利用Python做简单的数据可视化
Posted 卖山楂啦prss
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了利用Python做简单的数据可视化相关的知识,希望对你有一定的参考价值。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from pylab import mpl
# 正常显示中文标签
mpl.rcParams['font.sans-serif'] = ['KaiTi']
# 正常显示负号
mpl.rcParams['axes.unicode_minus'] = False
import warnings
warnings.filterwarnings("ignore")
import os
os.chdir(r'C:\\Users\\\\ABC\\Desktop')
# 导入数据
data = pd.read_csv('order.csv',encoding='gbk')
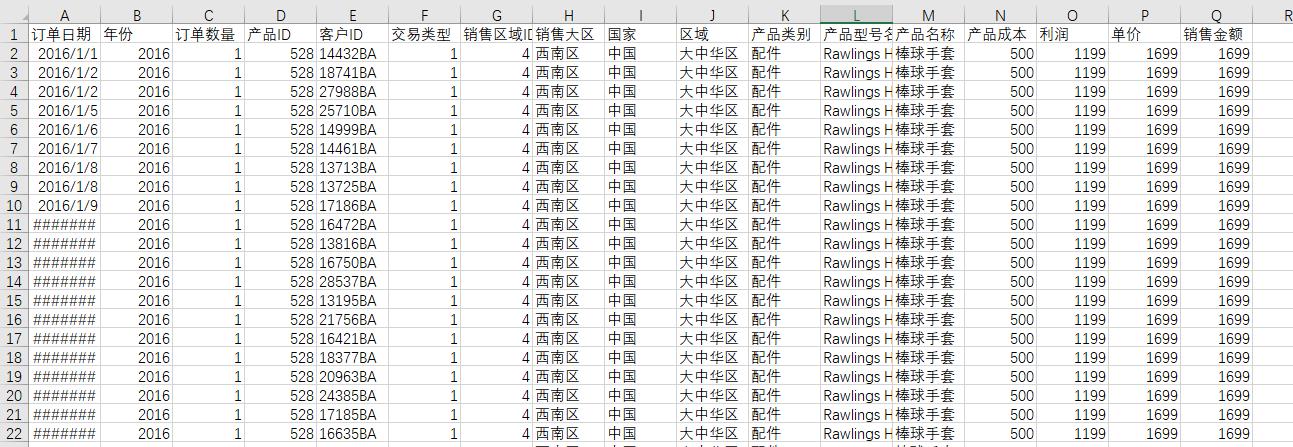
# 销售金额饼图
plt.figure(figsize=(4,4),dpi=150)
dataname = data['产品类别']
freq = dataname.value_counts()
colors = ['#99CCFF','#CCFF66','#FFCC99']
plt.pie(freq, labels = freq.index, explode = (0.05, 0, 0), autopct = '%.1f%%', textprops={'fontsize': 12}, colors = colors, startangle = 90, counterclock = False)
plt.axis('square')
plt.legend(loc='upper right', bbox_to_anchor=(1.2, 0.2),prop={'size': 10})
plt.show()
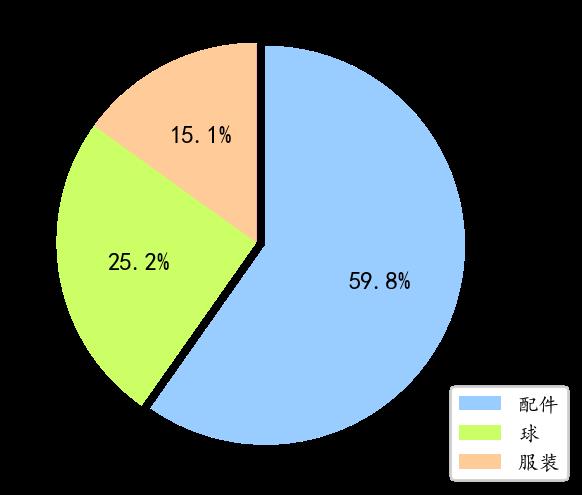
plt.figure(figsize=(6,3),dpi=150)
color_palette = sns.color_palette()
plt.subplot(121)
sns.countplot('区域',data = data, palette=color_palette)
plt.xlabel('区域',fontsize=10)
plt.xticks(fontsize=10)
plt.tight_layout()
plt.subplot(122)
sns.countplot('产品类别',data = data)
plt.xlabel('产品类别',fontsize=10)
plt.xticks(fontsize=10)
plt.tight_layout()
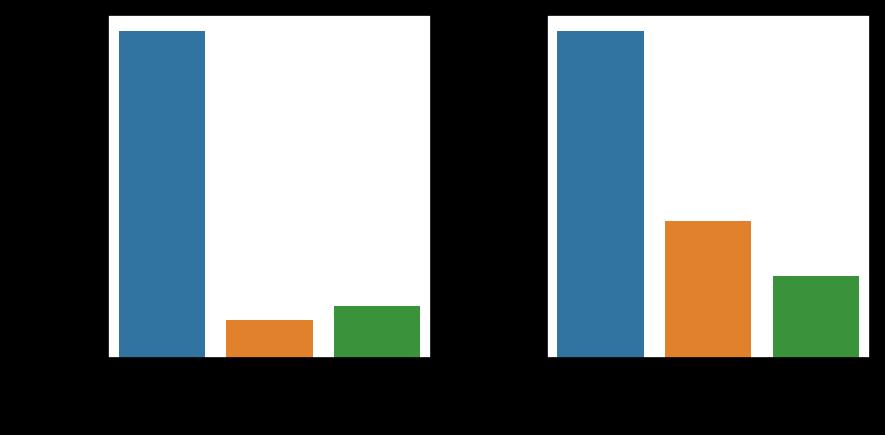
color = sns.color_palette()
plt.figure(figsize=(15,7))
sns.countplot(x = '产品名称',data = data, order = data['产品名称'].value_counts().index)
plt.xlabel('产品名称',fontsize=15)
plt.ylabel('count',fontsize=15)
plt.xticks(fontsize=15,rotation=45)
plt.yticks(fontsize=15)
plt.show()
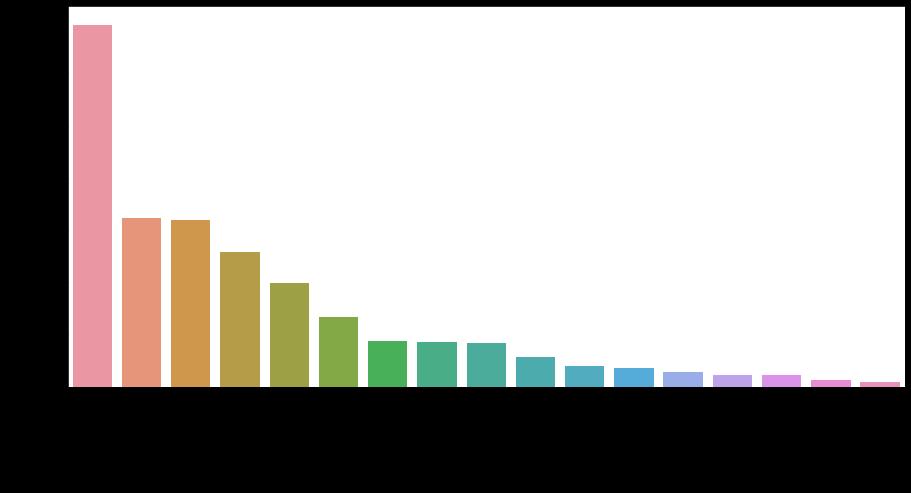
plt.figure(1 , figsize = (10 , 14))
sns.barplot(data["产品型号名称"].value_counts(dropna=False),
data["产品型号名称"].value_counts(dropna=False).keys())
plt.xticks(fontsize=13)
plt.yticks(fontsize=13)
plt.xlabel('产品型号名称',fontsize=16)
plt.show()
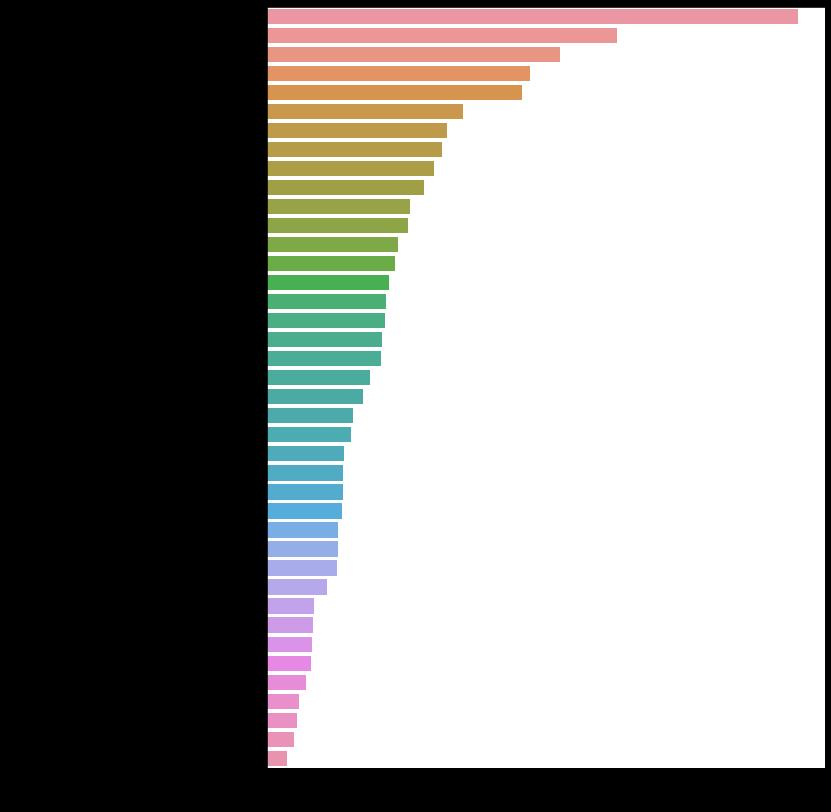
plt.figure(figsize=(7,7))
df = data[['产品成本','利润','单价','销售金额']]
corr = df.corr()
#相关性矩阵的可视化
sns.heatmap(df.corr(), center=0,
square=True, linewidths=.5, cbar_kws={"shrink": .5},annot=True, fmt='.1f')
plt.tight_layout()
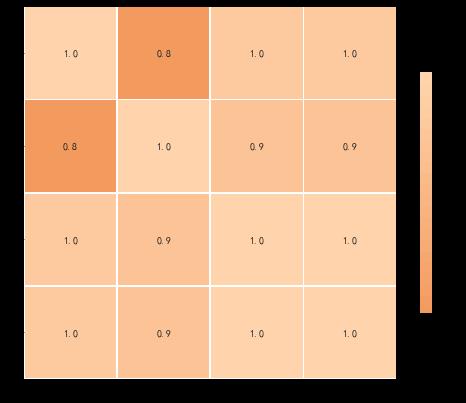
# 箱型图
plt.figure(figsize=(13,5))
color = sns.color_palette()
plt.subplot(141)
sns.boxplot(data=data['产品成本'],color=color[1])
plt.xlabel('产品成本',fontsize=15)
plt.yticks(fontsize=15)
plt.tight_layout()
plt.subplot(142)
sns.boxplot(data=data['利润'],color=color[2])
plt.xlabel('利润',fontsize=15)
plt.yticks(fontsize=15)
plt.tight_layout()
plt.subplot(143)
sns.boxplot(data=data['单价'],color=color[3])
plt.xlabel('单价',fontsize=15)
plt.yticks(fontsize=15)
plt.tight_layout()
plt.subplot(144)
sns.boxplot(data=data['销售金额'],color=color[3])
plt.xlabel('销售金额',fontsize=15)
plt.yticks(fontsize=15)
plt.tight_layout()
plt.show()
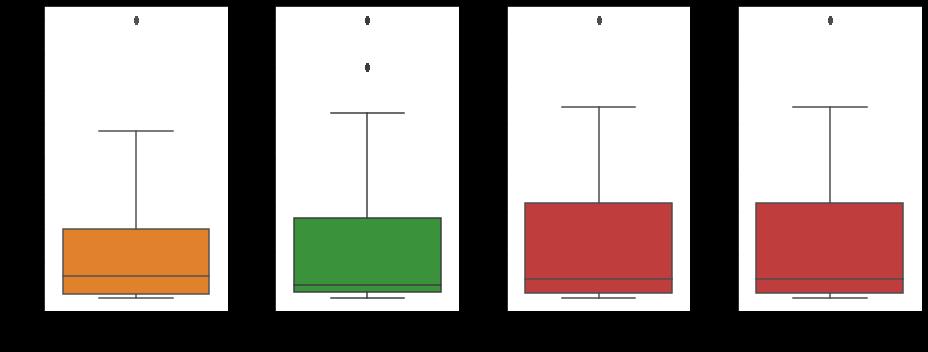
#sns.set(rc = {'figure.figsize':(16,10)})
plt.figure(figsize=(12,7))
sns.countplot(x = '区域',hue = '交易类型',data = data)
plt.xlabel('区域',fontsize=15)
plt.yticks(fontsize=15)
plt.show()
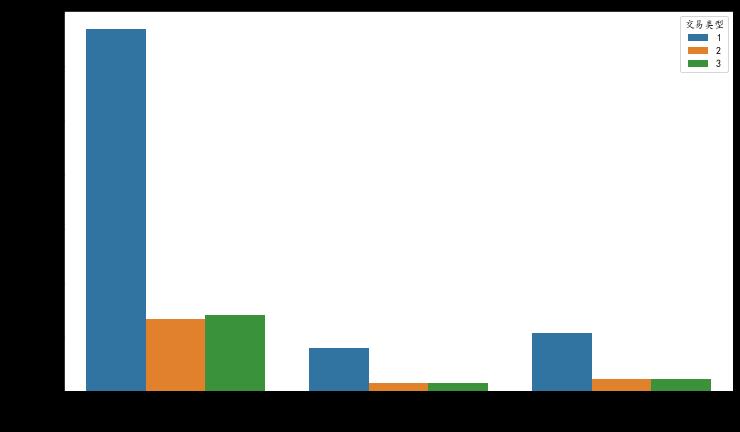
sns.set_style("whitegrid") # 使用whitegrid主题
fig,axes=plt.subplots(nrows=2,ncols=2,figsize=(17,7))
# 正常显示中文标签
mpl.rcParams['font.sans-serif'] = ['KaiTi']
# 正常显示负号
mpl.rcParams['axes.unicode_minus'] = False
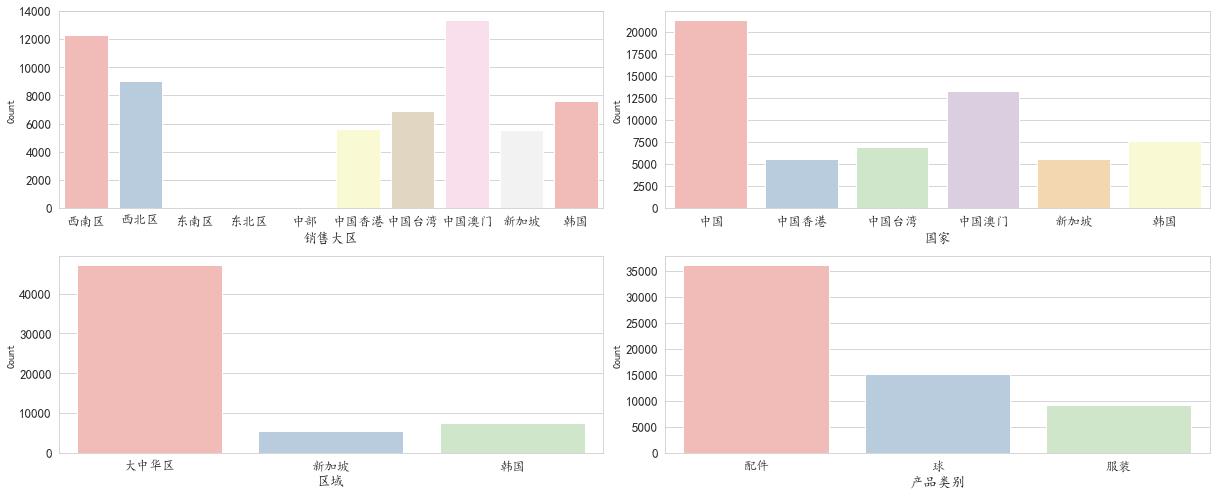
df = data[['销售大区','国家','区域','产品类别']]
for i, item in enumerate(df):
plt.subplot(2,2,(i+1))
#ax=df[item].value_counts().plot(kind = 'bar')
ax=sns.countplot(item,data = df,palette="Pastel1")
plt.xlabel(str(item),fontsize=14)
plt.ylabel('Count',fontsize=10)
plt.xticks(fontsize=13)
plt.yticks(fontsize=13)
#plt.title("Churn by "+ str(item))
i=i+1
plt.tight_layout()
plt.show()
# 正常显示中文标签
mpl.rcParams['font.sans-serif'] = ['KaiTi']
# 正常显示负号
mpl.rcParams['axes.unicode_minus'] = False
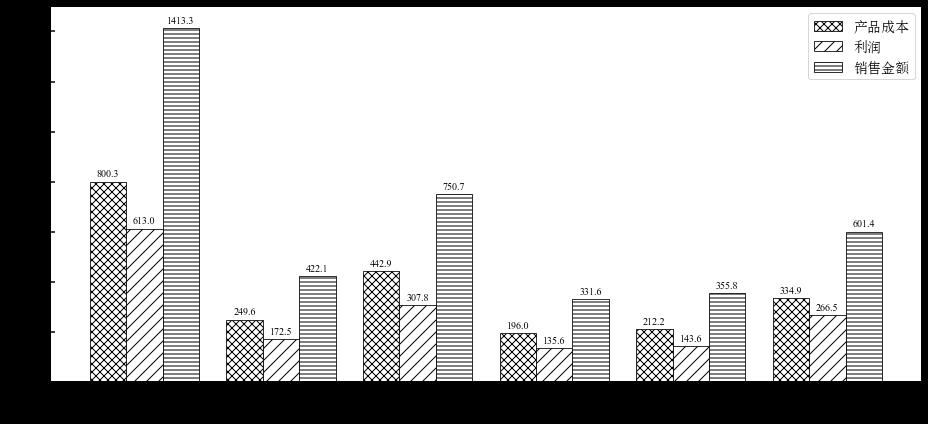
df = pd.pivot_table(data, values=["产品成本",'利润','销售金额'], index=["国家"], aggfunc=np.sum)
labels = df.index.tolist()
y1 = [round(i/10000,1) for i in df['产品成本'].values.tolist()]
y2 = [round(i/10000,1) for i in df['利润'].values.tolist()]
y3 = [round(i/10000,1) for i in df['销售金额'].values.tolist()]
plt.rcParams['font.family'] = ['Times New Roman']
fig,ax = plt.subplots(1,1,figsize=(13,6))
width = 0.35 #每根柱子宽度
label_font = {
'weight':'bold',
'size':14,
'family':'simsun'
}
x = np.arange(len(labels))
total_width, n = 0.8, 3
width = total_width / n
x = x - (total_width - width) / 2
rects1 = ax.bar(x, y1, width, label='产品成本',ec='k',color='w',lw=.8,
hatch='xxx')
rects2 = ax.bar(x + width, y2, width, label='利润',ec='k',color='w',
lw=.8,hatch='//')
rects3 = ax.bar(x + width * 2, y3, width, label='销售金额',ec='k',color='w',
lw=.8,hatch='---')
ax.tick_params(which='major',direction='in',length=5,width=1.5,labelsize=11,bottom=False)
# labelrotation=0 标签倾斜角度
ax.tick_params(axis='x',labelsize=11,bottom=False,labelrotation=0)
ax.set_xticks(range(len(labels)))
ax.set_xlabel('国家',fontdict=label_font)
ax.set_ylim(ymin = 0,ymax = 1500)
ax.set_ylabel('单位:万元',fontdict=label_font)
ax.set_xticklabels(labels,fontdict=label_font)
ax.legend(prop =label_font)
# 上下左右边框线宽
linewidth = 2
for spine in ['top','bottom','left','right']:
ax.spines[spine].set_linewidth(linewidth)
def autolabel(rects):
for rect in rects:
height = rect.get_height()
ax.annotate('{}'.format(height),
xy=(rect.get_x() + rect.get_width() / 2, height),
xytext=(0, 3), # 3 points vertical offset
textcoords="offset points",
ha='center', va='bottom')
autolabel(rects1)
autolabel(rects2)
autolabel(rects3)
fig.tight_layout()
plt.show()
# 在下图中,中国在产品成本、利润、销售金额均高于其他国家。
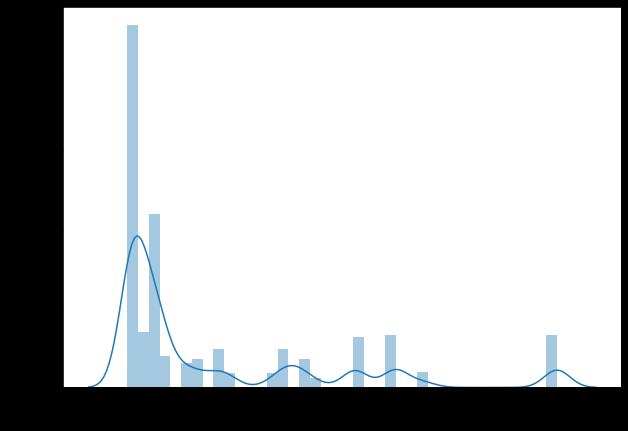
plt.figure(1 , figsize = (10 , 7))
sns.distplot(data['单价'],bins=40)
plt.xlabel('单价',fontsize=15)
plt.ylabel('Density',fontsize=15)
plt.xticks(fontsize=13)
plt.yticks(fontsize=13)
plt.show()
# 安装
# pip install -i https://pypi.doubanio.com/simple/ --trusted-host pypi.doubanio.com pyecharts
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.globals import ThemeType
from pyecharts.faker import Faker
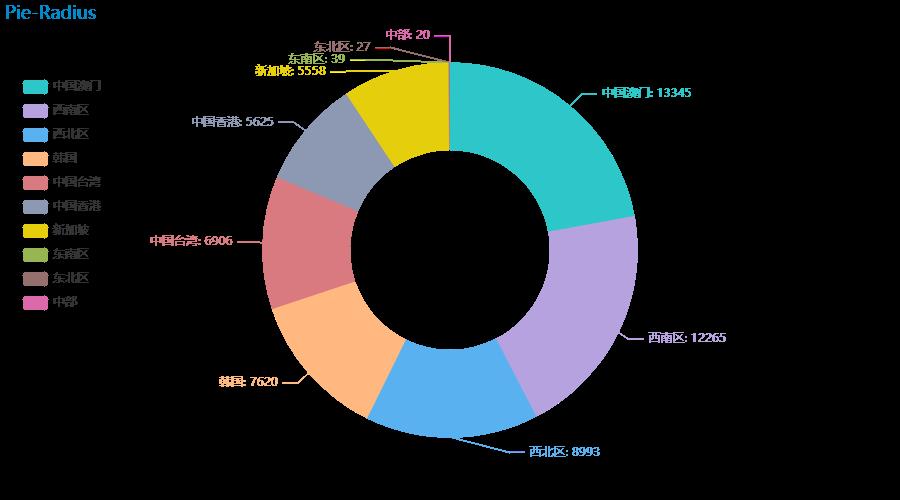
dataname = data['销售大区']
freq = dataname.value_counts()
c = (
Pie(init_opts=opts.InitOpts(theme=ThemeType.MACARONS))
.add(
"",
[list(z) for z in zip(freq.index.tolist(), freq.values.tolist())],
# 饼图的半径,数组的第一项是内半径,第二项是外半径
# 默认设置成百分比,相对于容器高宽中较小的一项的一半
radius=["40%", "75%"],
)
.set_global_opts(
title_opts=opts.TitleOpts(title="Pie-Radius"),
legend_opts=opts.LegendOpts(
orient="vertical", #图例垂直放置
pos_top="15%",# 图例位置调整
pos_left="2%"),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
c.render_notebook()
# 在下图中,销售大区中,中国澳门占比最大
import pyecharts.options as opts
from pyecharts.charts import Pie
from pyecharts.globals import ThemeType
dataname = data['国家']
freq = dataname.value_counts()
x_data = freq.index.tolist()
y_data = freq.values.tolist()
data_pair = [list(z) for z in zip(x_data, y_data)]
data_pair.sort(key=lambda x: x[1]) # 排序
c=(
# 初始化
Pie(init_opts=opts.InitOpts(
width="900px",
height="600px",
theme=ThemeType.MACARONS))
.add(
series_name="访问来源",# 系列名称
data_pair=data_pair, # 系列数据项,格式为 [(key1, value1), (key2, value2)]
# 是否展示成南丁格尔图,通过半径区分数据大小,有'radius'和'area'两种模式。
# radius:扇区圆心角展现数据的百分比,半径展现数据的大小
# area:所有扇区圆心角相同,仅通过半径展现数据大小
rosetype="radius",
# 饼图的半径
radius="55%",
# 饼图的中心(圆心)坐标,数组的第一项是横坐标,第二项是纵坐标
# 默认设置成百分比,设置成百分比时第一项是相对于容器宽度,第二项是相对于容器高度
center=["50%", "50%"],
# 标签配置项
label_opts=opts.LabelOpts(is_show=False, position="center"),
)
#全局配置项
.set_global_opts(
# 设置标题
title_opts=opts.TitleOpts(
title="Customized Pie",
pos_left="center",
pos_top="20",
title_textstyle_opts=opts.TextStyleOpts(color="#fff"),
),
# 设置图例
legend_opts=opts.LegendOpts(is_show=True),
)
# 系统配置项
.set_series_opts(
# 设置提示框
tooltip_opts=opts.TooltipOpts(
trigger="item", formatter="{a} <br/>{b}: {c} ({d}%)"
利用Python做简单的数据可视化2二手房数据