Kubernetes 核心组件原理梳理,运维必备~
Posted 果子哥丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kubernetes 核心组件原理梳理,运维必备~相关的知识,希望对你有一定的参考价值。
通俗易懂K8s
0. k8s 的架构
云原生概念:
为了让应用程序(项目,服务软件)都运行在云上的解决方案,这样方案叫做云原生,有以下特点:
- 容器化:所有的服务都必须部署在容器中。
- 微服务:web 服务架构是微服务架构
- CI/CD:可持续交互和可持续部署
- DevOps:开发和运维密不可分
k8s 集群(Cluster)
一个 master 对应一群 node 节点

master 节点
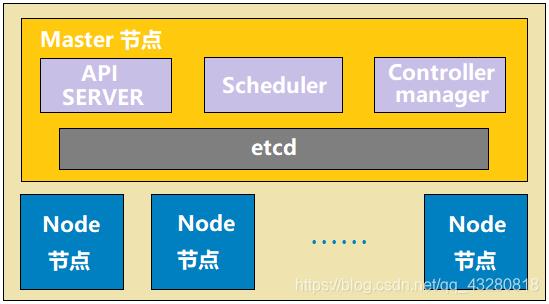
- api server:相当于 k8s 的网关,所有的指令请求都必须经过 api server
- scheduler:调度器,使用调度算法,把请求资源调度到某个 node 节点
- controller:控制器,维护 k8s 资源对象(CRUD:添加、删除、更新、修改)
- etcd:存储资源对象(可以服务注册、发现等等)
node 节点

- docker:运行容器的基础环境,容器引擎
- kubelet:每个 node 节点都有一份kubelet,在 node 节点上的资源操作指令由 kuberlet 来执行,scheduler 把请求交给api ,然后 api sever 再把信息指令数据存储在 etcd 里,于是 kuberlet 会扫描 etcd 并获取指令请求,然后去执行
- kube-proxy:代理服务,在多个 pod 间负载均衡
- fluentd:日志收集服务
- pod:k8s 管理的基本单元(最小单元),pod 内部是容器。k8s 不直接管理容器,而是管理 pod
1. 核心组件原理 —— pod 核心原理
1.1 pod 是什么
pod 也可以理解是一个容器,装的是 docker 创建的容器,也就是用来封装容器的一个容器;
pod 是一个虚拟化分组, 有自己的 IP 地址和主机名 hostname,利用 namespace 进行资源隔离,相当于一台独立沙箱环境;
pod 相当于一台独立主机,内部可以封装一个或多个容器(通常是一组相关的容器),内部容器之间访问采用 localhost。
1.2 pod 用来干什么
通常情况下,在服务部署的时候,使用 pod 来管理一组相关的服务(一个 pod 中要么部署一个服务,要么部署一组有关系的服务)。如下图是部署了一组有关系的服务的结构图,其中 C 表示容器(container),下面的 pod 里就有很多个容器。

如何理解一组相关的服务?
如下图:有一个请求是访问 nginx,然后部署了 Nginx 的容器就把请求转发给部署了 web 服务的容器,web 再访问数据库,然后请求会依次返回来数据,最后再返回给用户。
因此在 链式调用的调用链路上的服务 叫做一组相关的服务。

1.3 实现 web 服务集群
只需要复制多个 pod 的副本即可,这也是 k8s 管理的先进之处。k8s 如果要进行扩容或缩容,只需要控制 pod 的数量即可。比如上面那个部署模式,服务集群就是复制多个这样的 pod。

1.4 pod 底层网络和数据存储是如何进行的
前面说过 pod 内部的容器也是一个独立的沙箱环境,因此也有自己的 ip 和 端口。如果内部容器还是通过 ip:port 来通信,相当于还是远程访问,这样的话性能会受到一定的影响。如何提高内部容器之间访问的性能呢?
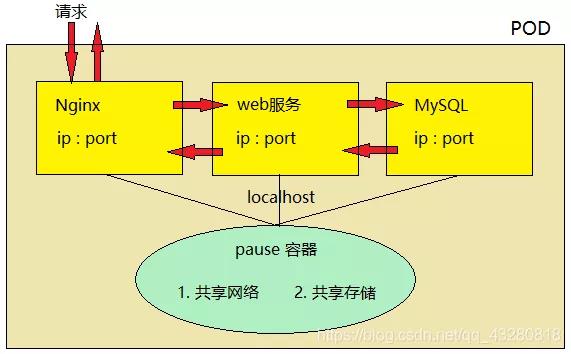
pod 底层
- pod 内部容器创建之前,必须先创建 pause 容器。pause 有两个作用:共享网络和共享存储。
- 每个服务容器共享 pause 存储,不需要自己存储数据,都交给 pause维护。
- pause 也相当于这三个容器的网卡,因此他们之间的访问可以通过 localhost 方式访问,相当于访问本地服务一样,性能非常高(就像本地几台虚拟机之间可以 ping 通)。
2. ReplicaSet 副本控制器
2.1 副本控制器基本理解
作用:管理控制 pod 副本(服务集群)的数量,以使其永远与预期设定的数量保持一致。
例如:replicas = 3 (创建 3 个副本,这是提前设置好的)

当副本设置为 3 时,副本控制器将会永远保证副本数量为 3。因此当有 pod 服务宕机时(如上面第 3 个 pod),那副本控制器会立马重新创建一个新的 pod,就能够保证副本数量一直为预先设定好的 3 个。
2.2 ReplicaSet 和 ReplicationController 的区别
ReplicaSet 和 ReplicationController 都是副本控制器,其中:
- 相同点:都有前面 2.1 节所描述的功能
- 不同点:标签选择器的功能不同。ReplicaSet 可以使用标签选择器进行 单选 和 复合选择;而 ReplicationController 只支持 单选操作。
什么意思呢?
假设下面有下面两个不同机器上的 Node 结点,如何知道它们的 pod 其实都是相同的呢?答案是通过标签。
给每个 pod 打上标签 ( key=value 格式,如下图中的 app=web, release=stable,这有两个选项,相同的pod副本的标签是一样的),于是副本控制器可以通过标签选择器 seletor 去选择一组相关的服务。
一旦 selector 和 pod 的标签匹配上了,就表明这个 pod 是当前这个副本控制器控制的,表明了副本控制器和 pod 的所属关系。如下图中 seletor 指定了 app = web 和 release=stable 是复合选择,要用 ReplicaSet 才能实现若用 ReplicationController 的话只能选择一个,如只选择匹配app=web标签。这样下面的 3 个 pod 就归这个副本控制器管。
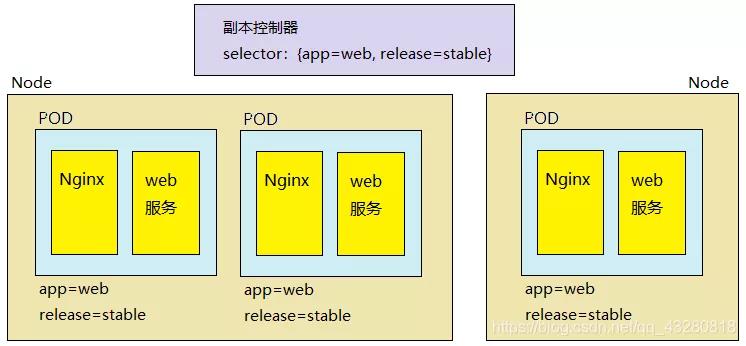
可见 ReplicaSet 功能更齐全,所以在新版的 k8s 中,建议使用 ReplicaSet 作为副本控制器,不再使用 ReplicationController。
3. Deployment 部署对象
3.1 滚动更新
ReplicaSet 副本控制器可以永久保持 pod 副本的数量。但是项目的需求在不断的迭代、更新,项目在不断发版。那如何做到服务更新?难道把服务停掉再把新版本部署上去吗?当然不是,答案是用滚动更新。就是重新创建一个 pod (v2版本) 来代替 之前的 pod (v1版本)。

那是如何滚动更新的呢?涉及到下面要讲到的部署模型。
3.2 部署模型
单独的 ReplicaSet 是不支持滚动更新的,Deployment 对象支持滚动更新,通常和 ReplicaSet 一起使用。
需要滚动更新时的步骤:
- Deployment 建立新的 Replicaset
- Replicaset 重新建立新的 pod
所以它们之间是有层次关系的,Deployment 管 Replicaset,Replicaset 维护 pod。在更新时删除的是旧的 pod,老版本的 ReplicaSet 是不会删除的,所以在需要时还可以回退以前的状态。
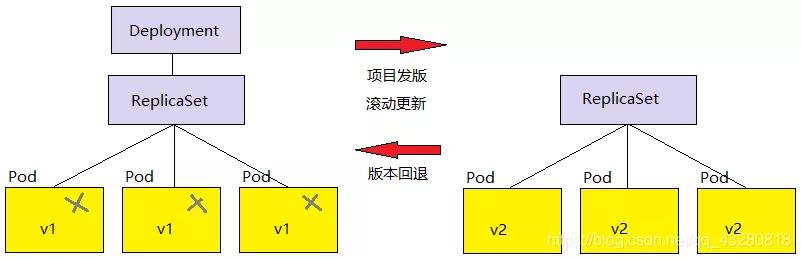
4. StatefulSet 部署有状态服务
4.1 引入定义
思考:如果 mysql(有状态服务) 使用容器化部署,会存在什么问题?
- 容器都是有生命周期的,一旦宕机数据就很可能丢失
- pod 也有生命周期的,用 pod 部署时把 pod 集群副本重启以后也可能会出现数据丢失
因此对 k8s 来说,不能使用 Deployment 部署有状态的服务。通常情况下,Deployment 被用来部署无状态服务。
然后 StatefulSet 就是为了解决有状态服务使用容器化部署的一个问题。
4.2 如何理解状态服务
有状态服务
- 有实时的数据需要存储
- 在有状态服务集群中,如果把某一个服务抽离出来,一段时间后再加入回集群网络,此后集群网络会无法使用
无状态服务
- 没有实时的数据需要存储
- 在无状态服务集群中,如果把某一个服务抽离出去,一段时间后再加入回集群网络,对集群服务无任何影响,因为它们不需要做交互,不需要数据同步等等。
4.3 部署模型
StatefulSet 的部署模型和 Deployment 的很相似。
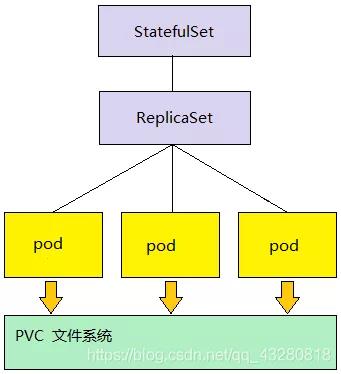
比如下图,借助 PVC(与存储有关) 文件系统来存储的实时数据,因此下图就是一个有状态服务的部署。
在 pod 宕机之后重新建立 pod 时,StatefulSet 通过保证 hostname 不发生变化来保证数据不丢失。因此 pod 就可以通过 hostname 来关联(找到) 之前存储的数据。
5. Pod通信
pod 网络
- pod 有自己独立的 IP 地址
- pod 内部的容器之间是通过 localhost 进行访问
5.1 pod 如何对外提供访问
首先 pod 有自己的 IP 和 hostname,但 pod 是虚拟的资源对象 (在计算机中表现为进程),没有对应实体 (物理机,物理网卡) 与之对应,所以是无法直接对外提供服务访问的。
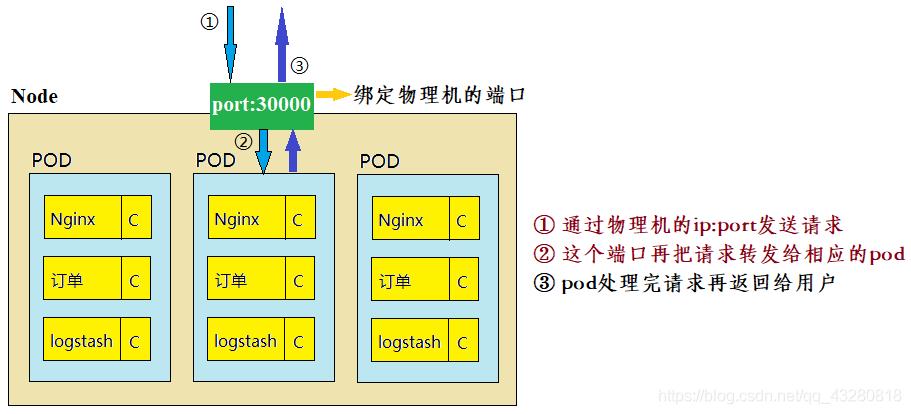
因此如果 pod 想对外提供服务,必须绑定物理机端口 (即在物理机上开启端口,让这个端口和 pod 的端口进行映射),这样就可以通过物理机进行数据包的转发。
下面以一台 Linux 系统的机器为例子( logstash 是做日志收集用的)
5.2 Pod的负载均衡
很关键的一个问题:一组相关的 pod 副本,如何实现访问负载均衡?就如当请求达到,请求转发给哪个 pod 比较好?
一个想法就是用 pod 再部署一个 Nginx。
举例:如下图,注意下图右边的 Node 里面有两个是 支付 服务,与订单服务的是不同类型的 pod。如果一个请求订单的服务发来上面那个 Nginx,那这个 pod 可以有 4 条转发路线,可以想到用 hash 呀什么的把不同请求映射到不同的 pod 去转发。但能不能这么做呢?
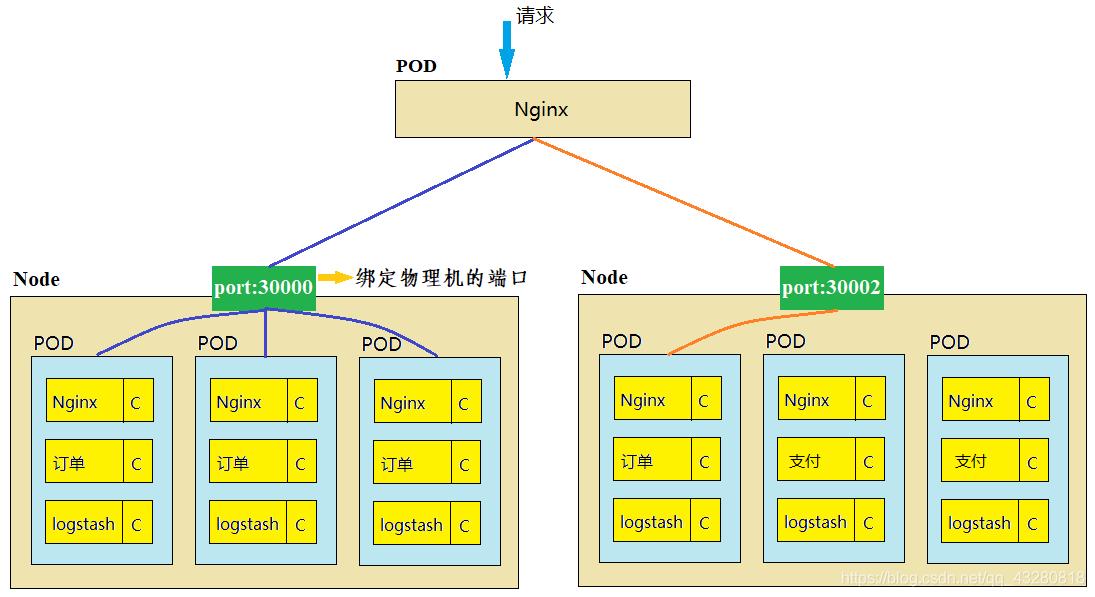
思考:pod 是一个进程,是有生命周期的,一旦宕机、版本更新都会创建新的 pod( IP 地址会变化,hostname 会变化),此时再使用 Nginx 做负载均衡不太合适,因为它不知道 pod 发生了改变,那请求就不能被接受了。所以服务发生了变化它根本不知道,Nginx 无法发现服务,不能用 Nginx 做负载均衡。那该如何实现呢?使用 Service 资源对象。
Service 资源对象
- POD IP:pod 的 IP 地址
- NODE IP:物理机的 IP 地址
- cluster IP:虚拟 IP,是由 kubernetes 抽象出的 service 对象,这个 service 对象就是一个 VIP (virtual IP, VIP) 的资源对象
service 如何实现负载均衡
例如现在要负载均衡地访问一组相同的服务副本——订单,这时就要去做一个 service,对外表现出是一个进程或资源对象,有虚拟的 IP (VIP) 和端口。请求会访问 service,然后 service 自己会 负载均衡 地发送给相应服务的 POD,也就是下图中 4 个相同的 pod。

深入 service VIP
- service 和 pod 都是一个进程,都是虚拟的,因此实际上 service 也不能对外网提供服务
- service 和 pod 之间可以直接进行通信,它们的通信属于局域网通信
- 负载策略:把请求交给 service 后,service 使用 iptables,ipvs 来实现数据包的分发
而要对外网提供服务,首先需要和之前一样 在物理机上也绑定一个端口 来接受访问请求,然后把请求转发给 service,service 再把数据包分发给相应的 POD。访问流程如下图所示:

思考1:那 service 对象是如何和 pod 进行关联的呢?
它们之间的关联利用的 还是标签选择器 selector。且service 只能对 一组相同的副本 提供服务,不能跨组提供服务。如果有另一组,需要再创建一个 service。因此不同的业务会有不同的 service。
举例:service 和 一组 pod 副本是通过标签选择器进行关联的,相同的副本的标签是一样的。
selector:app = x 选择一组订单的服务的 pod,创建一个 service;app = y 选择了一组支付的服务的 pod。通过一个 endpoints 属性存储这组 pod 的 IP 地址,这样就有了映射关系了 (关联起来)。

思考2:pod 宕机或发布新版本了,service 是如何发现 pod 已经发生变化的?
通过 k8s 中的一个组件 —— kube-proxy (第 1 篇有提到过),每个 NODE 里都运行着这个服务。它需要做的工作如下图右侧:

service 实现服务的发现:kube-proxy 监控 pod,一旦发现 pod 服务变化,将会把新的 ip 地址更新到 service。
注意:endpoints 那些都是存储在 etcd 里的 (也是第 1 篇提到过的),所以 kube-proxy 更新的存储在 etcd 里的映射关系。
以上是关于Kubernetes 核心组件原理梳理,运维必备~的主要内容,如果未能解决你的问题,请参考以下文章