Spark SQL 浅学笔记1
Posted 卖山楂啦prss
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark SQL 浅学笔记1相关的知识,希望对你有一定的参考价值。
工作学习笔记
首先复习了一下 Spark 简介
Spark是什么
Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。
Spark and Hadoop(Mapleduce )
Hadoop的 Mapleduce 已经是不错的计算框架了,为什么还要学习新的计算框架Spark呢?
首先明确 Spark 与 Hadoop中的MapReduce 是完全不同的计算引擎。两者各自存在的目的不尽相同。
-
Hadoop是由java语言编写的,包括HDFS分布式数据存储功能,还有MapRecue的数据计算处理功能,以及YARN的资源调试系统。
Hadoop虽然也有计算框架MapReduce,但是其运算速度较慢,运算结果必须送回HDFS即Hadoop的存储框架。
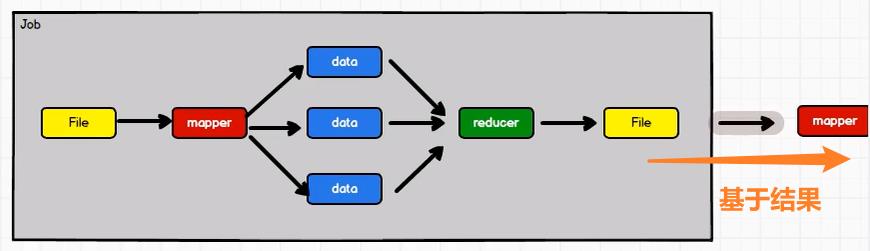
-
而Spark是由Scala语言开发的,是一个用来对那些分布式存储的大数据进行分析计算的框架,其中间结果可以存到内存中,因此对迭代大数据运算效果提升显著。但Sprak没有文件管理系统,即不会进行分布式数据的存储。所以通常要与Hadoop结合使用,默认来说Spark一般是被用在Hadoop上面的。
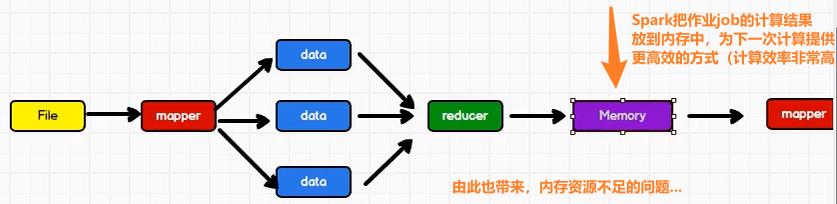
引用:《Spark SQL入门与实践指南》
MapReduce这个框架缺少了对分布式内存利用的抽象,这就导致了在不同的计算任务间(比如说两个MapReduce工作之间)对数据重用的时候只能采用将数据写回到硬盘中的方法。而计算机将数据写回到磁盘的这个过程耗时是很长的,将大量的时间消耗在I/O上
RDDs(弹性分布式数据集RDDs是一个具有容错性和并行性的数据结构,它可以让我们将中间结果持久化到内存中)。
因此可以看出,Spark和Hadoop的根本差异是多个作业之间的数据通信问题:Spark多个作业之间数据通信是基于内存,而Hadoop是基于磁盘。
Spark ⇒ Spark SQL
Hadoop上面有Hive,Hive能把SQL转成MapReduce作业,为不懂MR的人来说大大地提高程序的编写效率
后来,Spark出来后,也模仿Hive,提出了Shark,Shark将SQL语句转成RDD执行。
但是Shark对Hive 存在依赖,使得Shark的发展受到限制,于是研发Shark的一批人开始转移到 Spark SQL
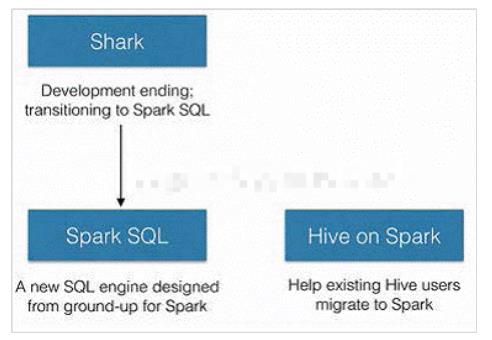
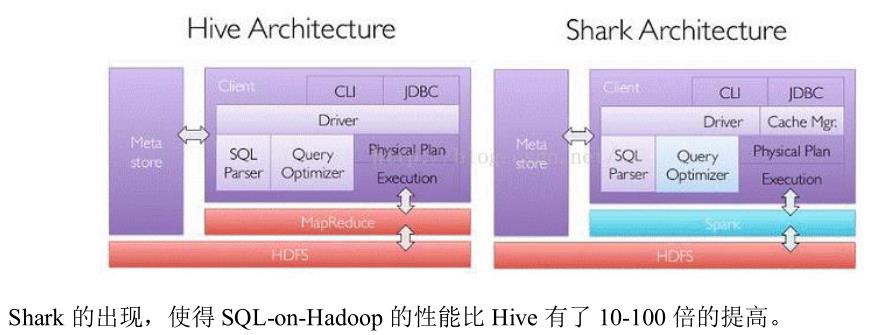
总的来说:Hive是Shark的前身,Shark是SparkSQL的前身,SparkSQL产生的根本原因是其完全脱离了Hive的限制。说白了,Spark SQL就是以RDD为核心计算框架,解决MR计算速度慢的问题!官方数据认为spark比传统mapreduce快10-100倍
SparkSQL抛弃原有 Shark 的代码,汲取了 Shark 的一些优点,如内存列存储(In-Memory
ColumnarStorage)、Hive兼容性等,重新开发了SparkSQL代码;由于摆脱了对Hive的依赖性,SparkSQL无论在数据兼容、性能优化、组件扩展方面都得到了极大的方便,真可谓“退一步,海阔天空”。
这里查询了一下Spark on Hive与Hive on Spark,引用:https://zhuanlan.zhihu.com/p/80525047
Spark-SQL:Spark SQL引擎 + SparkRDD引擎
Spark on Hive: Hive只作为储存角色,Spark负责sql解析优化,执行。
Hive on Spark:Hive即作为存储又负责sql的解析优化,Spark负责执行。
Hive on Spark 是在Hive中配置Spark,运行方式入口是通过Hive,底层是有第三方的hive on> spark中间包自动转换MR引擎,变为SparkRDD引擎。Hive on Spark 是一个 Hive 的发展计划,该计划将 Spark 作为 Hive 的底层引擎之一,也就是说,Hive 将不再受限于一个引擎,可以采用 Map-Reduce、Tez、Spark 等引擎。
Spark on Hive 是在Spark中配置Hive,运行方式入口是通过Spark,底层通过配置Hive的hive-site.xml,hdfs-site.xml等配置文件来直接操作hive
SQL,其实是Hive的语法规则,但是计算还是本身的SparkRDD引擎。
对于开发人员来讲,SparkSQL 可以简化 RDD 的开发,提高开发效率,且执行效率非常快,所以实际工作中,基本上采用的就是 SparkSQL。Spark SQL 为了简化 RDD 的开发,提高开发效率,提供了 2 个编程抽象,类似 Spark Core 中的 RDD
➢ DataFrame
➢ DataSet
Spark SQL的应用
参考:《Spark SQL入门与实践指南》
以ETL的三个过程来看Spark SQL能什么
(1)E ——抽取:Spark SQL 可以从各种数据源中抽取数据,如HDFS、本地、mysql、HBase。并且Spark SQL支持多种文件类型;
(2)T——转换:通过Spark SQL可以进行常规的数据清洗、替换、转换等操作;
(3)L——加载:数据处理完成后,通过Spark SQL能够将数据加载或存储在各种数据源中。
除此之外,Spark SQL还有很多其他的功能,比如结合Streaming搭配处理实时的数据流,和MLib搭配完成一些机器学习的应用。
Spark SQL的语法和传统SQL区别?
SparkSQL 支持大部分SQL语法,spqrk2.0后,应该可以兼容SQL了
说到这,想到了大数据开发,因为目前是在做这个,看到知乎上的回答,真是感慨

以上是关于Spark SQL 浅学笔记1的主要内容,如果未能解决你的问题,请参考以下文章