缓存架构中分布式一致性hash应用解析
Posted 踩踩踩从踩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了缓存架构中分布式一致性hash应用解析相关的知识,希望对你有一定的参考价值。
前言
本篇文章会从什么是分布式一致性hash算法、hash算法在Memcached、Redis中的应用、以及Java本地缓存与分布式缓存绝佳组合、剖析从浏览器缓存到数据库缓存等;然后去解析一致性hash算法的应用。以及我们在项目应用中,并不是只应用redis等中间件去处理,也会结合本地缓存去处理实际的应用场景。
一致性Hash算法在缓存架构中应用
Hash+取模 在分布式架构下
分布式缓存集群
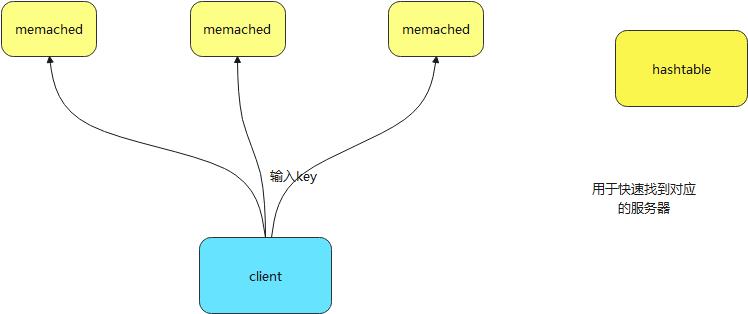
想要快速 ,算出key 所在节点,因为Hash所以高效。 因此在redis分片集群有个hash槽的概念,slots .
init长度有限,string长度无限,产生hash碰撞。在分布式系统下 缓存采用hash算法,hash碰撞。将链表进行扩长,然后使用hashtable进行存储查找数据
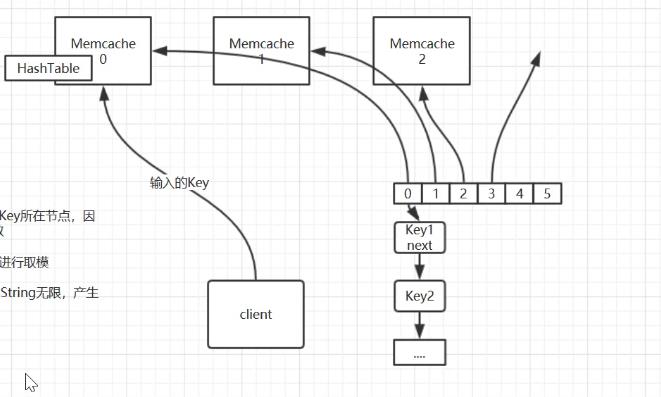
说到高性能的缓存,例如redis、memcache 离不开c语言,然后快速查找一定离不开hash算法。
在下面示例上的应用
3个节点的集群,数据 World:888
-
高并发场景,集群临时扩容,加一台机器!
- 增加一个节点后,有多大比例的数据缓存命不中?
这样引出一致性hash算法
一致性Hash算法
什么是一致性hash算法
一致性hash能保证在分布式环境中,对key进行哈希的结果或者说key与节点之间的映射关系不会受节点的增加和删除而产生重大的变化。
一致性哈希是一种特殊的哈希算法,提供了这样的一个哈希表,当重新调整大小的时候,平均只有部分(k/n)key需要重新映射哈希槽,而不像传统哈希表那样几乎所有key需要需要重新映射哈希槽
- hash值一个非负整数,把非负整数的值范围做成一个圆环;
- 对集群的节点的某个属性求hash值(如节点名称), 根据hash值把节点放到环上;节点对应圆环上
- 对数据的key求hash,一样的把数据也放到环上,按顺时针方向,找离它最近的节点,就存储到这个节点,永远取相邻的这个点
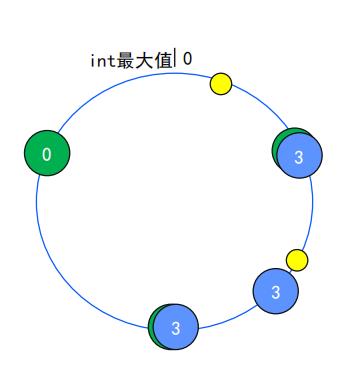
这样就解决扩容,数据不命中。减少对原有的配置等修改。
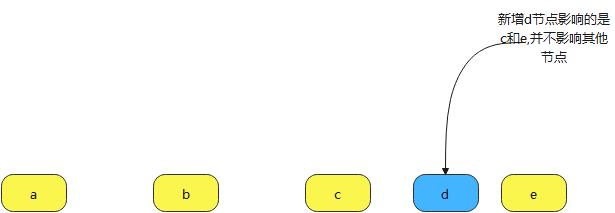
新增节点能均衡缓解并不能原有节点的压力,这是它会出现的问题,而且集群节点不会均匀的分布在圆环上,这是实践过程中会出现的问题,
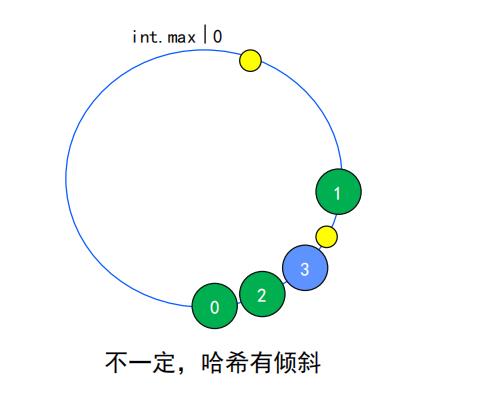
也是由于在圆环上添加节点过后,其他节点未动,会导致原有的请求,还是会到原来的节点上,不会影响其它节点,而且hash一定会有倾斜,就会导致看起来右下角一坨,不会均匀分布。
一致性Hash算法
利用虚拟节点去解决hash倾斜问题
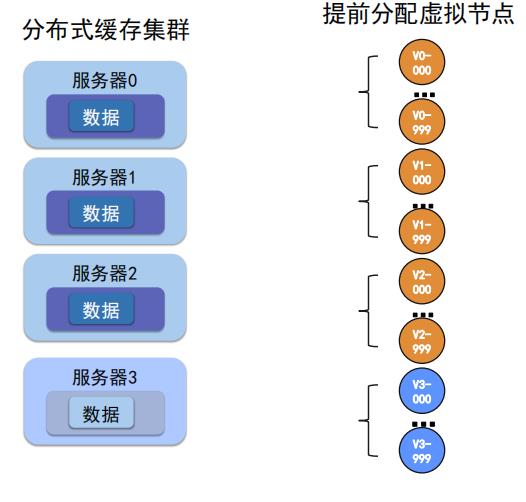
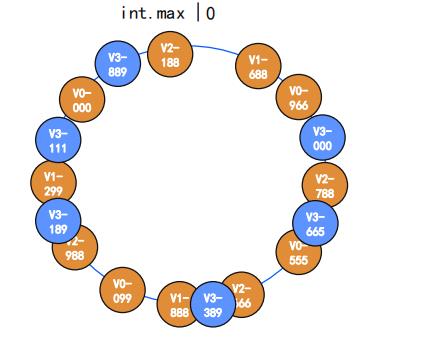
将 节点 进行 000-999 999-1000 .......等等虚拟节点上环,来分布数据
而且
这里例如在 memached中 利用KetamaMemcachedSessionLocator 达到一致性hash算法的作用
@Bean
public MemcachedClient memcachedClient() throws IOException {
String servers = clusterConfig;
MemcachedClientBuilder builder = new XMemcachedClientBuilder(AddrUtil
.getAddresses(servers));
// 默认的客户端计算就是 key的哈希值模以连接数
// KetamaMemcachedSessionLocator 一致性hash算法
builder.setSessionLocator(new KetamaMemcachedSessionLocator());
MemcachedClient client = builder.build();
return client;
}redis的slot机制 是一个经典的实现。
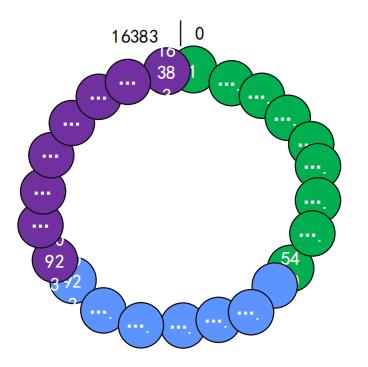
使用的范围是0-16383,默认情况下slot是连续排列的
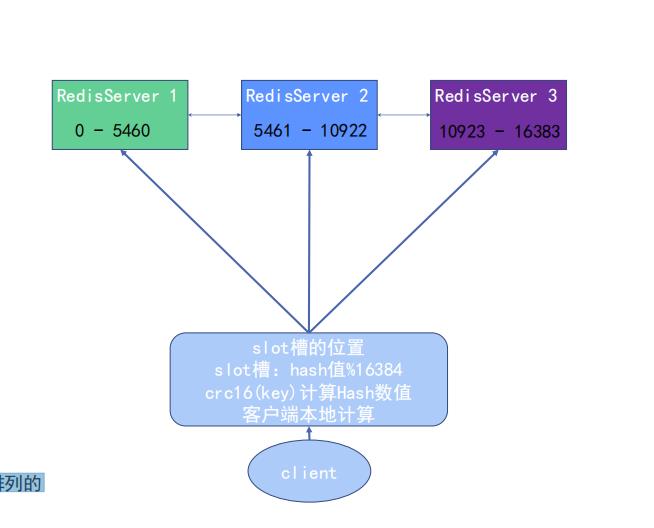
假设数据redisserver3的数据量非常大,也会弄的这个服务器压力非常大,因此可以将槽点移动一些到redisserver2
对于memached的选择,也是有一致性hash算法,去解决问题
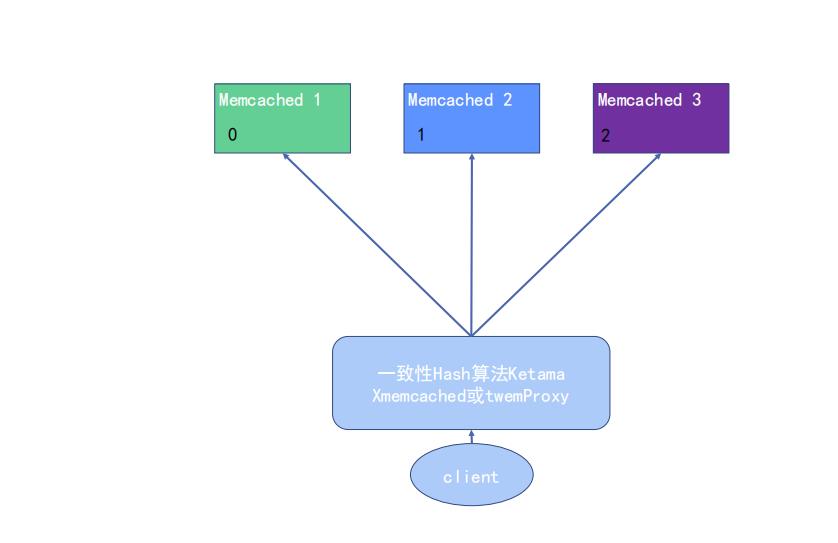
高性能体系之二级缓存
我们先理解一个概念,为提高效率,读多写少用缓存,读少写多用缓冲。
什么是二级缓存
L2Cache,即CPU的二级缓存。二级缓存是CPU性能表现的关键之一,在CPU核心不变化的情况下,增加二级缓存容量能使性能大幅度提高。而同一核心的CPU高低端之分往往也是在二级缓存上有差异,由此可见二级缓存对于CPU的重要性。
这是对于cpu中二级缓存的定义,而在缓存概念中多级缓存。根据效率和成本 现在比较流行的三级缓存。
对于我们在项目开发中,为提高效率,压榨性能,一般使用的方式
直接使用redis做为缓存
一个页面,每天800-1000万
从缓存读取数据50k
redis 一天要40-50g
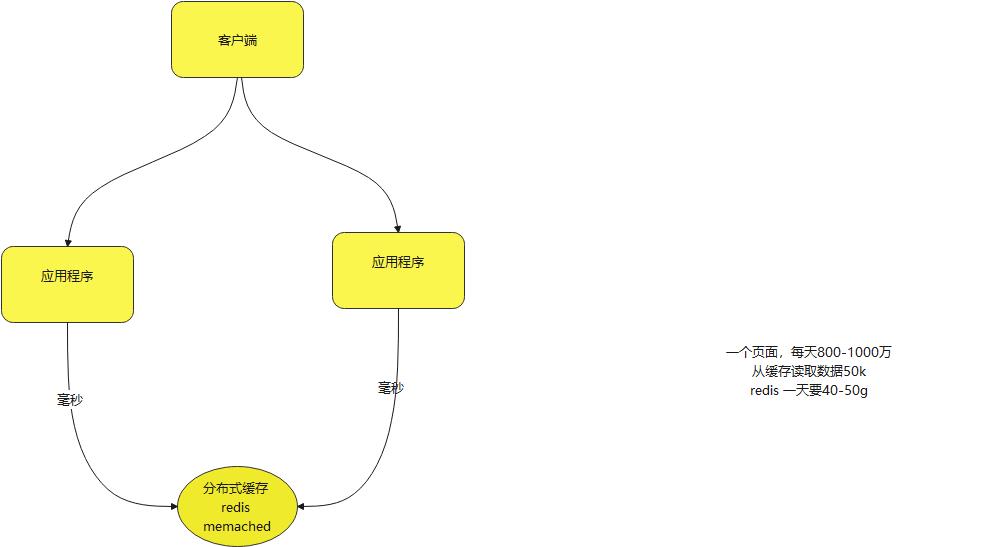
用这样的架构去处理,对于高峰期的时候,大于500m /秒 宽带是承受不住的,带宽是非常昂贵的,不足以解决问题
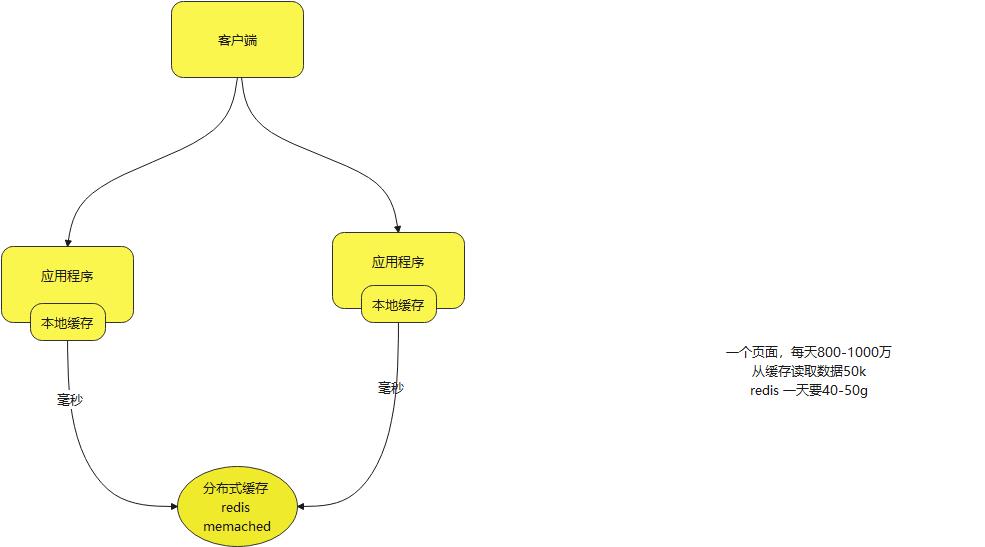
而作为本地缓存 用作的工具有
Guava(工具比较强大)、 Ehcache(可以使用堆外内存的)、Caffeine(基于Java 8的高性能)
为什么不采用hashmap作为一级缓存,自己写一个会少很多功能,优化不够。
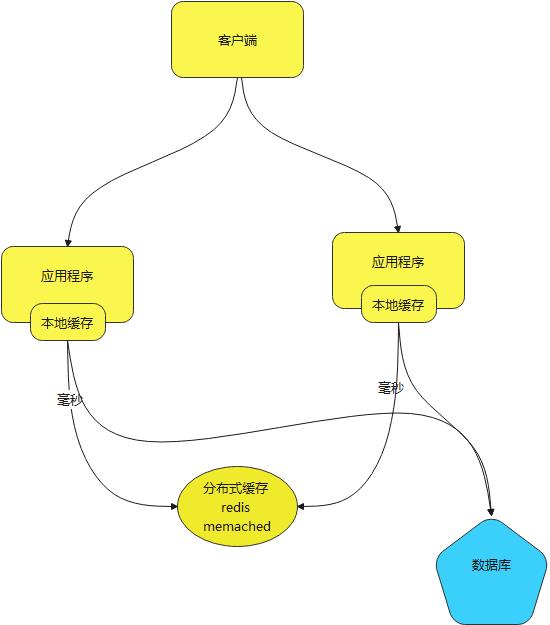
两边缓存的过期时间,要错开,不一致,本地缓存存的时间为了不影响本地其他功能,肯定是需要设置软引用,并且过期时间需要短,因此没有时,才到分布式的。
两级缓存技术-J2Cache
项目和文档地址:J2Cache: Java 两级缓存框架,可以让应用支持两级缓存框架 ehcache(Caffeine) + redis 。避免完全使用独立缓存系统所带来的网络IO开销问题 (gitee.com)
解决的是领域问题,分布式缓存和本地缓存特点不一致。Redis针对特定的key 设置过期时间,本地缓存无法做到。领域:把本地设置 分组同步到redis上,key是相同得。
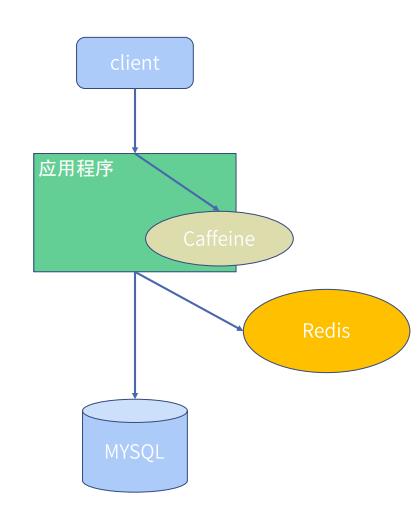
- 客户端向服务端发起请求
- 服务端先从本地缓存获取
- 本地缓存未命中从分布式缓存redis获取
- Redis缓存未命中从数据库中获取
解决的问题
- 使用应用本地缓存时,一旦应用重启后,由于缓存数据丢失,缓存雪崩,给数据库造成巨大压力,导致应用阻塞
- 使用应用本地缓存时,多个应用节点无法共享缓存数据
- 使用分布式缓存 ,由于大量的数据通过缓存获取,导致缓存服务的数据吞吐量太大,带宽跑满,现象就是redis服务负载不高,但是由于机器网卡爬满,导致数据读取非常慢。
在代码中引用
这两个都可以使用,或者使用其中一个就可以 redis ,然后引入j2cache 依赖就可以
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>${jedis.version}</version>
</dependency>
<dependency>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
<version>${lettuce.version}</version>
</dependency>
<dependency>
<groupId>net.oschina.j2cache</groupId>
<artifactId>j2cache-core</artifactId>
<version>2.7.8-release</version>
</dependency>在配置文件中配置好对应的 缓存
#########################################
# Cache Broadcast Method
# values:
# jgroups -> use jgroups's multicast
# redis -> use redis publish/subscribe mechanism (using jedis)
# lettuce -> use redis publish/subscribe mechanism (using lettuce, Recommend)
# rabbitmq -> use RabbitMQ publisher/consumer mechanism
# rocketmq -> use RocketMQ publisher/consumer mechanism
# none -> don't notify the other nodes in cluster
# xx.xxxx.xxxx.Xxxxx your own cache broadcast policy classname that implement net.oschina.j2cache.cluster.ClusterPolicy
#########################################
j2cache.broadcast = redis
#########################################
# Level 1&2 provider
# values:
# none -> disable this level cache
# ehcache -> use ehcache2 as level 1 cache
# ehcache3 -> use ehcache3 as level 1 cache
# caffeine -> use caffeine as level 1 cache(only in memory)
# redis -> use redis as level 2 cache (using jedis)
# lettuce -> use redis as level 2 cache (using lettuce)
# readonly-redis -> use redis as level 2 cache ,but never write data to it. if use this provider, you must uncomment `j2cache.L2.config_section` to make the redis configurations available.
# memcached -> use memcached as level 2 cache (xmemcached),
# [classname] -> use custom provider
#########################################
j2cache.L1.provider_class = caffeine
j2cache.L2.provider_class = redis
# When L2 provider isn't `redis`, using `L2.config_section = redis` to read redis configurations
# j2cache.L2.config_section = redis
# Enable/Disable ttl in redis cache data (if disabled, the object in redis will never expire, default:true)
# NOTICE: redis hash mode (redis.storage = hash) do not support this feature)
j2cache.sync_ttl_to_redis = true
# Whether to cache null objects by default (default false)
j2cache.default_cache_null_object = true
#########################################
# Cache Serialization Provider
# values:
# fst -> using fast-serialization (recommend)
# kyro -> using kyro serialization
# json -> using fst's json serialization (testing)
# fastjson -> using fastjson serialization (embed non-static class not support)
# java -> java standard
# [classname implements Serializer]
#########################################
j2cache.serialization = json还有些配置,要参考着j2cache的官方文档
以及代码中使用
public static void main(String[] args) throws IOException {
CacheChannel cache = J2Cache.getChannel();
// cache1表示region,region表示定义了缓存大小和过期时间的分组
cache.set("myRegion","key","cacheValue");
CacheObject cacheObj = cache.get("myRegion","key");
System.out.println(cacheObj.getValue());
cache.get("myRegion","key");
}在源码中表示
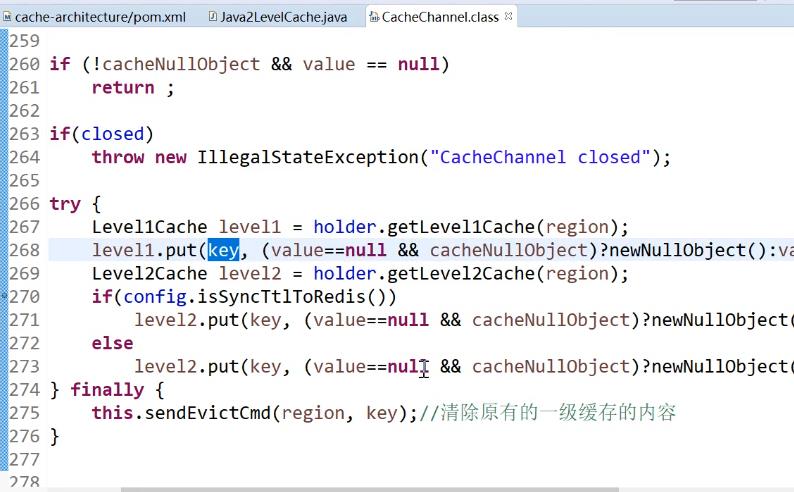
然后使用过后,当它是一个缓存使用。
以及包括常见遇见的一些问题
-
J2Cache 的使用场景是什么?
首先你的应用是运行在集群环境,使用 J2Cache 可以有效降低节点间的数据传输量;其次单节点使用 J2Cache 可以避免应用重启后对后端业务系统的冲击 -
为什么不能在程序中设置缓存的有效期
在程序中定义缓存数据的有效期会导致缓存不可控,一旦数据出问题无从查起,因此 J2Cache 的所有缓存的有效期都必须在一级缓存的配置中预设好再使用 -
如何使用 JGroups 组播方式(无法在云主机中使用)
首先修改j2cache.properties中的j2cache.broadcast值为jgroups,然后在 maven 中引入<dependency> <groupId>org.jgroups</groupId> <artifactId>jgroups</artifactId> <version>3.6.13.Final</version> </dependency> -
如何使用 ehcache 作为一级缓存
首先修改j2cache.properties中的j2cache.L1.provider_class为 ehcache 或者 ehcache3,然后拷贝 ehcache.xml 或者 ehcache3.xml 到类路径,并配置好缓存,需要在项目中引入对 ehcache 的支持:<dependency><!-- Ehcache 2.x //--> <groupId>net.sf.ehcache</groupId> <artifactId>ehcache</artifactId> <version>2.10.4</version> </dependency> <dependency><!-- Ehcache 3.x //--> <groupId>org.ehcache</groupId> <artifactId>ehcache</artifactId> <version>3.4.0</version> </dependency>spring cache 和 j2cache 继承示例代码,spring 配置类
/**
* @author Chen
*/
@Configuration
@EnableCaching
public class MyCacheConfig extends CachingConfigurerSupport {
@Override
public CacheManager cacheManager() {
// 引入配置
J2CacheConfig config = J2CacheConfig.initFromConfig("/j2cache.properties");
// 生成 J2CacheBuilder
J2CacheBuilder j2CacheBuilder = J2CacheBuilder.init(config);
// 构建适配器
J2CacheSpringCacheManageAdapter j2CacheSpringCacheManageAdapter = new J2CacheSpringCacheManageAdapter(j2CacheBuilder, true);
return j2CacheSpringCacheManageAdapter;
}
}高并发系统缓存架构方案

包括代理层、应用层、数据库层、几层进行拆分开 每层都有一个缓存起来。
数据库缓存
在mysql官方文档中 MySQL :: MySQL Documentation
有部分是对缓存做描述的,包括怎么开启缓存,验证有没有缓存。
直接使用 query_cache去查询缓存
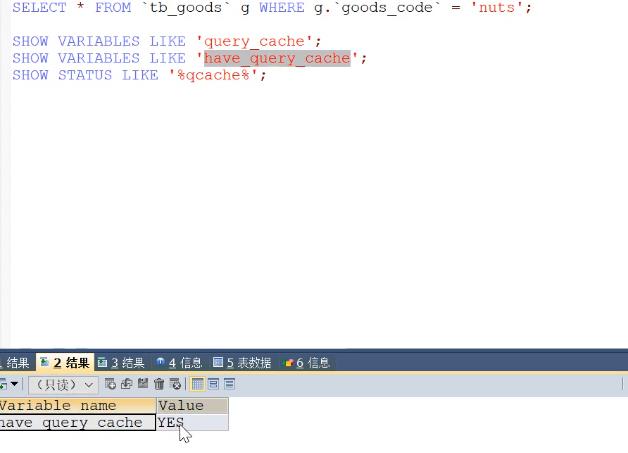
缓存使用 key -vlaue
缓存性能指标:命中率
维护成本:数据库成本高
不建议使用,在mysql8.0就删除了
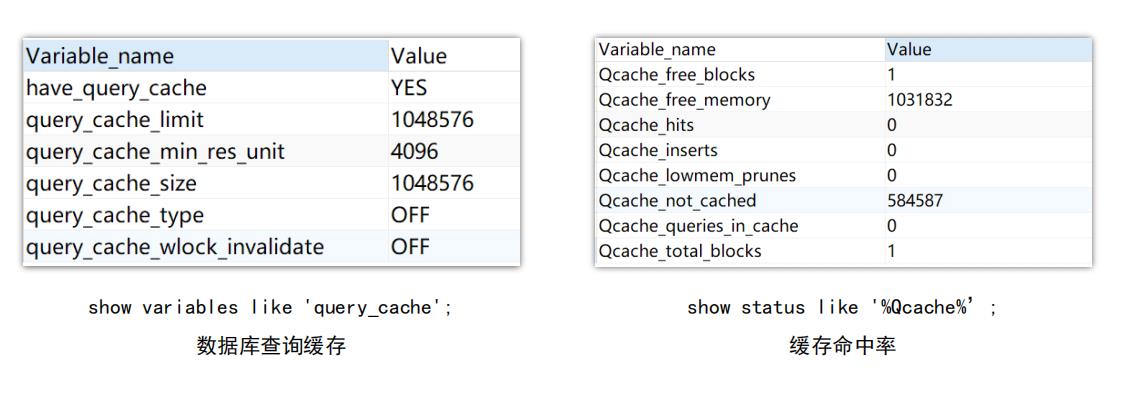
应用层数据缓存
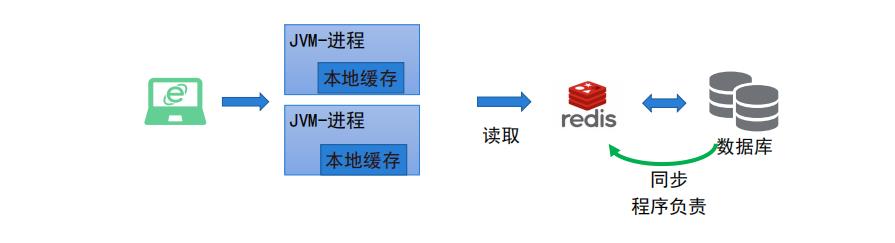
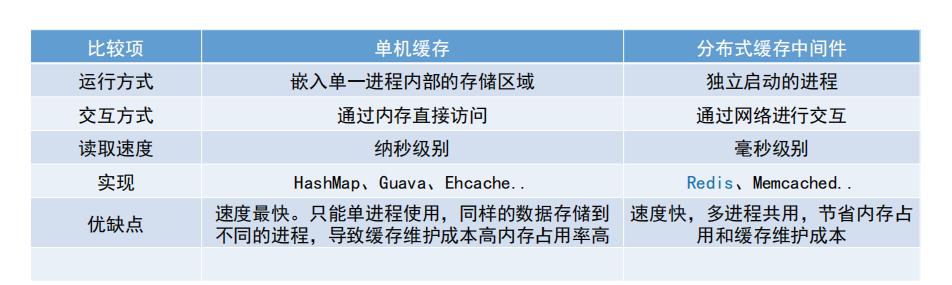
代理服务器缓存
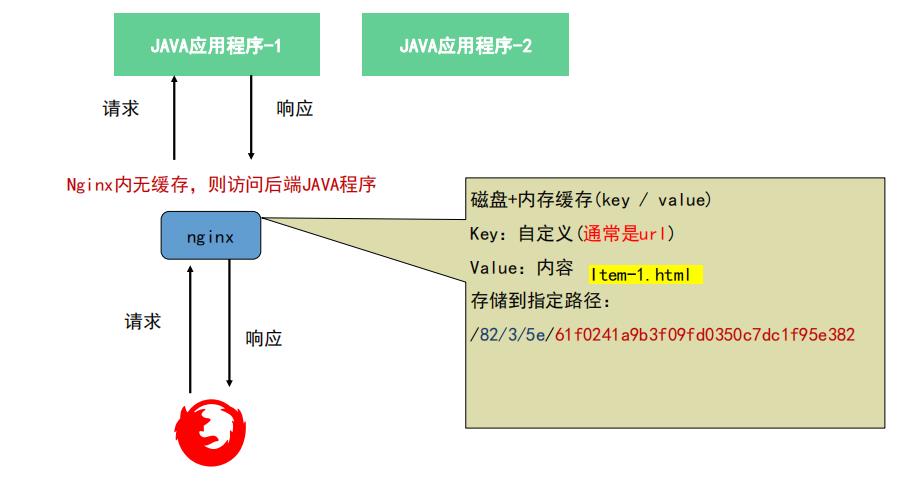
通过lua脚本直接去访问redis ,代理层面去。
以上是关于缓存架构中分布式一致性hash应用解析的主要内容,如果未能解决你的问题,请参考以下文章