人工智能之目标检测系列综述
Posted 狂奔的CD
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了人工智能之目标检测系列综述相关的知识,希望对你有一定的参考价值。
前言
参考 https://blog.csdn.net/jiaoyangwm/article/details/89111539
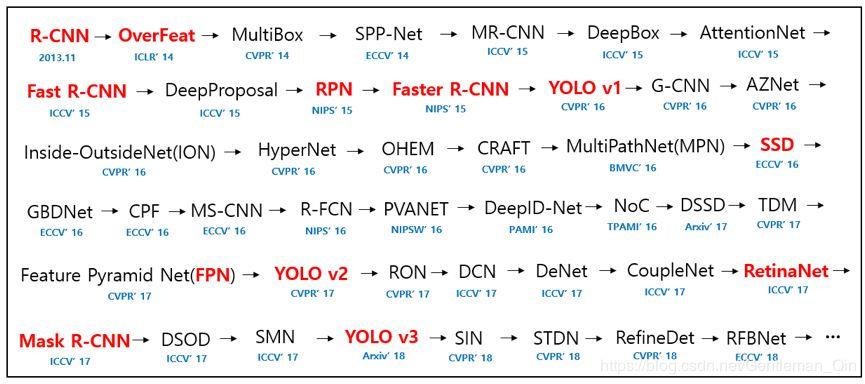
时间线
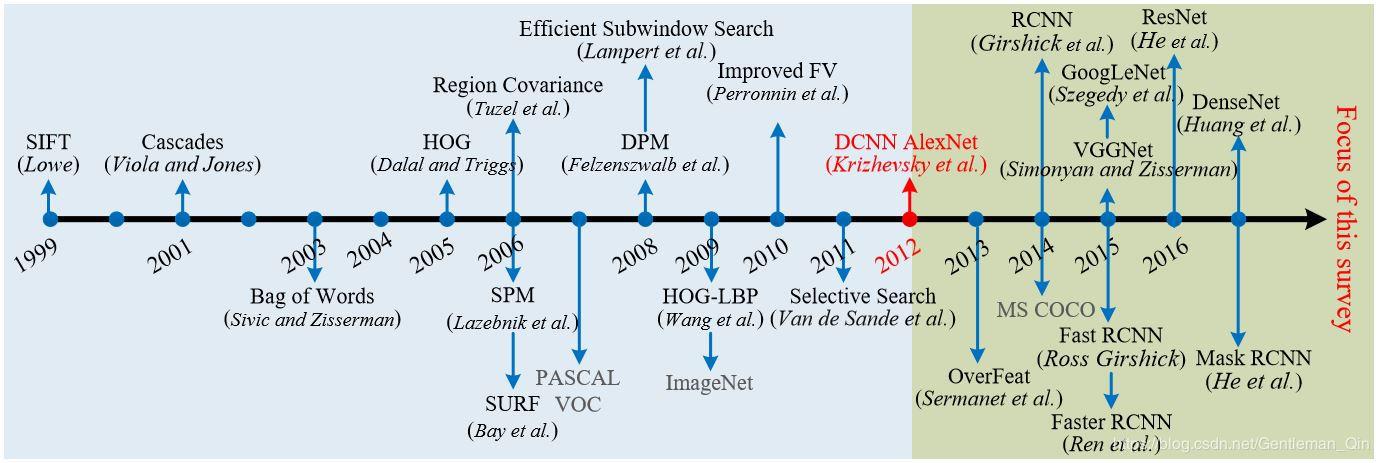
慢慢补充
正文
1.传统目标检测
在深度学习出现之前,传统的目标检测方法大概分为区域选择(滑窗)、特征提取(SIFT、HOG等)、**分类器(SVM、Adaboost等)**三个部分,其主要问题有两方面:一方面滑窗选择策略没有针对性、时间复杂度高,窗口冗余;另一方面手工设计的特征鲁棒性较差。
参考 https://blog.csdn.net/eternity1118_/article/details/88894617
2.目标检测-神经网络
参考:https://blog.csdn.net/electech6/article/details/95240278
概要记录:
改文章主要描述的是基于神经网络的目标检测模型
一类是基于Region Proposal的R-CNN系算法(R-CNN,Fast R-CNN, Faster R-CNN等),它们是two-stage的,需要先算法产生目标候选框,也就是目标位置,然后再对候选框做分类与回归。而另一类是Yolo,SSD这类one-stage算法,其仅仅使用一个卷积神经网络CNN直接预测不同目标的类别与位置。第一类方法是准确度高一些,但是速度慢,但是第二类算法是速度快,但是准确性要低一些。这可以在下图中看到。
2-1. R-CNN
【算法流程】
- 输入一张图片,通过指定算法从图片中提取 2000 个类别独立的候选区域(可能目标区域)
- 对于每个候选区域利用卷积神经网络来获取一个特征向量
- 对于每个区域相应的特征向量,利用支持向量机SVM 进行分类,并通过一个bounding box regression调整目标包围框的大小
【贡献】
在2014年R-CNN横空出世的时候,颠覆了以往的目标检测方案,精度大大提升。对于R-CNN的贡献,可以主要分为两个方面:
- 使用了卷积神经网络进行特征提取
- 使用bounding box regression进行目标包围框的修正
【缺陷】
- 耗时的selective search,对一张图像,需要花费2s
- 耗时的串行式CNN前向传播,对于每一个候选框,都需经过一个AlexNet提取特征,为所有的候选框提取特征大约花费47s
- 三个模块(CNN特征提取、SVM分类和边框修正)是分别训练的,并且在训练的时候,对于存储空间的消耗很大
2-2. Fast R-CNN
【算法流程】
- 首先还是采用selective search提取2000个候选框RoI
- 使用一个卷积神经网络对全图进行特征提取
- 使用一个RoI Pooling Layer在全图特征上摘取每一个RoI对应的特征
- 分别经过为21和84维的全连接层(并列的,前者是分类输出,后者是回归输出)
【贡献】
Fast R-CNN的贡献可以主要分为两个方面:
- 取代R-CNN的串行特征提取方式,直接采用一个CNN对全图提取特征(这也是为什么需要RoI Pooling的原因)。
- 除了selective search,其他部分都可以合在一起训练。
Fast R-CNN通过CNN直接获取整张图像的特征图,再使用RoI Pooling Layer在特征图上获取对应每个候选框的特征,避免了R-CNN中的对每个候选框串行进行卷积(耗时较长)
【缺陷】
Fast R-CNN也有缺点,体现在耗时的selective search还是依旧存在。
2-3. Faster R-CNN
【算法流程】
Faster R-CNN由共享卷积层、RPN、RoI pooling以及分类和回归四部分组成:
- 首先使用共享卷积层为全图提取特征feature maps
- 将得到的feature maps送入RPN,RPN生成待检测框(指定RoI的位置),并对RoI的包围框进行第一次修正
- RoI Pooling Layer根据RPN的输出在feature map上面选取每个RoI对应的特征,并将维度置为定值
- 使用全连接层(FC Layer)对框进行分类,并且进行目标包围框的第二次修正。
尤其注意的是,Faster R-CNN真正实现了端到端的训练(end-to-end training)。Faster R-CNN最大特色是使用了RPN取代了SS算法来获取RoI。
2-4.Mask R-CNN
【算法流程】
Mask R-CNN可以分解为如下的3个模块:Faster-RCNN、RoI Align和Mask。
2-5.Yolo
Yolo创造性的提出了one-stage,也就是将物体分类和物体定位在一个步骤中完成。Yolo直接在输出层回归bounding box的位置和bounding box所属类别,从而实现one-stage。通过这种方式,Yolo可实现45帧每秒的运算速度
【算法流程】
主要分为三个部分:卷积层,目标检测层,NMS筛选层
【缺陷】
Yolo算法开创了one-stage检测的先河,它将物体分类和物体检测网络合二为一,都在全连接层完成。故它大大降低了目标检测的耗时,提高了实时性。但它的缺点也十分明显
- 每个网格只对应两个bounding box,当物体的长宽比不常见(也就是训练数据集覆盖不到时),效果很差。
- 原始图片只划分为7x7的网格,当两个物体靠的很近时,效果很差
- 最终每个网格只对应一个类别,容易出现漏检(物体没有被识别到)。
- 对于图片中比较小的物体,效果很差。这其实是所有目标检测算法的通病,SSD对它有些优化,我们后面再看。
2-6.SSD
Faster R-CNN准确率mAP较高,漏检率recall较低,但速度较慢。而Yolo则相反,速度快,但准确率和漏检率不尽人意。SSD综合了他们的优缺点,对输入300x300的图像,在voc2007数据集上test,能够达到58 帧每秒( Titan X 的 GPU ),72.1%的mAP。
【算法流程】
和Yolo一样,也分为三部分:卷积层,目标检测层和NMS筛选层。SSD和Yolo一样都是采用一个CNN网络来进行检测,但是却采用了多尺度的特征图。
ps:从以上了解来看,对于微小目标检测,面临两个问题,
一是,神经网络卷积过程中的下采样,会不断忽略细节,微小物体比如10x10这样的size,使用多层卷积可能出现检测不了的情况。
二是,准确率相较大目标,会低很多
以上是关于人工智能之目标检测系列综述的主要内容,如果未能解决你的问题,请参考以下文章