OpenCV-Python实战(12)——一文详解AR增强现实
Posted 盼小辉丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OpenCV-Python实战(12)——一文详解AR增强现实相关的知识,希望对你有一定的参考价值。
OpenCV-Python实战(12)——一文详解AR增强现实
0. 前言
增强现实 (Augmented Reality, AR) 是目前最热门的应用研究之一。增强现实的概念可以定义为将虚拟信息与真实世界巧妙融合的技术,其中真实世界的视图通过叠加的计算机生成的虚拟元素(例如,图像、视频或 3D 模型等)得到增强。为了叠加和融合数字信息(增强现实),可以使用不同类型的技术,主要包括基于位置和基于识别的方法。
1. 增强现实简介
基于位置和基于识别的增强现实是增强现实的两种主要类型,它们的关键的都在于推导出用户正在查看的位置。此信息是增强现实过程中的关键,其依赖于正确计算相机姿态估计,两种类型简介如下:
- 基于位置的增强现实依赖于通过从多个传感器(例如 GPS、陀螺仪和加速传感器等)读取数据来检测用户的位置和方向,以计算用户正在查看的位置。
- 基于识别的增强现实使用图像处理技术来推导出用户正在查看的位置。从图像中获取相机姿态需要找到环境中已知点与其对应的相机投影之间的对应关系。查找这种对应关系的方法可以分为两类:
- 基于标记的姿态估计:这种方法依赖于使用平面标记(在增强现实领域多使用基于方形标记的方法)计算相机姿态。使用方形标记的一个主要缺点是相机姿态的计算依赖于对标记四个角的准确确定。在有遮挡的情况下,标记可能非常困难,但目前已有一些基于标记检测的方法也可以很好地处理遮挡,例如
ArUco。 - 基于无标记的姿态估计:当场景不能使用标记来获得姿态估计时,可以使用图像中自然存在的对象进行姿态估计。一旦计算了一组 n 个 2D 点及其相应的 3D 坐标,就可以通过解决透视 n 点 (
Perspective-n-Point,PnP) 问题来估计相机的姿态。由于这些方法依赖于点匹配技术,但输入数据中大多包含异常值,因此在姿态估计过程中需要使用针对异常值的鲁棒技术(例如,RANSAC)。
- 基于标记的姿态估计:这种方法依赖于使用平面标记(在增强现实领域多使用基于方形标记的方法)计算相机姿态。使用方形标记的一个主要缺点是相机姿态的计算依赖于对标记四个角的准确确定。在有遮挡的情况下,标记可能非常困难,但目前已有一些基于标记检测的方法也可以很好地处理遮挡,例如
2. 基于无标记的增强现实
基于无标记的增强现实,可以从图像中推导出相机姿态估计,以找到环境中已知点与其相机投影之间的对应关系。在本节中,我们将看到如何从图像中提取特征以获得相机姿态。基于这些特征及其匹配,我们将看到如何最终推导出相机姿态估计,然后将其用于叠加和融合数字信息。
2.1 特征检测
一个特征可以被描述为图像中的一小块区域,它对图像的缩放、旋转和照明尽可能保持不变。因此,可以从同一场景不同视角的不同图像中检测到相同的特征。综上,一个好的特征应具备以下特性:
- 可重复(可以从同一物体的不同图像中提取相同的特征)
- 可区分(不同结构的图像具有不同的特征)
OpenCV 提供了许多算法来检测图像的特征,包括:哈里斯角检测 (Harris Corner Detection)、Shi-Tomasi 角检测 (Shi-Tomasi Corner Detection)、SIFT (Scale Invariant Feature Transform)、SURF (Speeded-Up Robust Features)、FAST (Features from Accelerated Segment Test)、BRIEF (Binary Robust Independent Elementary Features) 以及 ORB (Oriented FAST and Rotated BRIEF) 等。
接下里,以 ORB 算法为例,对图像进行特征检测和描述。 ORB 可以看作是 FAST 关键点检测器和 BRIE 描述符的组合,并进行了关键改进以提高性能。
首先是检测关键点,ORB 使用修改后的 FAST-9 算法 (radius = 9 ,并存储检测到的关键点的方向)检测关键点 (keypoints, 默认为 500个)。一旦检测到关键点,下一步就是计算描述符以获得与每个检测到的关键点相关联的信息。ORB 使用改进的 BRIEF-32 描述符来获取每个检测到的关键点的描述符。检测到的关键点的描述符结构如下:
[ 43 106 98 30 127 147 250 72 95 68 244 175 40 200 247 164 254 168 146 197 198 191 46 255 22 94 129 171 95 14 122 207]
根据上述讲解,第一步是创建 ORB 检测器:
orb = cv2.ORB_create()
然后是检测图像中的关键点:
# 加载图像
image = cv2.imread('example.png')
# 检测图像中的关键点
keypoints = orb.detect(image, None)
检测到关键点后,下一步就是计算检测到的关键点的描述符:
keypoints, descriptors = orb.compute(image, keypoints)
请注意,也可以执行通过 orb.detectAndCompute(image, None) 函数同时检测关键点并计算检测到的关键点的描述符。
最后,使用 cv2.drawKeypoints() 函数绘制检测到的关键点:
image_keypoints = cv2.drawKeypoints(image, keypoints, None, color=(255, 0, 255), flags=0)
运行结果如下所示,右侧图像显示了由 ORB 关键点检测器检测到的关键点(为了更好的进行观察,对图像进行了局部放大):
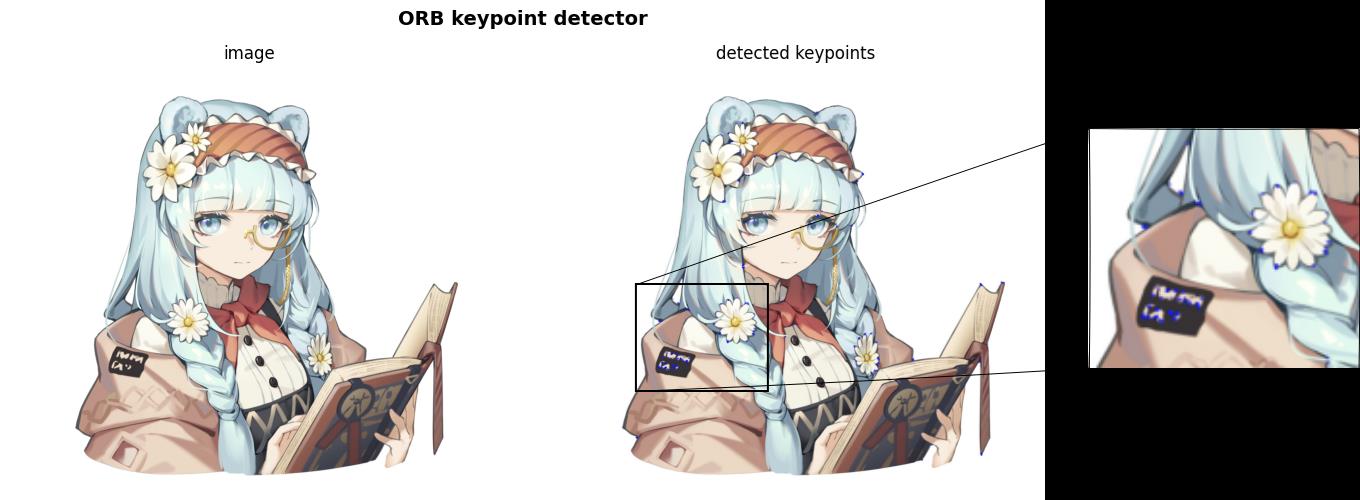
2.2 特征匹配
接下来,将介绍如何匹配检测到的特征。 OpenCV 提供了两种匹配器:
- 蛮力 (
Brute-Force,BF) 匹配器:该匹配器利用为第一组中检测到的特征计算的描述符与第二组中的所有描述符进行匹配。最后,它返回距离最近的匹配项。 - Fast Library for Approximate Nearest Neighbors (
FLANN) 匹配器:对于大型数据集,此匹配器比 BF 匹配器运行速度更快,它利用了最近邻搜索的优化算法。
接下来,我们使用 BF 匹配器来查看如何匹配检测到的特征,第一步是检测关键点并计算描述符:
# 加载图像
image_1 = cv2.imread('example_1.png')
image_2 = cv2.imread('example_2.png')
# ORB 检测器初始化
orb = cv2.ORB_create()
# 使用 ORB 检测关键点并计算描述符
keypoints_1, descriptors_1 = orb.detectAndCompute(image_1, None)
keypoints_2, descriptors_2 = orb.detectAndCompute(image_2, None)
下一步是使用 cv2.BFMatcher() 创建 BF 匹配器对象:
bf_matcher = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
cv2.BFMatcher() 函数的第一个参数 normType 用于设置距离测量方法,默认为 cv2.NORM_L2,如果使用 ORB 描述符(或其他基于二进制的描述符,例如 BRIEF 或 BRISK),则要使用的距离测量方法 cv2.NORM_HAMMING;第二个参数 crossCheck (默认为 False) 可以设置为 True,以便在匹配过程中只返回两个集合中相互匹配的特征。
创建匹配器对象后,使用 BFMatcher.match() 方法匹配检测到的描述符:
bf_matches = bf_matcher.match(descriptors_1, descriptors_2)
descriptors_1 和 descriptors_2 是计算得到的描述符;返回值为两个图像中获得了最佳匹配,我们可以按距离的升序对匹配项进行排序:
bf_matches = sorted(bf_matches, key=lambda x: x.distance)
最后,我们可以使用 cv2.drawMatches() 函数绘制匹配特征对,为了更好的可视化效果,仅显示前 20 个匹配项:
result = cv2.drawMatches(image_query, keypoints_1, image_scene, keypoints_2, bf_matches[:20], None, matchColor=(255, 255, 0), singlePointColor=(255, 0, 255), flags=0)
cv2.drawMatches() 函数水平拼接两个图像,并绘制从第一个图像到第二个图像的线条以显示匹配特征对,程序的运行结果如下所示:
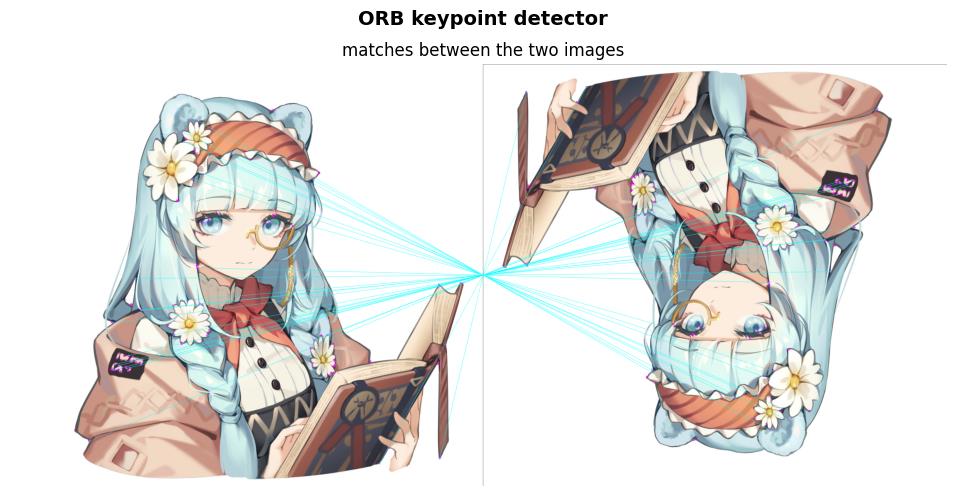
2.3 利用特征匹配和单应性计算以查找对象
最后我们将利用上述特征匹配和单应性计算查找对象。为了达到此目的,在完成特征匹配后,下一步需要使用 cv2.findHomography() 函数在两幅图像中找到匹配关键点位置之间的透视变换。
OpenCV 提供了多种计算单应矩阵的方法,包括 RANSAC、最小中值 (LMEDS) 和 PROSAC (RHO)。我们以使用 RANSAC 方法为例:
# 提取匹配的关键点
pts_src = np.float32([keypoints_1[m.queryIdx].pt for m in best_matches]).reshape(-1, 1, 2)
pts_dst = np.float32([keypoints_2[m.trainIdx].pt for m in best_matches]).reshape(-1, 1, 2)
# 计算单应性矩阵
M, mask = cv2.findHomography(pts_src, pts_dst, cv2.RANSAC, 5.0)
其中,pts_src 是匹配的关键点在源图像中的位置,pts_dst 是匹配的关键点在查询图像中的位置。
第四个参数 ransacReprojThreshold 设置最大重投影误差以将点对视为内点,如果重投影误差大于 5.0,则相应的点对被视为异常值。此函数计算并返回由关键点位置定义的源平面和目标平面之间的透视变换矩阵 M。
最后,基于透视变换矩阵 M,计算查询图像中对象的四个角,用于绘制匹配的目标边界框。为此,需要根据原始图像的形状计算其四个角,并使用 cv2.perspectiveTransform() 函数将它们转换为目标角:
# 获取“查询”图像的角坐标
h, w = image_query.shape[:2]
pts_corners_src = np.float32([[0, 0], [0, h - 1], [w - 1, h - 1], [w - 1, 0]]).reshape(-1, 1, 2)
# 使用矩阵 M 和“查询”图像的角点执行透视变换,以获取“场景”图像中“检测”对象的角点:
pts_corners_dst = cv2.perspectiveTransform(pts_corners_src, M)
其中,pts_corners_src 包含原图的四个角坐标,M 为透视变换矩阵; pts_corners_dst 输出包含查询图像中对象的四个角,之后,我们可以使用 cv2.polyline() 函数来绘制检测对象的轮廓:
img_obj = cv2.polylines(image_scene, [np.int32(pts_corners_dst)], True, (0, 255, 255), 10)
最后,使用 cv2.drawMatches() 函数绘制匹配特征点:
img_matching = cv2.drawMatches(image_query, keypoints_1, img_obj, keypoints_2, best_matches, None, matchColor=(255, 255, 0), singlePointColor=(255, 0, 255), flags=0)

3. 基于标记的增强现实
在本节中,我们将了解基于标记的增强现实的工作原理,我们以 ArUco 算法为例讲解基于标记的增强现实。
ArUco 会自动检测标记并纠正可能的错误。此外,ArUco 提出了通过将多个标记与遮挡掩码组合来解决遮挡问题的方法,遮挡掩码是通过颜色分割计算的。
使用标记的主要好处是可以在图像中有效且稳健基于标记执行姿势估计,其可以准确地导出标记的四个角,从先前计算的标记的四个角中获得相机姿态。
3.1 创建标记和字典
使用 ArUco 算法的第一步是创建标记和字典。ArUco 标记是由外部和内部单元(也称为位-bits)组成的方形标记。外部单元格设置为黑色,从而创建一个可以快速且稳健地检测到的外部边界;内部单元格用于对标记进行编码。可以创建不同尺寸的 ArUco 标记,标记的尺寸表示与内部矩阵相关的内部单元格的数量。例如,大小为 5 x 5 (n=5) 的标记由 25 个内部单元组成。此外,还可以设置标记边框的位数。
标记字典是在特定应用程序中使用的一组标记。虽然之前的算法使用固定字典,但 ArUco 提出了一种自动方法来生成具有所需数量和所需位数的标记,因此,ArUco 包括一些预定义的字典,涵盖与标记数量和标记大小相关的配置。
创建基于标记的增强现实应用程序时要考虑的第一步是创建要使用的标记。
第一步是创建字典对象。ArUco 包含了一些预定义字典:DICT_4X4_50 = 0,DICT_4X4_100 = 1,DICT_4X4_250 = 2,DICT_4X4_1000 = 3,DICT_5X5_50 = 4,DICT_5X5_100 = 5,DICT_5X5_250 = 6,DICT_5X5_1000 = 7,DICT_6X6_50 = 8,DICT_6X6_100 = 9,DICT_6X6_250 = 10, DICT_6X6_1000 = 11,DICT_7X7_50 = 12,DICT_7X7_100 = 13,DICT_7X7_250 = 14 及 DICT_7X7_1000 = 15。
使用 cv2.aruco.Dictionary_get() 函数创建一个由 250 个标记组成的字典。每个标记的大小为 7 x 7 (n=7):
aruco_dictionary = cv2.aruco.Dictionary_get(cv2.aruco.DICT_7X7_250)
可以使用 cv2.aruco.drawMarker() 函数绘制标记,该函数返回绘制的标记。 cv2.aruco.drawMarker() 的第一个参数是字典对象;第二个参数是标记 id ,范围在 0 到 249 之间,因为我们的字典有 250 个标记;第三个参数 sidePixels 是创建的标记图像的大小(以像素为单位);第四个参数是 borderBits (可选参数,默认为 1),它设置标记边框的位数。
创建三个具有不同位数的标记边框:
aruco_marker_1 = cv2.aruco.drawMarker(dictionary=aruco_dictionary, id=2, sidePixels=600, borderBits=1)
aruco_marker_2 = cv2.aruco.drawMarker(dictionary=aruco_dictionary, id=2, sidePixels=600, borderBits=2)
aruco_marker_3 = cv2.aruco.drawMarker(dictionary=aruco_dictionary, id=2, sidePixels=600, borderBits=3)
将这些创建的标记进行可视化,结果如下图所示:

3.2 检测标记
可以使用 cv2.aruco.detectMarkers() 函数检测图像中的标记:
corners, ids, rejected_corners = cv2.aruco.detectMarkers(gray_frame, aruco_dictionary, parameters=parameters)
cv2.aruco.detectMarkers() 的第一个参数是要检测标记的灰度图像;第二个参数是创建的字典对象;第三个参数其它可以用于在检测过程中自定义的参数。函数返回值如下:
- 返回检测到的标记的角列表,对于每个标记,返回其四个角(左上角、右上角、右下角和左下角)
- 返回检测到的标记的标识符列表
- 返回拒绝候选标记列表,它由所有找到的方块组成,但它们没有被适当的编码;每个被拒绝的候选标记同样由它的四个角组成
为了进行演示,我们检测摄像头中检测到的标记。首先,使用前面提到的 cv2.aruco.detectMarkers() 函数检测标记,然后,我们将使用 cv2.aruco.drawDetectedMarkers() 函数绘制检测到的标记和拒绝的候选标记,如下所示:
# 创建字典对象
aruco_dictionary = cv2.aruco.Dictionary_get(cv2.aruco.DICT_7X7_250)
# 创建参数对象
parameters = cv2.aruco.DetectorParameters_create()
# 创建视频捕获对象
capture = cv2.VideoCapture(0)
while True:
# 捕获视频帧
ret, frame = capture.read()
# 转化为灰度图像
gray_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 检测图像中标记
corners, ids, rejected_corners = cv2.aruco.detectMarkers(gray_frame, aruco_dictionary, parameters=parameters)
# 绘制检测标记
frame = cv2.aruco.drawDetectedMarkers(image=frame, corners=corners, ids=ids, borderColor=(0, 255, 0))
# 绘制被拒绝标记
frame = cv2.aruco.drawDetectedMarkers(image=frame, corners=rejected_corners, borderColor=(0, 0, 255))
# 展示结果
cv2.imshow('frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 销毁窗口
capture.release()
cv2.destroyAllWindows()
执行程序后,可以看到检测到的标记用绿色边框绘制,而被拒绝的候选标记用红色边框绘制:
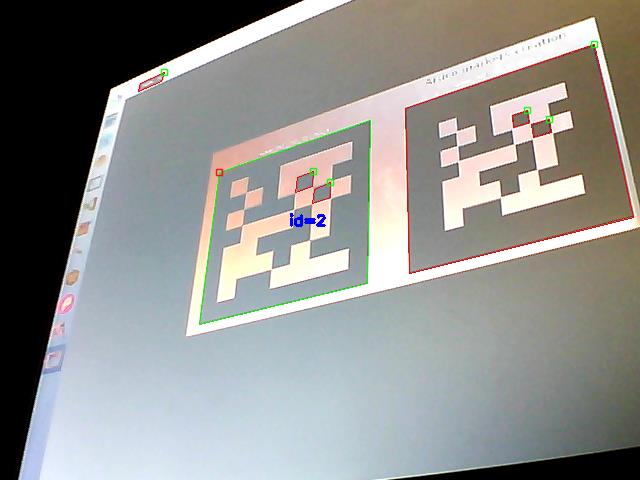
3.3 相机校准
在使用检测到的标记获得相机姿态之前,需要知道相机的标定参数,ArUco 提供了执行此任务所需的校准程序,校准程序仅需执行一次,因为程序执行过程中并未修改相机光学元件。校准过程中使用的主要函数是 cv2.aruco.calibrateCameraCharuco(),其使用从板上提取的多个视图中的一组角来校准相机。校准过程完成后,此函数返回相机矩阵(一个 3 x 3 浮点相机矩阵)和一个包含失真系数的向量,3 x 3 矩阵对焦距和相机中心坐标(也称为内在参数)进行编码,而失真系数对相机产生的失真进行建模。
函数的用法如下:
calibrateCameraCharuco(charucoCorners, charucoIds, board, imageSize, cameraMatrix, distCoeffs[, rvecs[, tvecs[, flags[, criteria]]]]) -> retval, cameraMatrix, distCoeffs, rvecs, tvecs
其中,charucoCorners 是一个包含检测到的 charuco 角的向量,charucoIds 是标识符列表,board 表示板布局,imageSize 是输入图像大小。输出向量 rvecs 包含为每个板视图估计的旋转向量,tvecs 是为每个模式视图估计的平移向量,此外,还需要返回相机矩阵 cameraMatrix 和失真系数 distCoeffs。
板是使用 cv2.aruco.CharucoBoard_create() 函数创建的,其函数用法如下:
CharucoBoard_create(squaresX, squaresY, squareLength, markerLength, dictionary) -> retval
这里,squareX 是 x 方向的方格数,squaresY 是 y 方向的方格数,squareLength 是棋盘方边长(通常以米为单位),markerLength 是标记边长(与 squareLength 单位相同),以及dictionary 设置字典中要使用的第一个标记,以便在板内创建标记:
# 创建板
dictionary = cv2.aruco.Dictionary_get(cv2.aruco.DICT_7X7_250)
board = cv2.aruco.CharucoBoard_create(3, 3, .025, .0125, dictionary)
img = board.draw((200 * 3, 200 * 3))
创建的板如下图所示:

该 board 稍后在校准过程中由 cv2.aruco.calibrateCameraCharuco() 函数使用:
# 创建字典对象
dictionary = cv2.aruco.Dictionary_get(cv2.aruco.DICT_7X7_250)
# 创建视频捕获对象
cap = cv2.VideoCapture(0)
all_corners = []
all_ids = []
counter = 0
for i in range(300):
# 读取帧
ret, frame = cap.read()
# 转化为灰度图像
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 标记检测
res = cv2.aruco.detectMarkers(gray, dictionary)
if len(res[0]) > 0:
res2 = cv2.aruco.interpolateCornersCharuco(res[0], res[1], gray, board)
if res2[1] is not None and res2[2] is not None and len(res2[1]) > 3 and counter % 3 == 0:
all_corners.append(res2[1])
all_ids.append(res2[2])
# 绘制探测标记
cv2.aruco.drawDetectedMarkers(gray, res[0], res[1])
cv2.imshow('frame', gray)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
counter += 1
try:
# 相机校准
cal = cv2.aruco.calibrateCameraCharuco(all_corners, all_ids, board, gray.shape, None, None)
except:
cap.release()
print("Calibration could not be done ...")
# 获取校准结果
retval, cameraMatrix, distCoeffs, rvecs, tvecs = cal
校准过程完成后,使用 pickle 将相机矩阵和失真系数保存到磁盘:
f = open('calibration.pckl', 'wb')
pickle.dump((cameraMatrix, distCoeffs), f)
f.close()
校准程序完成后,就可以执行相机姿态估计了。
3.4 相机姿态估计
为了估计相机姿态,需要使用 cv2.aruco.estimatePoseSingleMarkers() 函数,它估计单个标记的姿态,姿态由旋转和平移向量组成,其用法如下:
cv2.aruco.estimatePoseSingleMarkers(corners, markerLength, cameraMatrix, distCoeffs[, rvecs[, tvecs[, _objPoints]]]) -> rvecs, tvecs, _objPoints
其中,cameraMatrix 和 distCoeffs 分别是相机矩阵和畸变系数;它们是相机校准后获得的值;参数 corners 是一个向量,包含每个检测到的标记的四个角;markerLength 参数是标记边的长度;返回的平移向量保存在同一单元中。此函数返回每个检测到的标记的 rvecs (旋转向量)、tvecs (平移向量)和 _objPoints (所有检测到的标记角的对象点数组)。
标记坐标系以标记的中间为中心。因此,标记的四个角的坐标如下:
(-markerLength/2, markerLength/2, 0)
(markerLength/2, markerLength/2, 0)
(markerLength/2, -markerLength/2, 0)
(-markerLength/2, -markerLength/2, 0)
ArUco 还提供 cv2.aruco.drawAxis() 函数,用于为每个检测到的标记绘制系统轴,其用法如下:
cv2.aruco.drawAxis(image, cameraMatrix, distCoeffs, rvec, tvec, length) -> image
length 参数设置绘制轴的长度(与 tvec 单位相同),其他参数与之前函数相同。
# 加载相机校准数据
with open('calibration.pckl', 'rb') as f:
cameraMatrix, distCoeffs = pickle.load(f)
# 创建字典对象
aruco_dictionary = cv2.aruco.Dictionary_get(cv2.aruco.DICT_7X7_250)
# 创建参数对象
parameters = cv2.aruco.DetectorParameters_create()
# 创建视频捕获对象
capture = cv2.VideoCapture(0)
while True:
# 捕获视频帧
ret, frame = capture.read()
# 转换为灰度图像
gray_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 探测标记
corners, ids, rejectedImgPoints = cv2.aruco.detectMarkers(gray_frame, aruco_dictionary, parameters=parameters)
# 绘制标记
frame = cv2.aruco.drawDetectedMarkers(image=frame, corners=corners, ids=ids, borderColor=(0, 255, 0))
# 绘制被拒绝候选标记
frame = cv2.aruco.drawDetectedMarkers(image=frame, corners=rejectedImgPoints, borderColor=(0, 0, 255))
if ids is not None:
# rvecs, tvecs分别是角点中每个标记的旋转和平移向量
rvecs, tvecs, _ = cv2.aruco.estimatePoseSingleMarkers(corners, 1, cameraMatrix, distCoeffs)
# 绘制系统轴
for rvec, tvec in zip(rvecs, tvecs):
cv2.aruco.drawAxis(frame, cameraMatrix, distCoeffs, rvec, tvec, 1)
# 绘制结果帧
cv2.imshow('frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
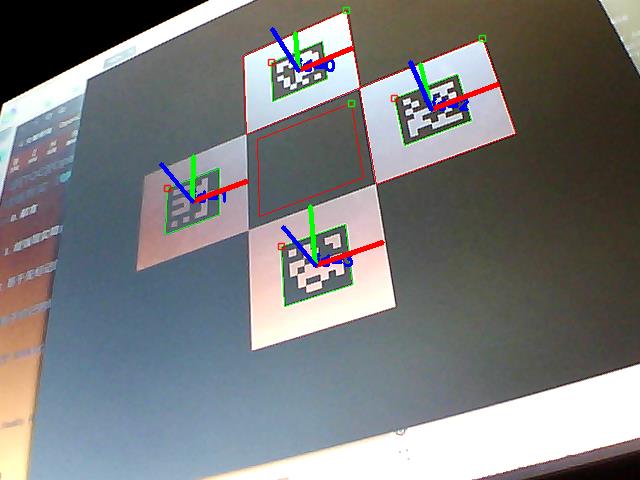
3.5 增强现实初探
之后,我们就可以在现实图像中融合一些图像、形状或 3D 模型,以展示完整的
以上是关于OpenCV-Python实战(12)——一文详解AR增强现实的主要内容,如果未能解决你的问题,请参考以下文章