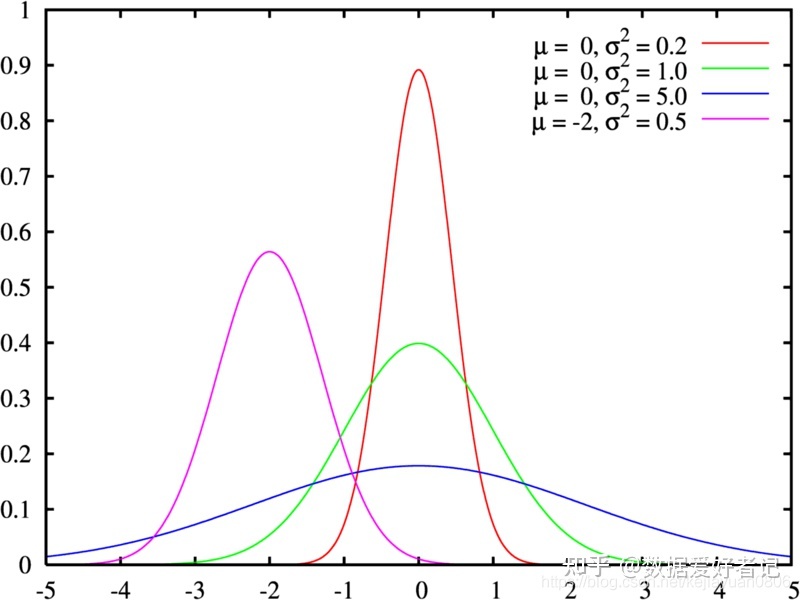
正态分布:又叫做高斯分布。特征为中间高两边低左右对称。正态分布特性:
集中性:曲线的最高峰位于正中央,并且位置为均数所在的位置。
对称性:以均数所在的位置为中心呈左右对称,并且曲线两段无限趋近于横轴。
均匀变动性:正态分布曲线以均数所在的位置为中心均匀向左右两侧下降。
正态分布函数公式如下:
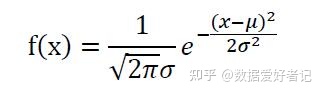
如果一组测量数据中的某个测量值的残余误差的绝对值 νi>3σ,则该测量值为坏值,应剔除。通常把等于 ±3σ的误差作为极限误差,对于正态分布的随机误差,落在 ±3σ以外的概率只有 0.27%,它在有限次测量中发生的可能性很小,故存在3σ准则。3σ准则是最常用也是最简单的粗大误差判别准则,它一般应用于测量次数充分多( n ≥30)或当 n>10做粗略判别时的情况。
σ代表标准差,μ代表均值
样本数据服从正态分布的情况下:
数值分布在(μ-σ,μ+σ)中的概率为0.6826
数值分布在(μ-2σ,μ+2σ)中的概率为0.9544
数值分布在(μ-3σ,μ+3σ)中的概率为0.9974
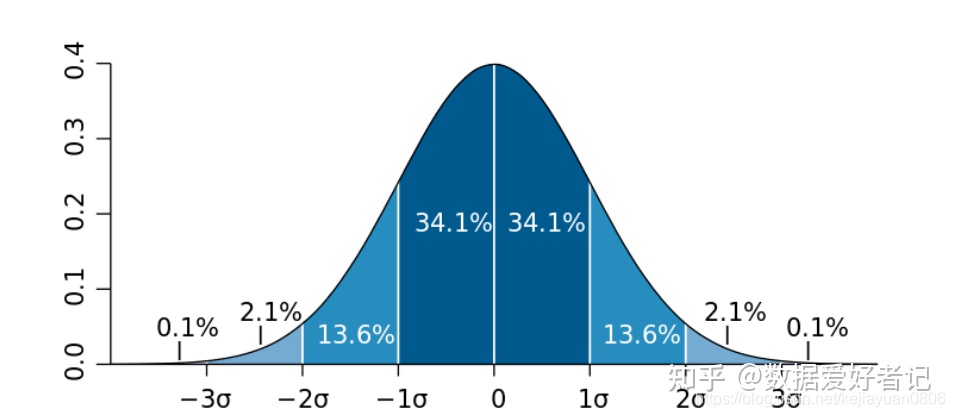
可以认为,Y 的取值几乎全部集中在(μ-3σ,μ+3σ)区间内,超出这个范围的可能性仅占不到0.3%。
3.箱线图:箱线图是通过数据集的四分位数形成的图形化描述,是非常简单而且效的可视化离群点的一种方法。
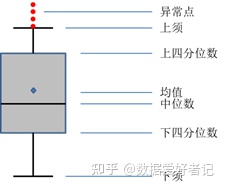
上下须为数据分布的边界,只要是高于上须,或者是低于下触须的数据点都可以认为是离群点或异常值。
下四分位数:25%分位点所对应的值(Q1)
中位数:50%分位点对应的值(Q2)
上四分位数:75%分位点所对应的值(Q3)
上须:Q3+1.5(Q3-Q1)
下须:Q1-1.5(Q3-Q1)
其中Q3-Q1表示四分位差
异常值处理
1.删除:直接将含有异常值的记录删除,通常有两种策略:整条删除和成对删除。这种方法最简单简单易行,但缺点也不容忽视,一是在观测值很少的情况下,这种删除操作会造成样本量不足;二是,直接删除、可能会对变量的原有分布造成影响,从而导致统计模型不稳定。
2.视为缺失值:利用处理缺失值的方法来处理。这一方法的好处是能够利用现有变量的信息,来填补异常值。需要注意的是,将该异常值作为缺失值处理,需要根据该异常值(缺失值)的特点来进行,针对该异常值(缺失值)是完全随机缺失、随机缺失还是非随机缺失的不同情况进行不同处理。
3.平均值修正:如果数据的样本量很小的话,也可用前后两个观测值的平均值来修正该异常值。这其实是一种比较折中的方法,大部分的参数方法是针对均值来建模的,用平均值来修正,优点是能克服了丢失样本的缺陷,缺点是丢失了样本“特色”。
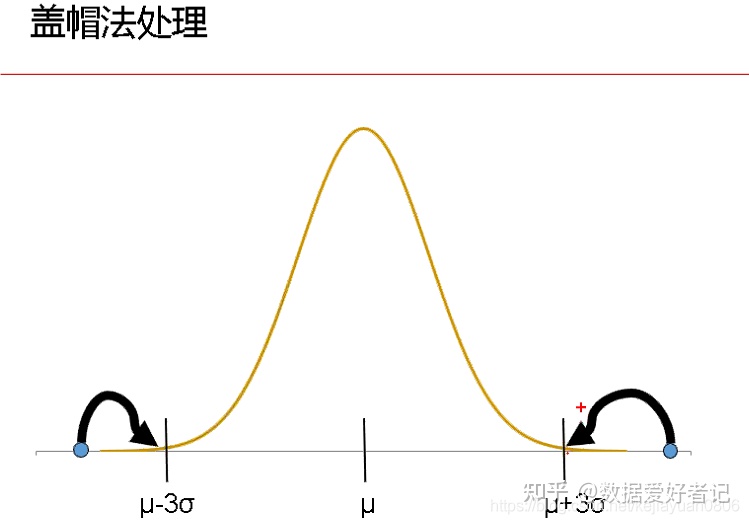
4.盖帽法:整行替换数据框里99%以上和1%以下的点,将99%以上的点值=99%的点值;小于1%的点值=1%的点值。
即
默认凡小于百分之1分位数和大于百分之99分位数的值将会被百分之1分位数和百分之99分位数替代
5.分箱法:分箱法通过考察数据的“近邻”来光滑有序数据的值。有序值分布到一些桶或箱中。包括等深分箱:每个分箱中的样本量一致;等宽分箱:每个分箱中的取值范围一致。
6.回归插补:发现两个相关的变量之间的变化模式,通过使数据适合一个函数来平滑数据。若是变量之间存在依赖关系,也就是y=f(x),那么就可以设法求出依赖关系f,再根据x来预测y,这也是回归问题的实质。实际问题中更常为见的假设是p(y)=N(f(x)),N为正态分布。假设y是观测值并且存在噪声数据,根据我们求出的x和y之间的依赖关系,再根据x来更新y的值,这样就能去除其中的随机噪声,这就是回归去噪的原理 。
7.多重插补:多重插补的处理有两个要点:先删除Y变量的缺失值然后插补
1)被解释变量有缺失值的观测不能填补,只能删除,不能自己乱补;
2)只对放入模型的解释变量进行插补。
8.不处理:根据该异常值的性质特点,使用更加稳健模型来修饰,然后直接在该数据集上进行数据挖掘。
如有不足,欢迎指正~~
以上是关于数据清洗之异常值处理的常用方法(**盖帽法)的主要内容,如果未能解决你的问题,请参考以下文章