如何进行流批一体架构设计
Posted 咬定青松
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何进行流批一体架构设计相关的知识,希望对你有一定的参考价值。
1. “假如你是一个头脑封闭的人,又在自己有盲点的领域形成了一种观点,结果可能是致命的。所以,花点时间记录一下,你经常在哪些方面因为看不到别人看到的东西而做出糟糕的决策。可以请其他人帮你,尤其是那些曾看到你所忽略的东西的人。列一张单子,钉在墙上,仔细盯着看。每当你准备在这些方面自行做出决定(尤其是重大决定)的时候,你都要明白你是在大冒险,不会实现想要的结果。”
2. “你的生活质量终究取决于你的决策质量。而且,既然工作占据了生活的一大部分,你需要确保你的工作时间管理与你的目标相一致。对你来说,什么事情是很重要的?参与有成就感的任务?赚钱?生活稳定?还是刺激和未知性?你的答案或许会随时间推移而改变,但不变的是,你需要回答这些问题,并设想不同的机会,考虑哪一条道路符合你想要的生活类型。例如,假设你正在考虑换工作或者自己创业。那么,你需要想象每一条道路会通往怎么样的生活,以及这些道路是否适合你去走。同时,你一定要和在每条道路上取得成功或失败的人去探讨和审视你的选择。 ”
3. “你几乎不可能每个步骤都擅长,因为每一步都要求不同类型的思维,而几乎没有人能擅长所有这些思维。例如,设定目标(如确定你希望自己的生活是什么样子)需要你擅长更高层次的思考,如设想未来、优先排序;找出并且不容忍问题,需要你明察秋毫,擅长综合分析,始终保持高标准;诊断问题需要你理性思考,能够看到多种可能性,并愿意与其他人进行艰难的对话;规划方案需要有构想能力并且务实;执行方案需要你自律,有良好的工作习惯,拥有结果导向的思维。你认识的哪个人拥有所有上述特质?估计是没有的。但要实现真正的成功就必须很好地完成上述这五步。那么你应该怎么做?首要是谦逊,这样你就能从其他人那里得到你所需要的东西!每个人都有弱点。人们犯错误的规律通常能揭示他们的缺点在哪里。通往成功的第一步是知道你的弱点在哪里,并正视这些弱点。”
流计算和批计算是大数据从业者耳熟能详的概念,在这两个概念之前也有叫实时计算和离线计算,或许实时计算和离线计算的概念更能表达大家心智中指代的含义。但实时计算和离线计算没有具体的指标来界定多“实时”才算实时。按照粗放的惯例,计算频率基于T+1的都是离线、频率高于T+1的都叫实时,但是在某些行业,数据基本不怎么变化的,也许T+1的都能算实时,所以根据频率来界定两个概念没能反映其背后的本质。流计算和批计算相比实时计算和离线计算稍微进步了一些,但是在微观层面,批计算也是流计算,而且实时计算和离线计算只是从计算模型上来区分的,距离真正的内涵仍差一步之遥,所以在实践中才出现流计算与批计算的分离问题,并由此引出一系列问题,本文就是来探讨流和批及其融合的问题,首先来具体的阐述实时计算和离线计算的区别与联系。
流计算与批计算异同
1. 批计算基于静态数据,比如HDFS指定路径下的文件集合、加载到内存中的Dataset记录集合等,而流计算基于动态数据,比如服务器上实时产生的点击日志事件流,网络Socket实时传输的数据集合等,此时虽然两者都是数据集合,但明显区别是数据集合是否已经准备就绪。
2. 批计算的时效性较弱,可以按小时T+1、按日T+1、甚至可以按周和按年T+1,而流计算的时效性较强,通常以秒、分钟、小时为计算时间窗口。另外批计算通常提供精确计算,而流计算考虑到性能,可以提供近似计算。
3. 批计算的源数据是确定的,假设计算逻辑不发生变化,批计算如果失败,可以随时重跑,结果是一致的,因此可以溯源,是结果确定性的计算模式,而流计算不能随意重启,重启之后,源数据发生了变化,结果会随着时间和数据的不同而不同,因此不能溯源,是结果不确定性的计算模式。
4. 在存储介质和规模上,批计算主要依赖于磁盘存储而且数据规模更大,通常是以MB、GB、PB为单位,而流计算主要依赖于内存存储而且一次处理的数据规模明显小很多,通常以KB、MB为单位,GB也有,视存储空间大小而定。
5. 批计算通常对应有界数据源,尽管数据规模可以达到数PB,但是计算一旦开始,数据的边界是确定的。而流计算通常对应无界数据源,数据事件就像水流一样在时间的管道内源源不断地流入和流出。在响应模式上,批计算是stop-on-complete,流计算是run-forever,比如统计数据源中时间记录的总数量,批计算可以在一定时间范围内返回计算结果,而流计算则永远无法正常返回。
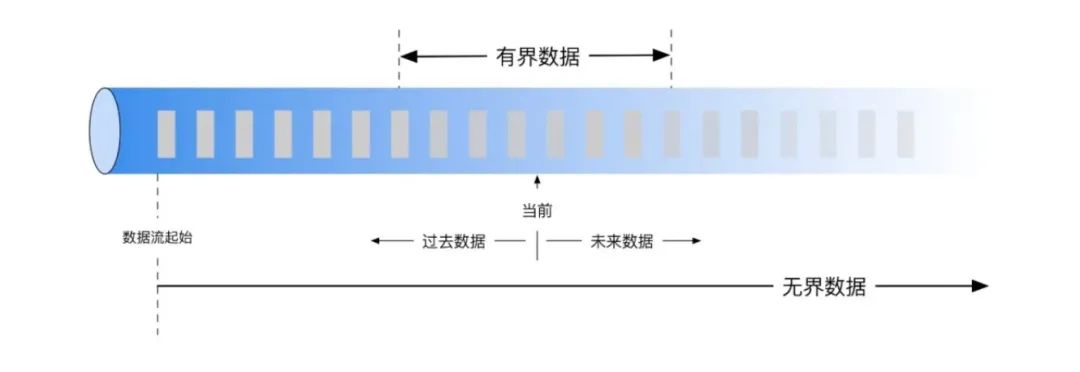
6. 批计算因为数据源有界,结果返回时间有限,所以在作业(Job)级别可以组成更大的依赖关系,如DAG,且每个节点任务类型可以不同,这就为复杂ETL计算提供了可能,而流计算因为数据无界,计算时间无限,所以流计算不能像批计算那样在作业完成的语义下建立依赖关系,只能通过增量“消费”建立依赖任务。
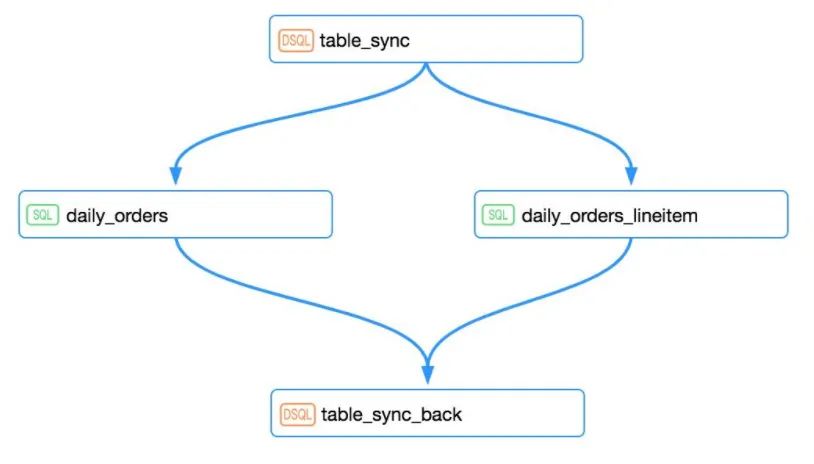
7. 理想中的流计算应该是像Storm那样,每个Event独立经过Topology处理并输出,但是因为考虑到性能和吞吐量,流计算往往先缓存一部分然后再提交输出,这导致的结果是流系统存在一定的时延,但同时为流批一体的实现提供了可能。因为对缓存的那部分数据来讲,相对于整个流管道来讲,相对静止,相当于是微观层面的一批数据(微批数据)。假设这个缓冲区可大可小,大可以达到批处理数据的规模,小可以达到毫秒级别时间范围的数据,那么常规的批计算可以看做流计算的一种特殊情况,这样一来,流计算中的若干微批数据就可以在算子(Operator)级别组成DAG,从这个意义上讲,流计算和批计算并没有实质性的差别。
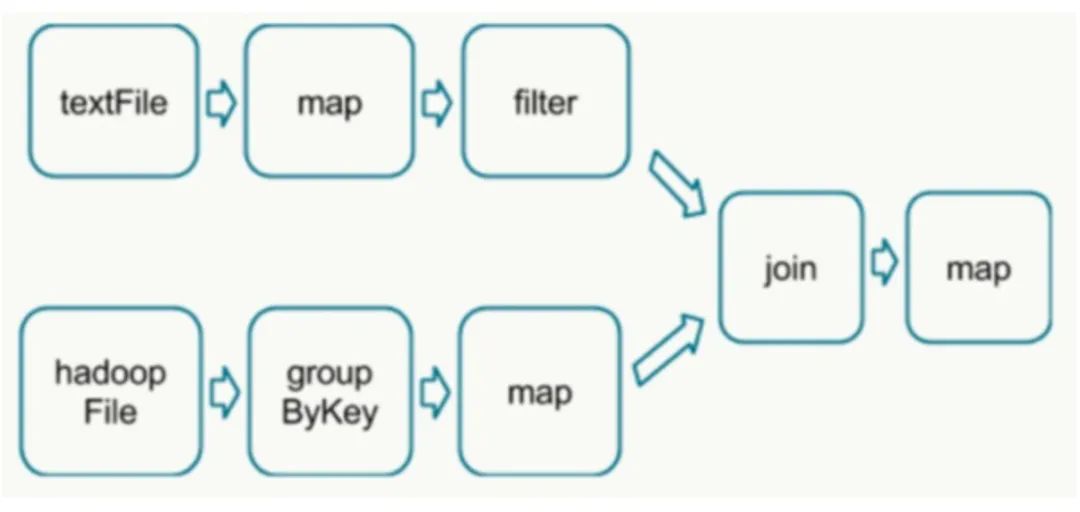
流计算与批计算融合需要解决的问题
尽管流计算和批计算本质上并无差异,但是在宏观上,两者面临的问题截然不同,可以说批计算的难度跟流计算完全不在一个量级。
1. 批计算并不关心作业处理过程中的处理状态,如果作业过程中发生异常(子任务重试仍然无效)干脆重启整个作业,对整个计算结果并无影响,(这指的是下图中红色计算单元,不包括上下游)批计算是确定性的计算。而流计算因为run-forever,不能像批计算说停就停,即使要停,也要保存停止之前的计算状态,包括算子状态、算子计算的中间结果数据,当任何一个算子级别的任何出现异常导致任务重启的时候不仅能够恢复原来的状态,还要保证数据不丢失、不重复计算,以保证重启能够断点续算,这对流计算本身就是个挑战!
2. 在任务和资源调度上,批计算的任务可以独立申请资源,而流计算一次性为所有任务申请资源,批计算执行的结果通常基于磁盘进行数据交换,而流计算通常可以将不同的任务以pipeline的形式串联执行,在内存交换数据,这种差异导致的结果是批计算一次性可以不需要大量资源,单个任务的失败不影响其他任务的执行,容错性较高,但磁盘IO较高;流计算因为一次性调度所有任务导致大规模计算场景下,资源消耗较高,pipeline上的一个任务失败,所有任务都会失败,容错性相对较低,但无磁盘 I/O。
3. 流计算跟时间是强相关的,比如在Flink的实现中,有三个时间概念:事件发生的时间Event Time、事件进入Flink系统的时间Ingestion Time、Flink处理算子(如窗口算子)开始处理事件的时间Processing Time。
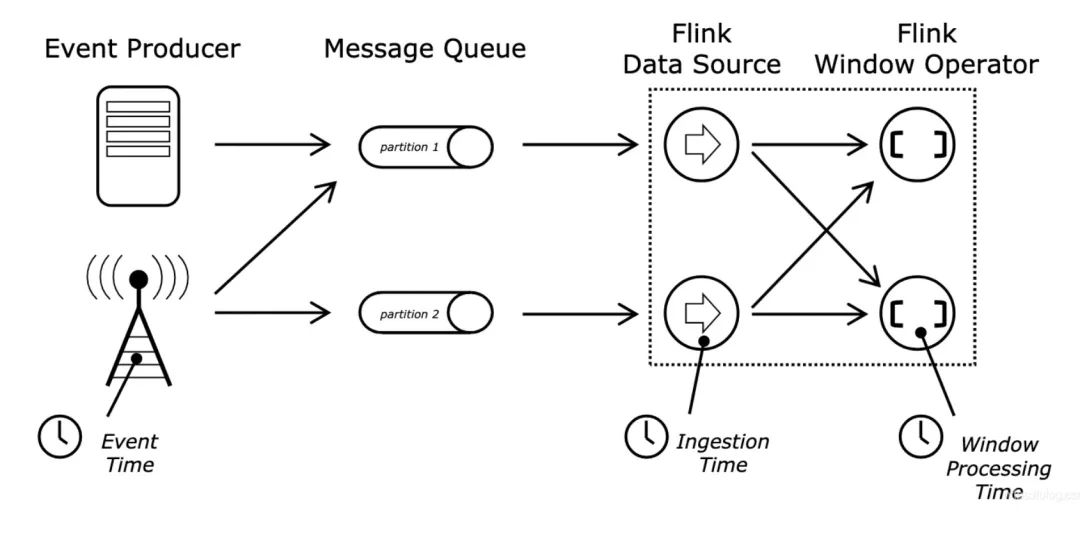
流计算首先要解决的问题是在哪里计算,也就是如何划分微批数据范围?Flink提供了三种类型的Window概念:Fixed Window、Slide Window和Session Window。其中Fixed Window、Slide Window有时间和记录数量两个维度,既可以按照记录数量划分窗口也可以按照时间范围划分窗口。
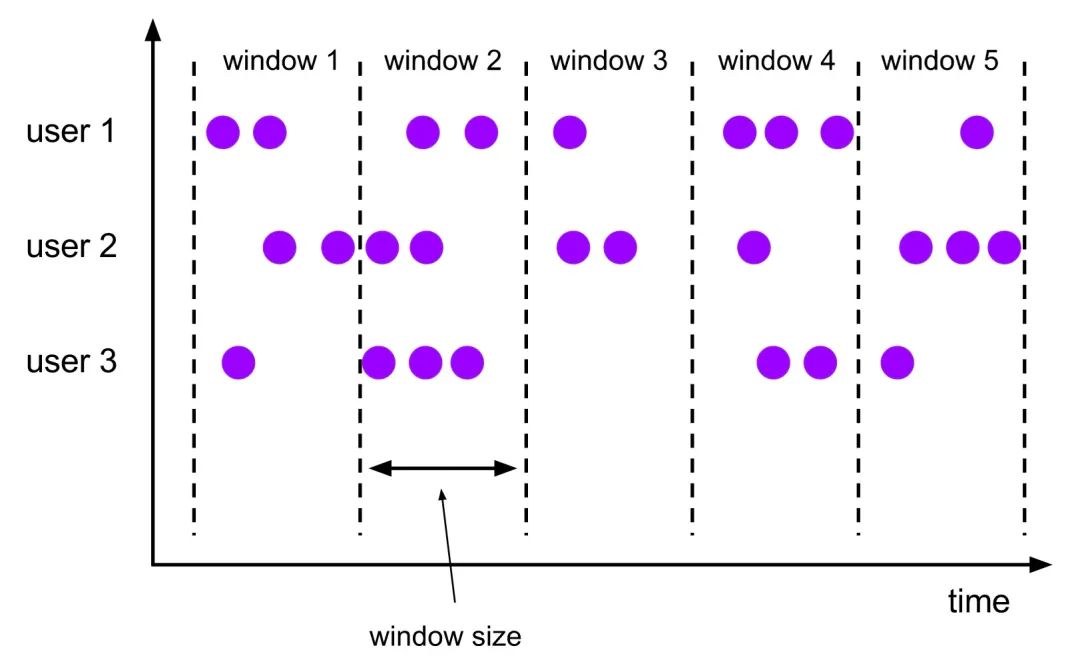
Fixed Window每个窗口size大小固定,比如每分钟创建新的窗口或者每10条数据组成一个窗口,每个窗口之间没有重叠。
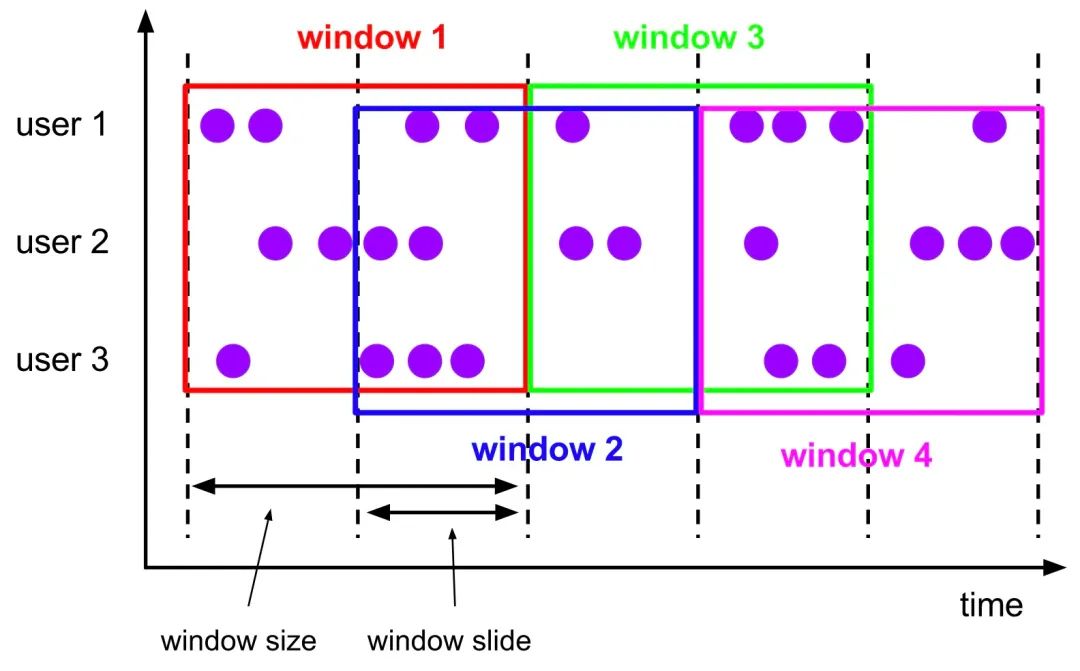
Slide跟Fixed Window类似,每个窗口size大小固定,比如每分钟创建新的窗口或者每10条数据组成一个窗口,但是每个窗口之间可以有重叠,重叠部分的数据同时存在两个相邻的窗口中, 重叠大小由滑动步长参数(0~size]来控制,当滑动步长参数为窗口大小时,就是Fixed Window。
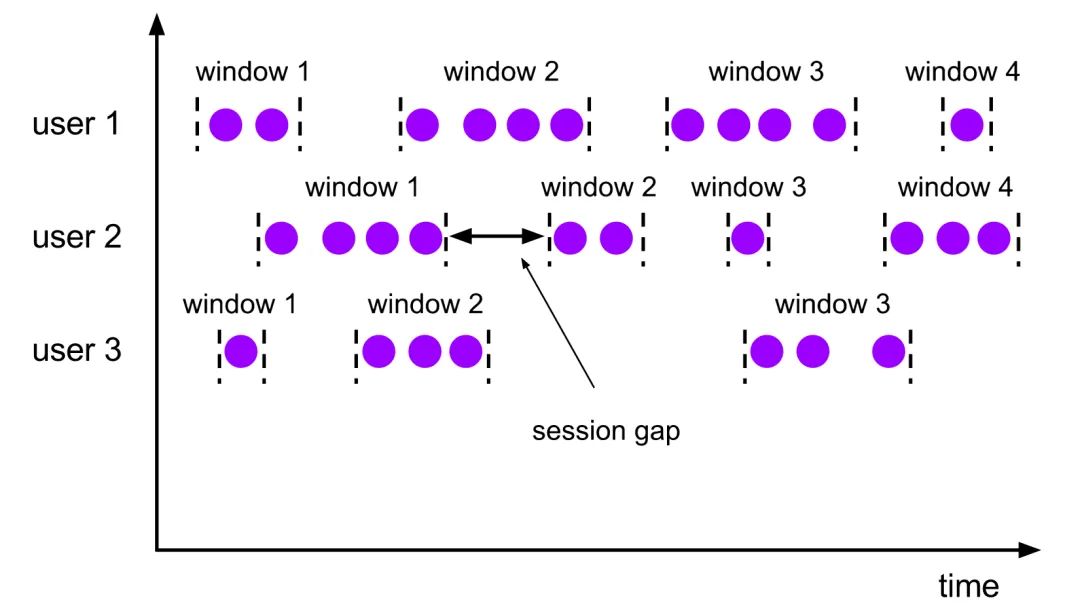
Session Window不同于Fixed Window和Slide Window,没有固定的大小和窗口边界,它代表的是连续会话活动的时长范围,相邻两个Session Window之间的空隙为session gap,这个值可以是固定的值,比如当一个会话窗口超过设定的时长没有新的事件进入,就关闭窗口,随后新来的事件划分到新的窗口,也可以实现自定义函数来定义不活动时长。
4. 窗口机制解决了批计算和流计算的数据划分问题:批计算因为数据已经就绪,可以按照Processing Time或者Event Time来划分,但是对于流计算因为数据没有就绪,存在数据乱序和延迟问题,这就涉及到何时触发窗口计算。在Flink中,触发器定义了Window何时会被计算或清除,每个Window都有一个属于自己的Trigger,Trigger上会有定时器,用来决定定义了Window何时会被计算或清除。当有元素进入窗口或者注册的定时器超时,Trigger会被触发,触发结果有以下几种:
CONTINUE:什么都不做
FIRE:触发计算,处理窗口数据。
PURGE:触发清理,移除窗口和窗口中的数据。
FIRE_AND_PURGE:触发计算和清理。处理数据并移除窗口和窗口中的数据。
当事件到来时,如果Trigger只是返回FIRE,则计算窗口并保留窗口原样,窗口数据不清理,数据保持不变,等待下次计算时候再次执行,直到触发结果清理,在此之前,窗口和数据一直占用内存不释放。
Flink Trigger定义了以下接口函数:

这些方法中的任何一种都可用于注册处理时间计时器或事件时间计时器以用于将来的操作。其中前面的三个方法都会产生一个TriggerResult来决定窗口接下来发生什么,TriggerResult返回值上面已经说明。TriggerResult可能的取值使得我们可以实现很复杂的窗口逻辑。一个自定义触发器可以触发多次,可以计算或者更新结果,可以在发送结果之前清空窗口。比如可以修改onElement,使其窗口的事件数量达到指定条数时触发计算,或者修改onEventTime逻辑,达到延迟触发,解决事件乱序和延迟的问题。
流批一体架构实践
Storm的作者Nathan Marz认为大数据系统应具有以下的关键特性:
Robust and fault-tolerant(容错性和鲁棒性):对大规模分布式系统来说,机器是不可靠的,可能会宕机,但是系统需要是健壮、行为正确的,即使是遇到机器错误。除了机器错误,人更可能会犯错误。在软件开发中难免会有一些Bug,系统必须对有Bug的程序写入的错误数据有足够的适应能力,所以比机器容错性更加重要的容错性是人为操作容错性。对于大规模的分布式系统来说,人和机器的错误每天都可能会发生,如何应对人和机器的错误,让系统能够从错误中快速恢复尤其重要。
Low latency reads and updates(低延时):很多应用对于读和写操作的延时要求非常高,要求对更新和查询的响应是低延时的。
Scalable(横向扩容):当数据量/负载增大时,可扩展性的系统通过增加更多的机器资源来维持性能。也就是常说的系统需要线性可扩展,通常采用scale out(通过增加机器的个数)而不是scale up(通过增强机器的性能)。
General(通用性):系统需要能够适应广泛的应用,包括金融领域、社交网络、电子商务数据分析等。
Extensible(可扩展):需要增加新功能、新特性时,可扩展的系统能以最小的开发代价来增加新功能。
Allows ad hoc queries(方便查询):数据中蕴含有价值,需要能够方便、快速的查询出所需要的数据。
Minimal maintenance(易于维护):系统要想做到易于维护,其关键是控制其复杂性,越是复杂的系统越容易出错、越难维护。
Debuggable(易调试):当出问题时,系统需要有足够的信息来调试错误,找到问题的根源。其关键是能够追根溯源到每个数据生成点。
对大数据系统来讲,最重要的两个方面是数据和其上的查询,对数据来讲因为其时间特性决定了其先后顺序,且只反映了既有事实,因此数据本身是不可变的(Immutability),通过追加的方式存储不仅可以避免数据更新带来的复杂性,而且基于不变数据的重算(Recomputation)能够保证确定性的结果。对查询来讲,要求数据具备一个重要特性-满足结合律(Monoid),如果不满足结合律,通过转化从而满足结合律也可以,比如平均值本身不能相加,但是可以先分别相加分子和分母,再计算平均值。满足结合律的数据意味着我们可以将计算分解到多台机器并行运算,然后再结合各自的部分运算结果得到最终结果,同时也意味着部分运算结果可以储存下来被别的运算共享利用(如果该运算也包含相同的部分子运算),从而减少重复运算的工作量。比如数据仓库的ER模型和维度建模的结果就可以被上层APP应用层共享。
Lambda架构就是Marz在多年分布式大数据系统的经验总结提炼而成的,其目标是设计出一个能满足实时大数据系统关键特性的架构,包括有:高容错、低延时和可扩展等。Lambda架构整合离线计算和实时计算,融合不可变性(Immunability),读写分离和复杂性隔离等一系列架构原则,可集成Hadoop,Kafka,Storm,Spark,Hbase等各类大数据组件。
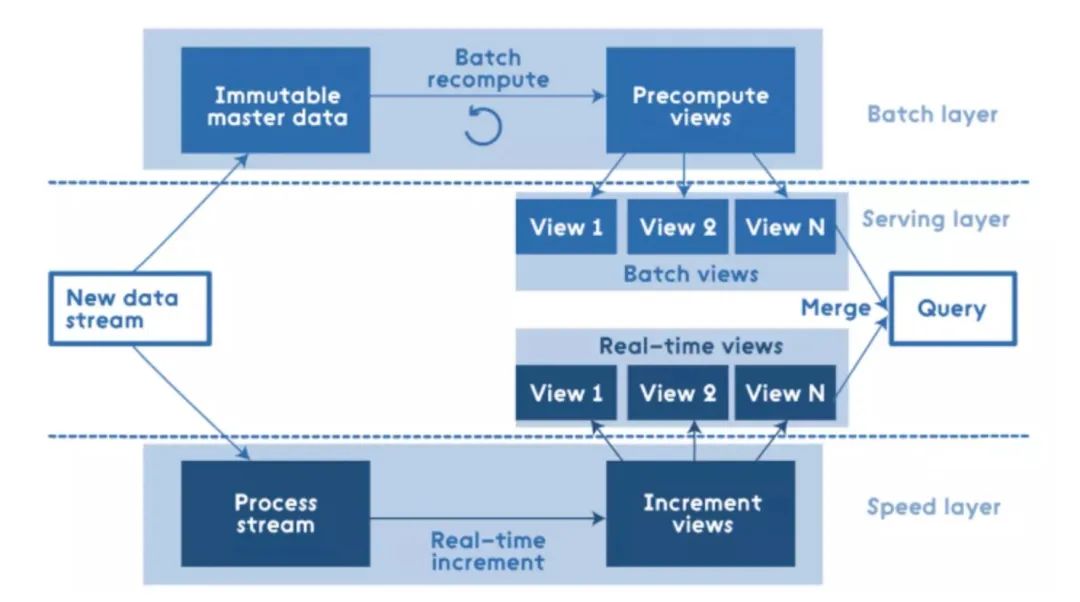
Lambda架构将整个数据源分为离线数据和实时数据,分别用Batch Layer层和Speed Layer层来处理,其中Batch Layer处理全体数据集,利用数据的不变性做重复计算和预结算,Speed Layer层处理的数据是最近的增量数据流,做实时计算甚至近似计算。在查询时候,将Batch Layer层和Speed Layer的结果合并返回。Lambda架构有如下优点:
容错性。Speed Layer中处理的数据也不断写入Batch Layer,当Batch Layer中重新计算的数据集包含Speed Layer处理的数据集后,当前的Realtime View就可以丢弃,这也就意味着Speed Layer处理中引入的错误,在Batch Layer重新计算时都可以得到修正。这点也可以看成是CAP理论中的最终一致性(Eventual Consistency)的体现。
复杂性隔离。Batch Layer处理的是离线数据,可以很好的掌控。Speed Layer采用增量算法处理实时数据,复杂性比Batch Layer要高很多。通过分开Batch Layer和Speed Layer,把复杂性隔离到Speed Layer,可以很好的提高整个系统的鲁棒性和可靠性。
Lambda因为其简单直接,支撑了大数据行业的早期发展,但是随着数据分析业务的多样性需求增加,该架构也越来越备受诟病,比如维护两套系统架构和逻辑,造成了运维的负担和统计口径的不一致,离线计算耗时太久,产生过多的中间结果占用大量的存储空间。于是,通过一套系统,一套逻辑解决流批一体计算的呼声越来越高。由 Jay Kreps 提出的Kappa 架构,不同于 Lambda 同时计算流计算和批计算并合并视图,Kappa 只会通过流计算一条的数据链路计算并产生视图。Kappa 同样采用了重新处理事件的原则,对于历史数据分析类的需求,Kappa 要求数据的长期存储能够以有序 log 流的方式重新流入流计算引擎,重新产生历史数据的视图。
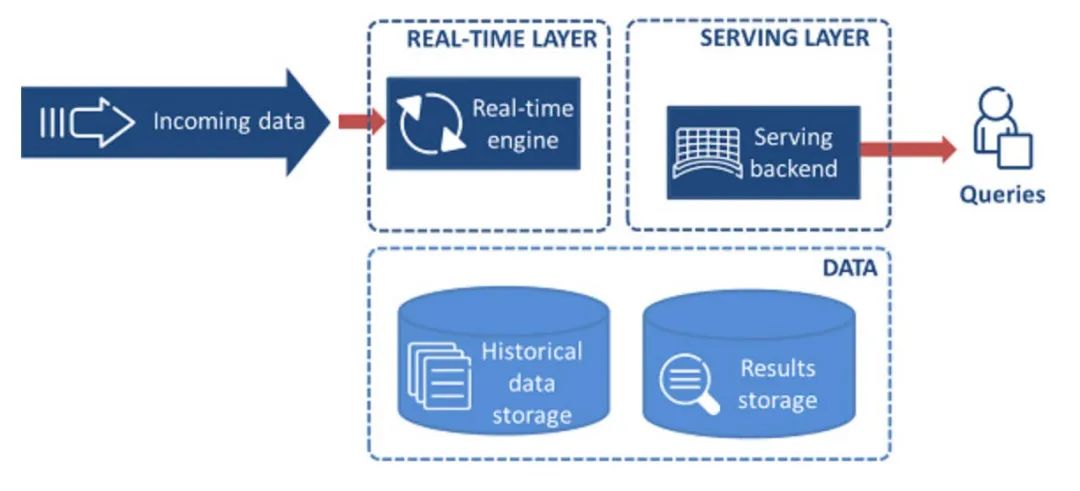
这种方案不是lambda架构的替代品,而是改良版,它去掉了批处理部分,比如在以Kafka作为流数据存储来源的系统来说,对于ReComputation的场景,只需要创建新版本的job,移动offset偏移量,结果输出到新的table,然后再将旧的job和结果表去掉。
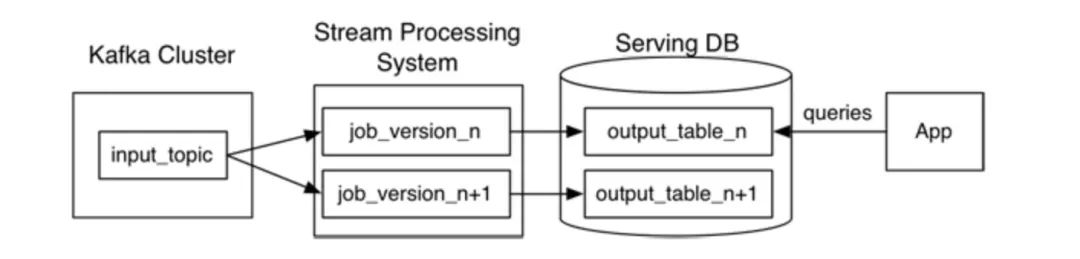
Kappa初看起来比较合理,但是距离生产级应用还有很大距离,比如历史数据都存储在Kafka会造成很大的成本,在使用场景上,更适合带有事件时间的append-only类流式数据,不适合基于历史数据按照任意组合条件交互式场景下的查询分析,除非将这些数据搬迁到另外的大数据存储系统,比如HBase、HDFS等,但是这也只解决了计算的一体化,而没有解决存储和查询的一体化。最后,在端到端的数据一致性上也没有给出具体方案。
Kappa+是 Uber 提出流式数据处理架构,它的核心思想是以流计算方式将数据准实时提交到HDFS并保证每次提交的原子性,同时支持数据的更新。基于HDFS支持不同引擎的再计算和实时查询。
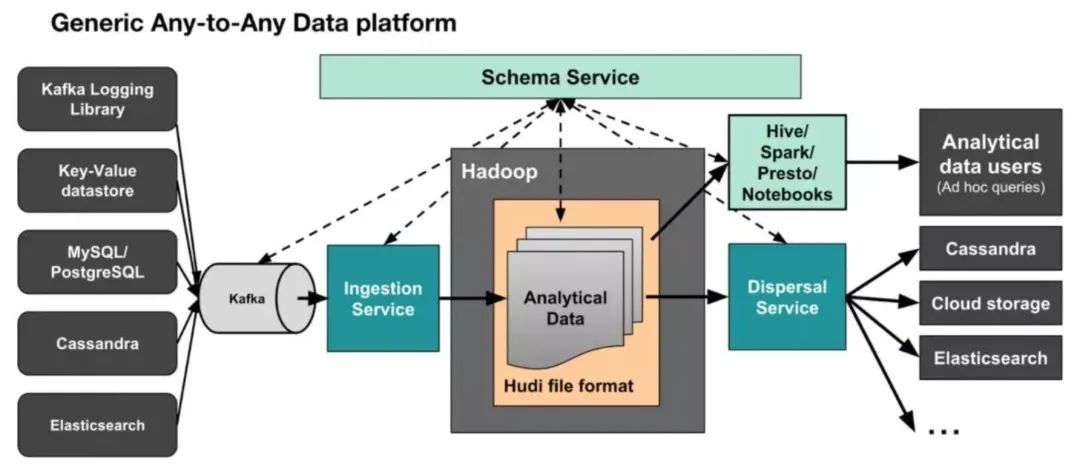
Whew!这其实就是基于数据湖的数据架构,它不仅解决了lambda架构的两套系统和计算逻辑的问题,也解决了Kappa的存储和一致性问题。比较AWS的Kinesis-Redishift架构,会发现两者有异曲同工之妙。
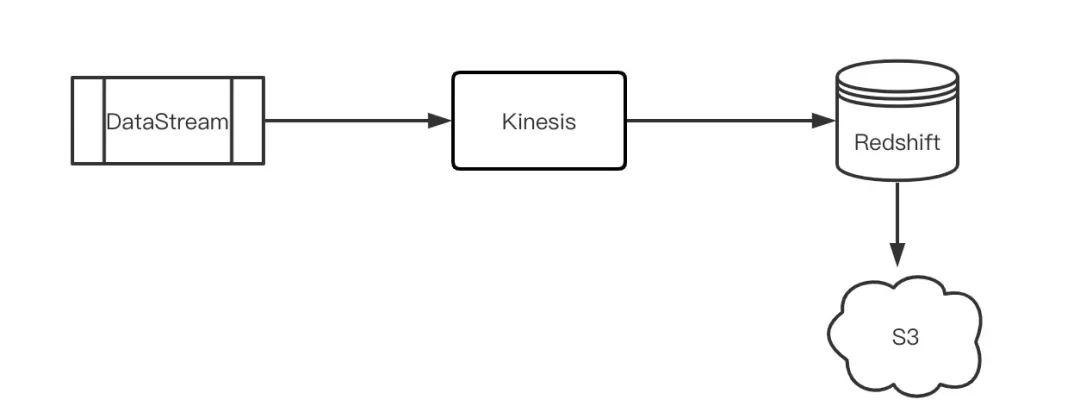
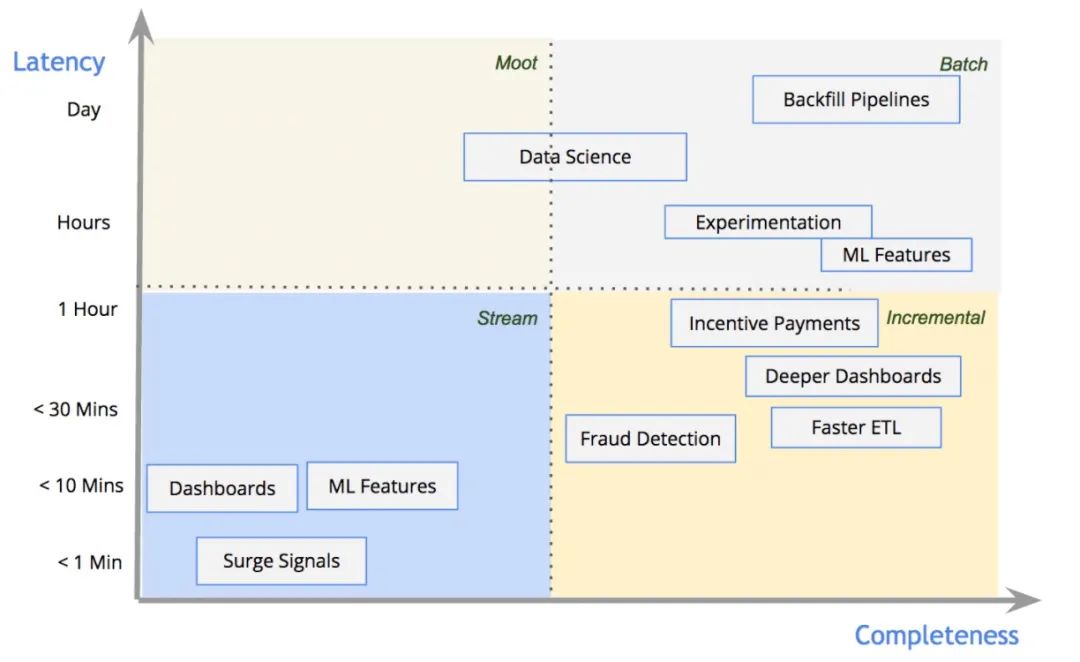
但这种架构也有自身的问题,最大的问题是查询性能和延迟,不管是Uber Hudi还是AWS Redshift都依赖数据提交的间隔,该间隔通常都在数十秒级或者分钟级,下图是Uber不同类型的任务对延迟的要求和完成方式,由图可见,绝大部分任务延迟要求在1分钟以上,传统的机器学习等场景还是靠批处理完成。
数据湖架构对于秒级及其以下场景还是无法满足,如果做到秒级的数据导入和查询,就需要实现统一的存储和查询系统了,这为商业产品提供了机会,在这方面,比如阿里的Hologres和AnalyticDB走在了前列。
https://www.oreilly.com/radar/questioning-the-lambda-architecture/
https://www.oreilly.com/radar/the-world-beyond-batch-streaming-101/
https://www.oreilly.com/radar/the-world-beyond-batch-streaming-102/
https://ci.apache.org/projects/flink/flink-docs-release-1.13/docs/dev/datastream/operators/windows/
https://ci.apache.org/projects/flink/flink-docs-master/docs/ops/state/task_failure_recovery/
https://eng.uber.com/hoodie/
The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing
以上是关于如何进行流批一体架构设计的主要内容,如果未能解决你的问题,请参考以下文章