Mysql高级调优篇——前言简介
Posted 风清扬逍遥子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mysql高级调优篇——前言简介相关的知识,希望对你有一定的参考价值。
本篇开始就进入Mysql高级篇,当然我讲解的身份是Java开发工程师,并非专业的DBA,所以我们以写出高效,好用,Sql优化和开发相关的数据库方面的知识落地为目的,帮助开发解决一些sql上的问题,为迈向高级工程师而更近一步,增删查改方面的知识我不再赘述,如果有基础薄弱的同学,可以好好的补一补再来看。
1、mysql 逻辑架构简介
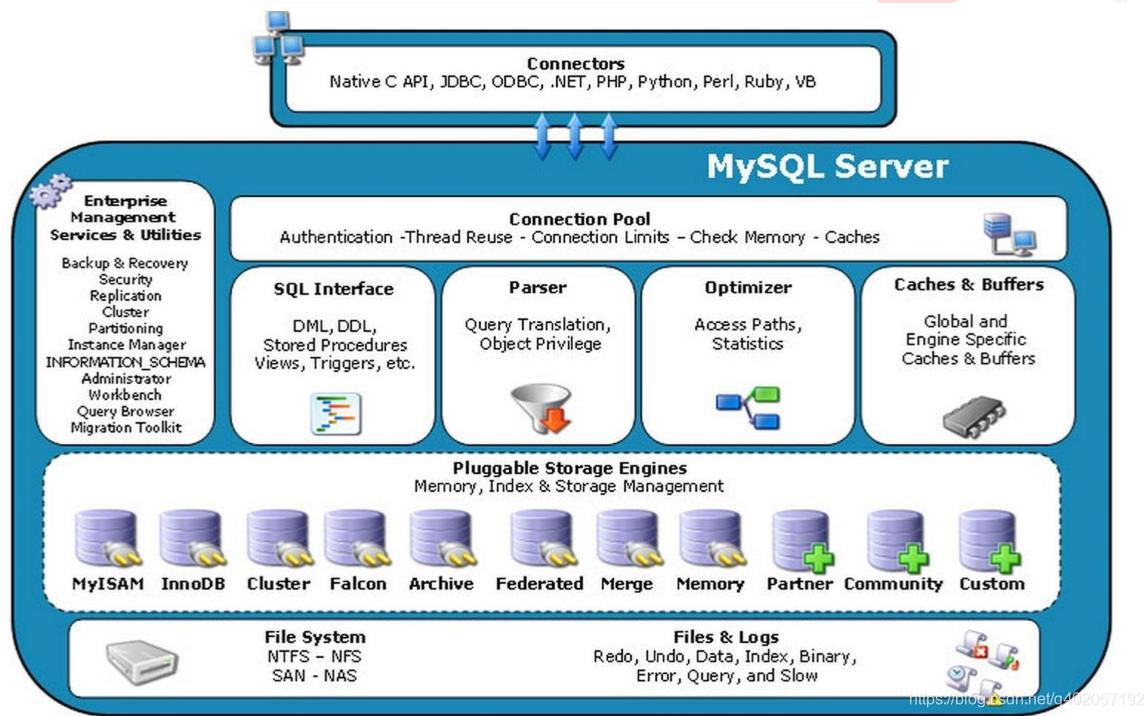
整体架构图
类比我们Java开发中,Controller,Service,Dao层,隔离开每个层负责不同的业务,Mysql也是一样,和其它数据库相比,MySQL 有点与众不同,它的架构可以在多种不同场景中应用并发挥良好作用。
主要体现在存储引擎的架构上,插件式的存储引擎架构将查询处理和其它的系统任务以及数据的存储提取相分离。这种架构可以根据业务的需求和实际需要选择合适的存储引擎。
自上而下:
- 连接层
最上层是一些客户端和连接服务,比如JDBC,ODBC,包含本地 sock 通信和大多数基于客户端/服务端工具实现的类似于 tcp/ip 的通信。主要完成一些类似于连接处理、授权认证、及相关的安全方案。在该层上引入了线程池的概念,为通过认证安全接入的客户端提供线程。同样在该层上可以实现基于 SSL 的安全链接。服务器也会为安全接入的每个客户端验 证它所具有的操作权限。
- 服务层
实际上我想重点说的是Optimizer查询优化器,我们都知道Mysql在解析sql的时候,是由一定的顺序开始的,那么当你写的sql你可能是这么理解的,但是mysql会帮你把这个优化成一个Mysql自己理解,最优的方式去运行你的sql,有可能Mysql没有走到开发或者DBA认为的最优上,就需要加一些强制索引,在极端的业务下,阿里狠到把这个Optimizer给“拔掉”了,自己改了优化器,Mysql只管按照我说的执行就行了,不需要你认为的最优化,可想而知这些人多变态~
后面讲到调优的时候重点说。
Management Serveices & Utilities 系统管理和控制工具 SQL Interface SQL 接口。接受用户的 SQL 命令,并且返回用户需要查询的结果。比如 select from 就是调用 SQL Interface Parser 解析器。 SQL 命令传递到解析器的时候会被解析器验证和解析 Optimizer 查询优化器。 SQL 语句在查询之前会使用查询优化器对查询进行优化,比如有 where 条件时,优化器来决定先投影还是先过滤。 Cache 和 Buffer 查询缓存。如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据。这个缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存,key 缓存, 权限缓存等
- 引擎层
可插拔存储引擎层,存储引擎真正的负责了 MySQL 中数据的存储和提取,服务器通过 API 与存储引擎进行通信。支持不同的存储引擎具有的功能不同,这样我们可以根据自己的实际需要进行选取。绝大多数互联网公司,用的都是MyISAM和InnoDB,其他的引擎根据特定的业务需要进行选取插拔,上次就见人吹牛逼说十几种都用过的。
- 存储层
数据存储层,主要是将数据存储在运行于裸设备的文件系统之上,并完成与存储引擎的交互。
2、Mysql存储引擎
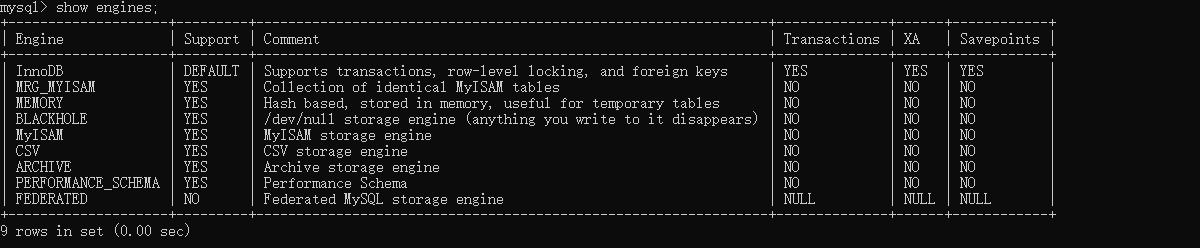
我们可以看下当前Mysql提供的存储引擎:
> show engines;
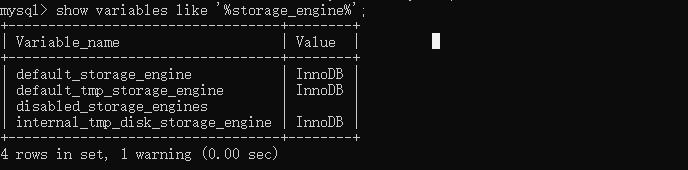
还可以看下Mysql当前默认使用的存储引擎:
> show variables like '%storage_engine%';
很明显上面我们默认都是InnoDB引擎;
那么MyISAM和InnoDB有哪些明显的区别呢?
对比项 MyISAM InnoDB 主外键 不支持 支持 事务 不支持 支持 行表锁 表锁,即使操作一条记录也会锁住整个表,不适合高并发的操作 行锁,操作的时候只锁某一行,不对其他行有影响,适合高并发操作 缓存 只缓存索引,不缓存真实数据 不仅缓存索引,还缓存真实数据,对内存要求较高,而且内存大小对性能有决定性影响 表空间 小 大 关注点 性能 事务 默认安装 是 是 阿里爸爸,淘宝用的什么?
Percona为Mysql数据库服务器进行了改造,在功能和性能上有较大的提升,该版本提升了在高负载情况下的InnoDB性能,为DBA提供一些非常有用的性能诊断工具,另外有更多的服务器参数和命令控制服务器行为。
该公司新建了一款存储引擎叫做xtradb完全可以替代InnoDB,并且在性能上和并发上做的更好,阿里爸爸大部分的Mysql数据库其实使用的Percona的原型上加以修改,形成了AliSql和AliRedis。
3、Sql性能下降的原因
很多时候我们会在面试中,工作中会问到你如何进行JVM调优的,有哪些调优手段,排查手段,问题现象等等,是不是说我们一上来看到Sql慢,就直接干优化?肯定不是,这些慢的因素,不一定是sql本身导致的,有可能是外界因素,比如服务器资源不够,运维把数据库的缓存buffer配置的低,或者这个问题是不是稳定复现的?如果是偶发的,具体要看服务器的情况,或者数据库性能日志等等。也有可能需要观察一段时间,缩减确定问题产生的范围再去定位问题所在;这个在优化前,是必须要做到的。
常见的几个点:
- 查询语句写的太烂了
- 索引失效
- 关联查询太多join(涉及缺陷或者不得已的需求)
- 服务器调优和各个参数的配置(缓冲,线程数等)
查询语句写的烂,通常表现在嵌入很多子查询,各种连接等,没建索引或者不走索引跑的奇慢无比;
索引失效,通常表现在建立了,没用上,索引分为单值索引和复合索引和唯一索引,所谓单值索引指的是一个索引有且只包含一个列,一个表中可以有多个单列索引。复合索引是指索引能够同时覆盖多个数据列;唯一索引是指索引列的值必须唯一,但可以为null。
关联查询太多join,比如什么统计分析的场景,一下关联七八张表,join越多,效率越低;join越少越好。
服务器调优一般是运维做的事情,开发只需要了解一些配置就可以,这个后面会提及。
4、Sql执行顺序
开发写的,和Mysql读取加载并理解的Sql是不一样的:
开发写sql是这么来写的:
select id, count(*) from user group by id ...
但是Mysql是拿到这条语句是怎么在执行引擎中执行的呢?
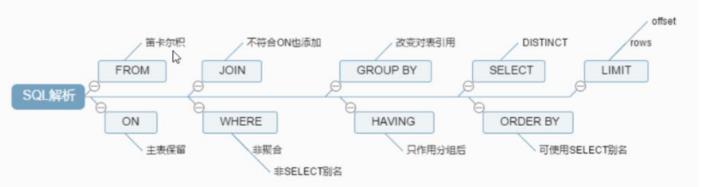
看这个图:先识别From后面的表,然后再进行join和on的运算,判断条件后得出结果,对结果进行分组,如果有Having的语句会被执行,最后进行选择列进行筛选,排序,按照limit限制的条数推送结果。
整个Sql解析的过程是这样的:
所以我们进行总结下:
mysql 的查询流程大致是: mysql 客户端通过协议与 mysql 服务器建连接,发送查询语句,先检查查询缓存,如果命中,直接返回结果, 否则进行语句解析,也就是说,在解析查询之前,服务器会先访问查询缓存(query cache)——它存储 SELECT 语句以及相应的查询结果集。如果某个查询结果已经位于缓存中,服务器就不会再对查询进行解析、优化、以及执行。它仅仅将缓存中的结果返回给用户即可,这将大大提高系统的性能。
语法解析器和预处理:首先 mysql 通过关键字将 SQL 语句进行解析,并生成一颗对应的“解析树”。mysql 解析器将使用 mysql 语法规则验证和解析查询;预处理器则根据一些 mysql 规则进一步检查解析数是否合法。 查询优化器当解析树被认为是合法的了,并且由优化器将其转化成执行计划。一条查询可以有很多种执行方式, 最后都返回相同的结果。优化器的作用就是找到这其中最好的执行计划。 mysql 默认使用的 BTREE 索引,并且一个大致方向是:无论怎么折腾 sql,至少在目前来说,mysql 最多只用到表中的一个索引。
那么前言就先介绍到这,下一章正式进入Sql分析和调优!!


以上是关于Mysql高级调优篇——前言简介的主要内容,如果未能解决你的问题,请参考以下文章