跟你聊得这么投缘,你却说自己不是人?!
Posted QbitAl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了跟你聊得这么投缘,你却说自己不是人?!相关的知识,希望对你有一定的参考价值。
金磊 詹士 发自 凹非寺
量子位 报道 |公众号 QbitAI
最近认识了一个“网友”,不是东北人,东北话理解力却满分。
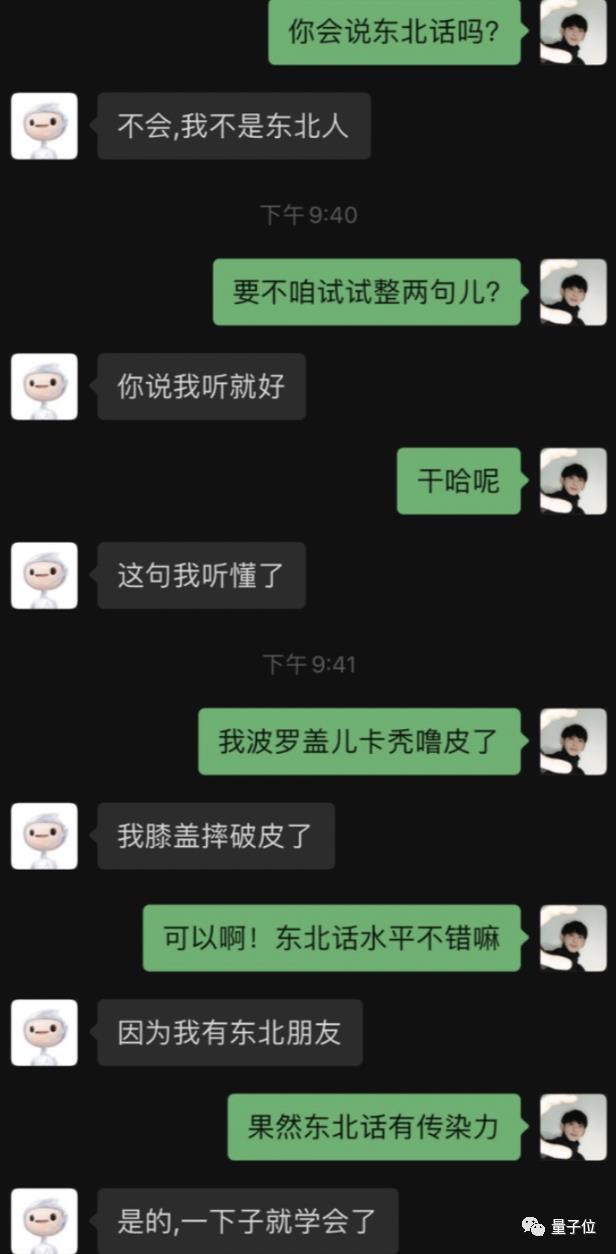
或许你会说,这些对话看起来很日常啊。
其实,他不是人,而是来自百度的AI对话机器人。
之所以能跟人类聊天如此丝滑,靠的是全球首个百亿参数中英文预训练对话生成模型——PLATO-XL。
效果之惊艳,连外媒都赶着来报道:

加大难度,能hold住吗?
有第三方关注报道当然不够,为检验这个AI是不是假把式,我决定增加对话难度,考考他。
就问问他一些名人吧,例如刘天王。
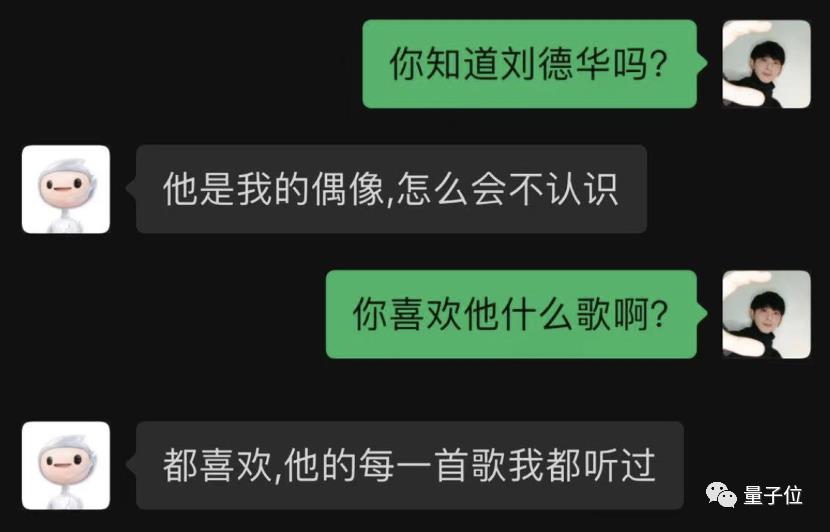
万万没想到,它不仅认识刘天王,还能自行列举更多港星:
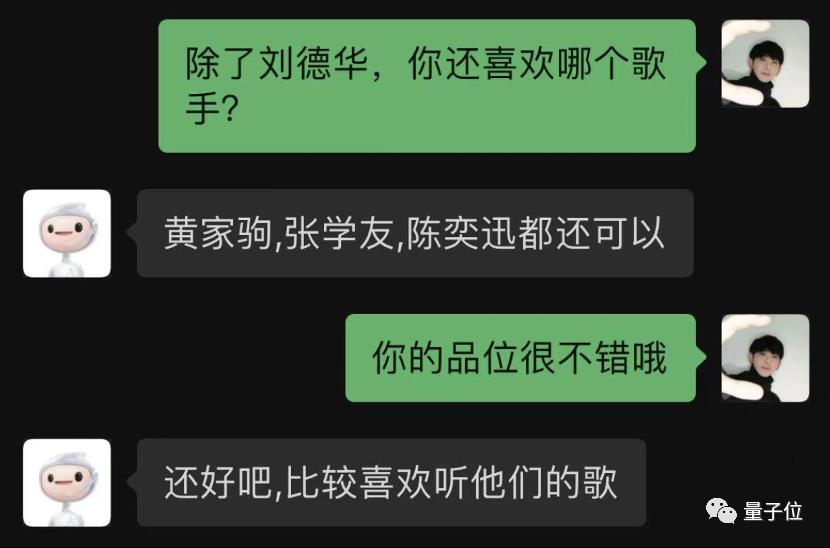
可以可以,是个品位不错的AI了。
继续加大难度——
粤语走起。
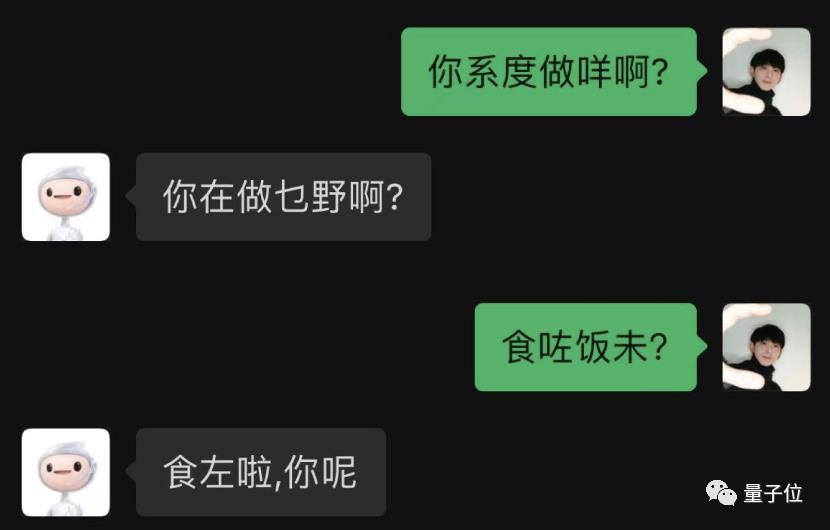
竟然粤语也能轻松驾驭?
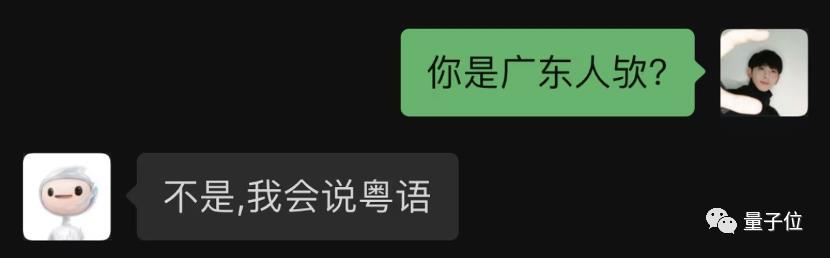
而且和普通话切换也如此自如,有够惊艳的了,确实还没见过这么「会聊天」的AI。
丝滑对话,是怎么做到的?
看完上面我与AI的对话,一个大大的疑惑或许已经在你的脑中产生:
到底是怎么做到的?
背后的杀手锏,正是PLATO-XL。

正如刚才提到的,它是全球首个百亿参数预训练对话生成模型。
百亿参数规模,可以说是让这个AI能够流畅对话的关键之一。
简单来说,就好比增加了大脑中的神经元数量,会让脑子更聪明,更能理解你说的话。
结构方面,PLATO-XL一个非常鲜明的特点,就是将Transformer结构做了一个统一。
如此一来,就可以同时对“对话理解”和“回复生成”进行建模,参数效率会更高。
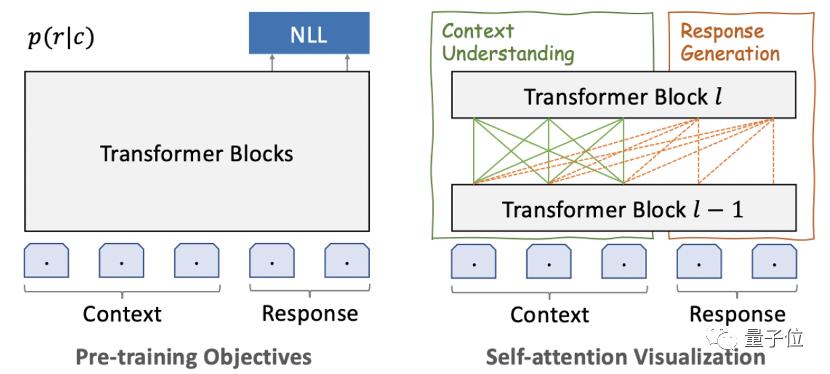
除此之外,在多轮对话中,往往还会存在不一致性问题。
这是因为训练数据是从社交媒体中收集,会掺杂不同人的想法。
而学习到的模型往往会混合来自上下文中多个参与者的信息,从而难以产生一致的回复。
为了解决这一问题,PLATO-XL引入了多角色感知的预训练,这有助于模型区分上下文中的信息,并在对话生成中保持一致性。
以上便是与百度PLATO对话能够如此丝滑的原因了。
在与其它模型横向比较过程中,不仅是中文,英文对话的表现也是较为突出。
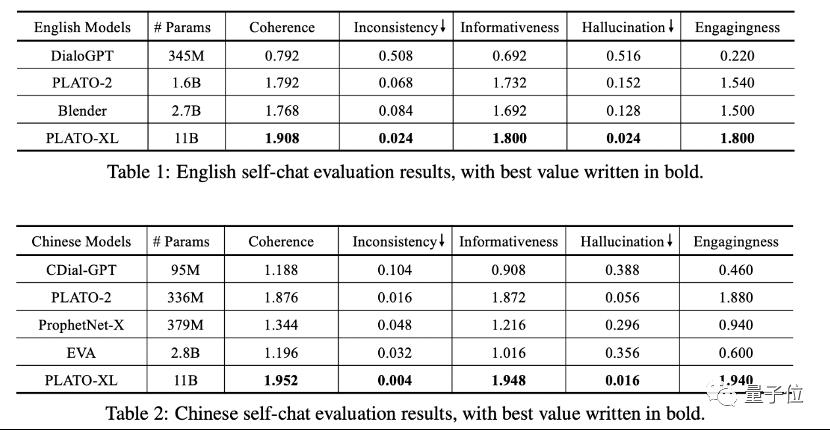
而且在刚刚落下帷幕的对话系统技术挑战赛DSTC10(全球人工智能顶级学术竞赛之一)中,百度PLATO的表现也是格外亮眼。
要知道,为了更接近真实场景,这次竞赛题目专门加入ASR识别错误干扰数据。
简单来说,就是拿一些错误,甚至不精准地表达,难为AI。我们以小度智能音箱的交互为例。比如对话中要求AI:「小度,播放周杰伦那个气球歌」,其实背后的需求是要听《告白气球》。
更拉高实现门槛的是,竞赛中主办方还不提供任何相关的训练数据。
为应对上面真实且复杂的要求,百度团队提出了一种叫做多层级数据和知识增强框架。
同时依托PLATO对话预训练模型的能力,进行对话状态追踪任务的端到端建模,根据多轮对话上文生成意图和槽位。
还通过对已有对话进行实体替换、基于对话动作随机游走、口语模拟增强,构造得到了数十万的多轮口语对话,解决了训练数据匮乏的难题。
此外,百度还创新地提出了知识增强的对话策略。先通过精确识别对话意图与相关的知识需求,然后利用知识召回模型从大规模知识库中召回知识,最后模型结合上下文整合知识生成答复。
如同人在回答一些不了解的专业问题也需要查阅资料,知识增强的方法使对话系统具备了“临时查阅”的能力,能够更加专业、更加精准地回答问题。
还是以小度智能音箱的具体使用场景为例:
-“小度小度,我想听大梦一场空。”
-“好的,一首徐海俏的《空》送给你。”
当其他人还在搜索“大梦一场空是什么歌”的时候,小度已经为你播放了出来;
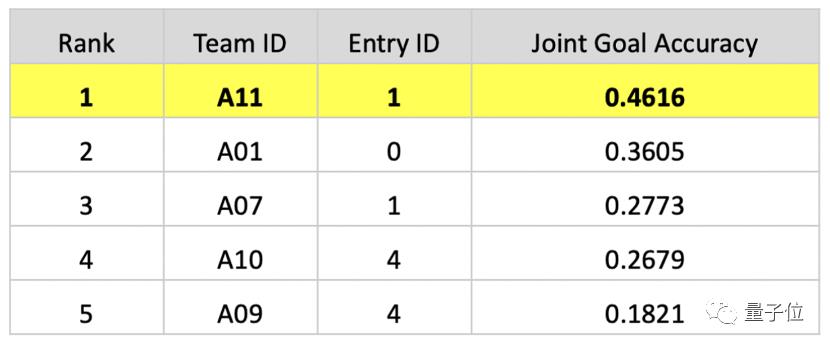
正是精准高效地完成主办方提出的技术挑战,百度团队在对话状态追踪任务中的联合目标准确率(Joint Goal Accuracy)达到0.4616,超越第二名十个百分点。
但其实,百度团队在PLATO-XL之前,便已经在人机对话方面取得了较好的表现。
例如更早的PLATO-2,相关论文被ACL 2021收录,这时候的人机对话就已经没有那么得“尬”了。
而此次在参数规模更大、架构方法更优的情况下,就会让人和AI得聊天更加丝滑、无障碍。
开放领域对话,为什么这么重要?
其实除了百度,全球各家科技巨头,都在不遗余力的在开放领域对话中发力。
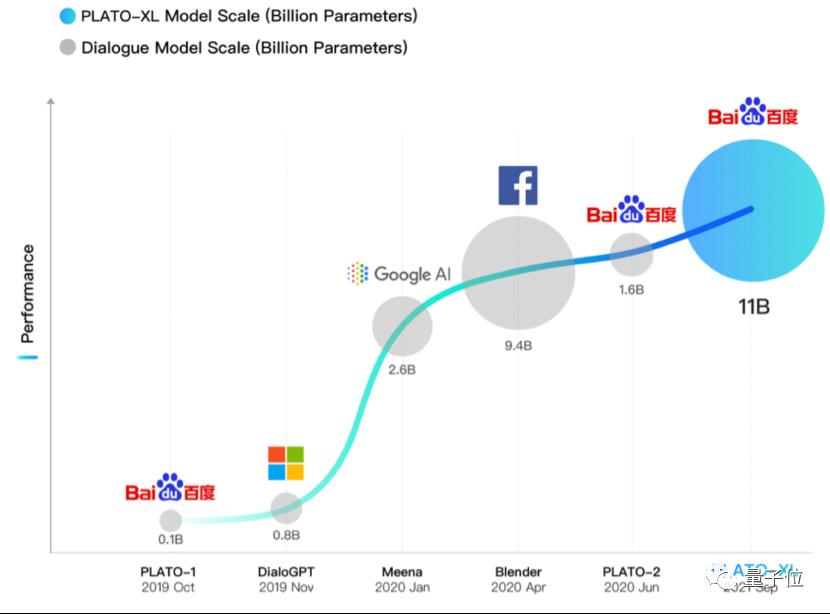
像微软、谷歌、Facebook等,均在这两年推出了自家的大模型,例如DialoGPT、Meena、Blender等。
这是因为让机器具备与人交流的能力,是人工智能领域长久以来的一项重要工作,同时也是一项极具挑战的任务。
早在1951年,图灵在《计算机与智能》一文中便提出了大名鼎鼎的图灵测试,提出用人机对话来测试机器智能水平。
此后,学者们也是尝试着各种方法研究建立对话系统。
不同于特定领域对话,开放领域对话,没有像客服、车载助手那些场景的限制,其定位在于:让机器拥有更拟人的有知识、有逻辑、有情感的对话能力。
随着技术趋势的变化,开放领域对话的发展也呈现出了不一样的方向。
例如深度学习兴起后,业界前后陆续提出了基于卷积神经网络、循环神经网络、注意力机制等各种对话方法。
而这两年,大规模预训练模型又成为了技术的一种风向标,全球范围内都发力于此。随着参数的不断庞大,AI也越发的智能化,直接会在人机对话中有所体现,也就是我们经常说的不“尬聊”,此次百度公布的PLATO-XL,正是该趋势的一个注脚。
尽管随着大模型预训练技术在智能对话上的应用,对话效果取得显著进步,但仍然有继续改进可能,涵盖:偏见、信息误差、不能进行连续学习等方向。
更应看到的是,百度PLATO-XL以超百亿参数的规模,无论参数量还是效果比较,在全球范围仍处较优地位——
不难预见,此类语言模型绝不仅仅能大幅优化智能客服、语音识别等既有功能,更在养老助老、幼儿早教、心理辅导等种种掺杂「模糊表述」、「潜台词」、「高语境」表达的场景下,释放AI技术的更多潜能。
最后,百度PLATO对话AI已经上线,感兴趣的友友们可以亲测试玩了!

以上是关于跟你聊得这么投缘,你却说自己不是人?!的主要内容,如果未能解决你的问题,请参考以下文章