数据结构 排序
Posted 一个正直的男孩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构 排序相关的知识,希望对你有一定的参考价值。
导读:这有下列复杂度中logN->N->N*logN->N^2
一般有N*logN的时间复杂度已经是快的飞起了,且如果待排序的数据越多那么他和N^2的差距会越来越大
且开始前先和大家说时间上没有十全十美的东西,所也下面的排序也是,他们各有各应用场景,不要像上世纪的医学一样,一种药就说包治百病……
且排序这个在现在这个互联网时代中是随处可见的:打王者排名,淘宝的热销产品
插入排序
从第二个元素开始插入,并合前面的元素比较,如果元素比前面的元素小就交换,之前体育课的时候要排队,但是排队需要
动图演示:
代码:
void InsertSort(int* arr,int n)
{
for(int i=0;i<=n-2;i++)//需要交换的次数
{
//交换的区间
int front=i;
int end=i+1;
while(end>0)
{
if(arr[front]>arr[end])//如果前面的元素比他大就交换
{
Swap(&arr[front--],&arr[end--]);//交换数据
}
else
{
break;
}
}
}
}
上面最好的情况时间复杂度是啥呢?其实全部有序那么就是0(N),那么最坏的情况是啥样的呢?就是逆序每给节点往前插入次数每次多加一次的递增那么就是等差数列时间复杂度是O(N^2)
希尔排序
他是插入排序的优化,会对待排序的数据先进行预排序,那么像最上面逆序的情况就不是O(N^2) ,有了预排序他的时间复杂度从O(N^2 )变成了O(N*logN)因为有了这个就可以少挪几次
那么他如何待排序的呢?其实控制步距预排序。你想下,步距越小是不是排的次数越多,那么就越靠近有序,越大就交换少。步距大就像是之前写暑假作业老师都是抽查的,步距小就像平时改作业,当步距为1就是考试了,每张试卷都不放过
如图所示:
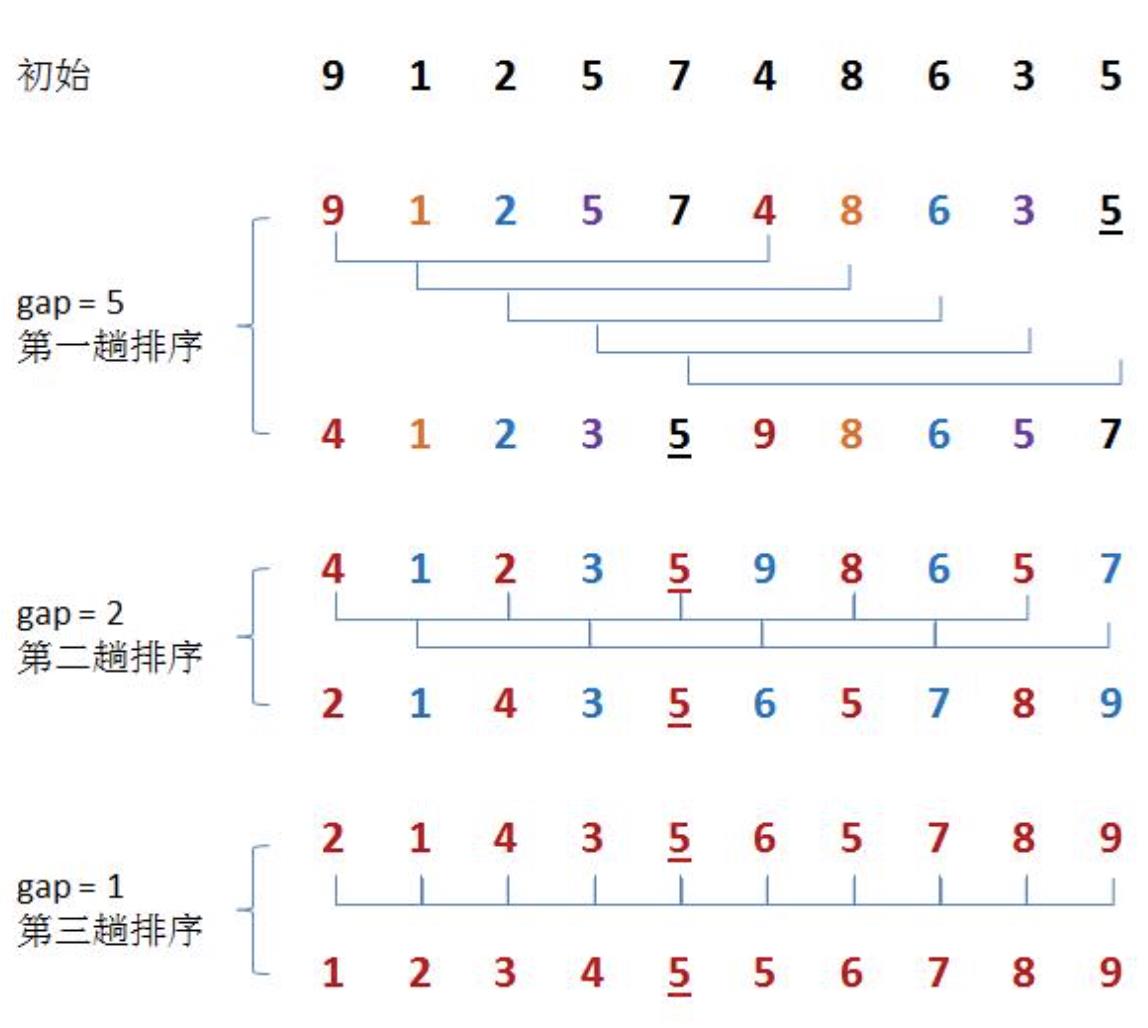
代码:
void ShellSort(int* a, int n) {
int gap = n;//步距
while(gap>0)
{
gap=(gap+1)/3;//步距
for (int i = 0; i < n - gap; i++)
{
int began = i;
int end = began + gap;
while (began >= 0)
{
if (a[began] > a[end])
{
began = began - gap;//向前找到自己合适的位置
}
else
{
break;
}
}
Swap(&a[began + gap], &a[end]);//交换
}
}
}
冒泡排序
这个排序是最简单就,每进行一次排序就会把最大的元素放到末尾,这个也是和现实中体育排队,一般在队伍中最显眼的一定是最高的
动图演示
代码:
int main(int argc, char *argv[])
{
int arr[]={69, 14, 51, 81, 20, 9 ,47 ,29 ,11 ,35};
int sz=sizeof(arr)/sizeof(arr[1]);
for(int i=0;i<sz;i++)//需要走几次
{
int decide=0;//这个可以让冒泡最好情况下优化到O(N)
for(int j=0;i<sz-i;j++)//需要交换几次
{
if(arr[j]<arr[j+1])
{
Swap(&arr[j],&arr[j+1]);
decide=1;
}
}
if(decide==0)
{
break;
}
}
}
那么最好情况的复杂度是多少呢?其实是O(N),这个全部有序的情况,那么最坏呢?显然他和插入排序一样逆序
选择排序
选择排序的基本思路就是每次选一个最小或者最大的数据放到他的他专属的位置,个人感觉和冒泡的感觉,但是他可以可以变形,一趟排俩个数据(最大值,最小值) 选择排序plus
动图示范:
代码:
void SelectSort(int* a, int n)//少交换
{
int began = 0;
int end = n - 1;
while(began<end)//需要交换的次数
{
int mini = began, max = end;
for (int i = began; i <= end; i++)
{
if(a[i]<a[mini])//更新min下标
{
mini=i;
}
if(a[i]>a[max])//更新max下标
{
max = i;
}
}
Swap(&a[max],&a[end]);
if(a[max]==a[mini])//交换过程中可能会导致原来比较小的那个被交换,变成大的
{
max=mini;
}
Swap(&a[mini],&a[began]);
began++;
end--;
}
}
那么他的时间复杂度是多少呢? 最好,最坏情况都是O(N^2),显然他似乎比较呆,为啥呢,不管这个数列是不是有序的他都不知道,你想他那个逻辑是不是
# 堆排
前文介绍过了就在阐述了
快排序
为啥叫快排,当然是应为快咯,他最好和最坏的的情况是O(N*logN),但是会有一个特殊情况(下面诉说)
看看他是如何实现的呢?有三个版本
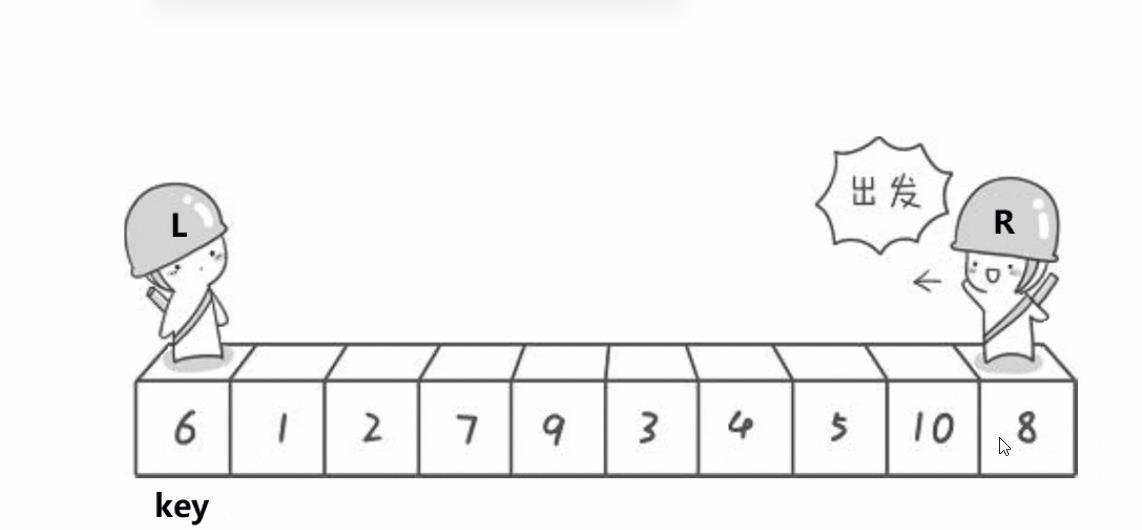
- hoare版本(祖师爷版)
他给我的感觉是有点分治算法与与选择排序的感觉,俩个下标和一个key,key是首元素,一个存头,一个存尾,然后尾先走找比key小的元素,找到停下,然后头去找大的找到停下,交换,最终key就到了他的正确位置,左边的区域比key小,右边的区域比他大
动图演示:
代码:
void hoare(int *arr,int front ,int end)
{
int began=0;
int end=n-1;
int key=0;
while(began<end)
{
while(began<end&&arr[end]>=arr[key])//去找大的
{
end--;
}
while(began<end&&arr[began]<=arr[key])//去找小的
{
began++;
}
Swap(&arr[began],&arr[end]);
}
Swap(&arr[key],&arr[end]);
}
-
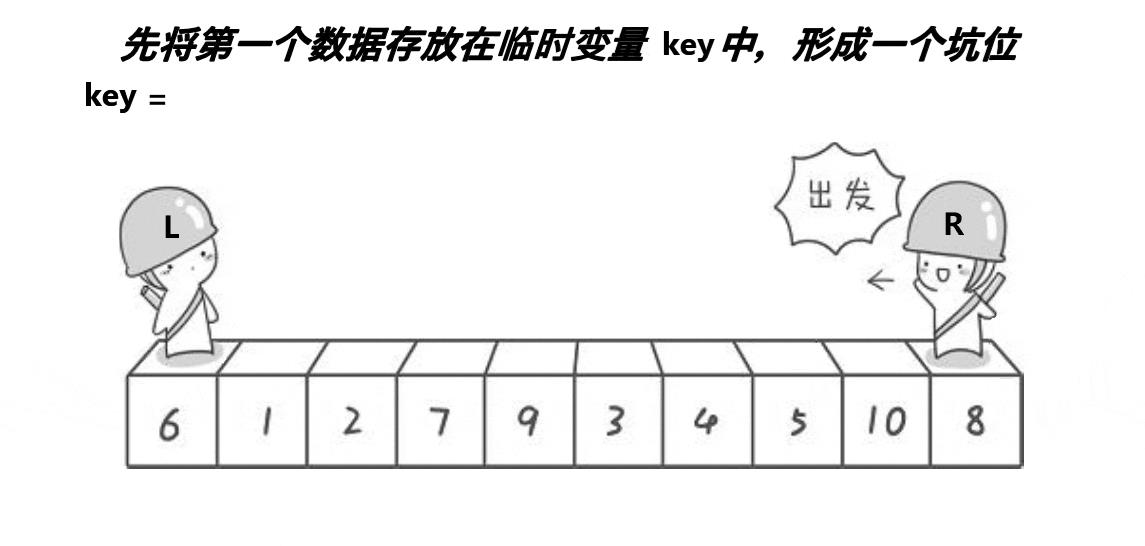
挖坑法
这儿就是上面的进化版本了,把key存起来(key还是头),尾开始找比key小的元素,找到就填坑,那么尾所在的位置就是坑,头去找大的一直填坑,直到相遇把key填入就完成啦
动图演示:
代码:
void Potholing(int *arr,int front ,int end)
{
int began=front;
int end=end;
int key=arr[front];//挖坑
while(began<end)
{
while(arr[end]>=key)//找萝卜填坑
{
end--;
}
arr[began]=arr[end];//填坑
while(arr[began]<=key)//上面挖了一个萝卜又有坑
{
began++;
}
arr[end]=arr[began];//填坑
}
arr[end]=key;//吧key萝卜填进去,这块地就没坑了
}
-
前后指针版
有俩指针 prev cur ,prev指向的是第一个数据,cur是他下一个数据
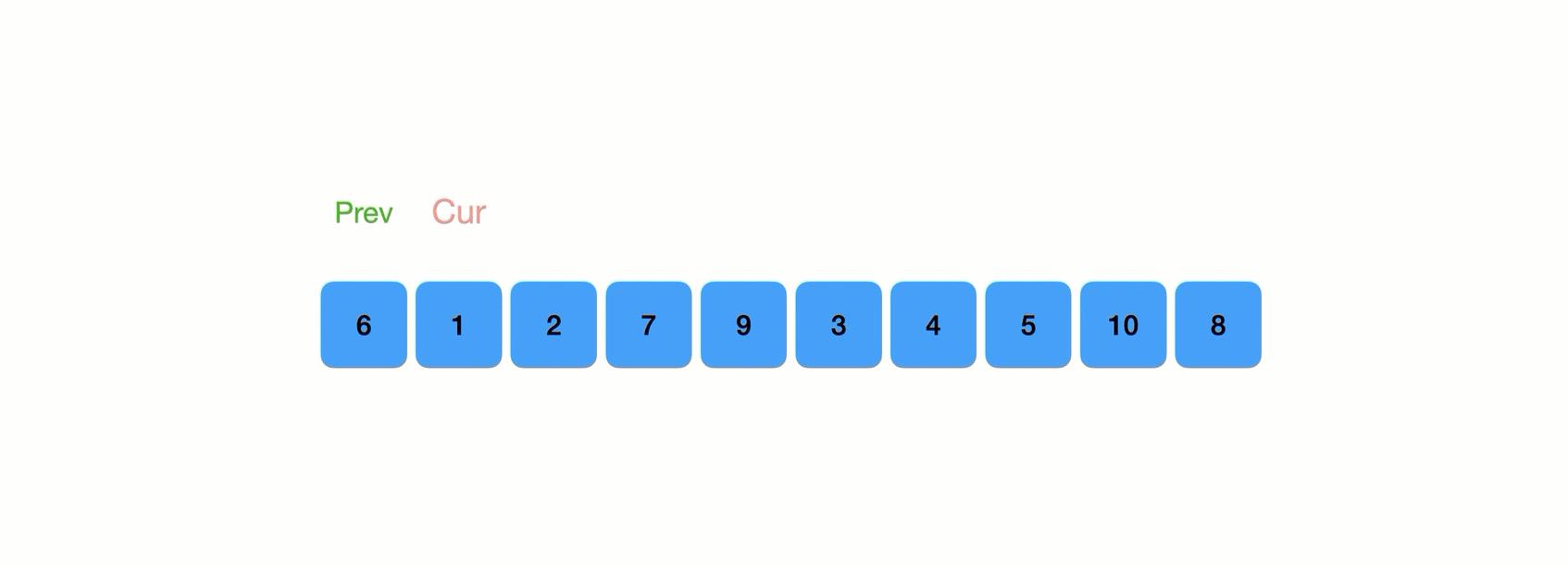
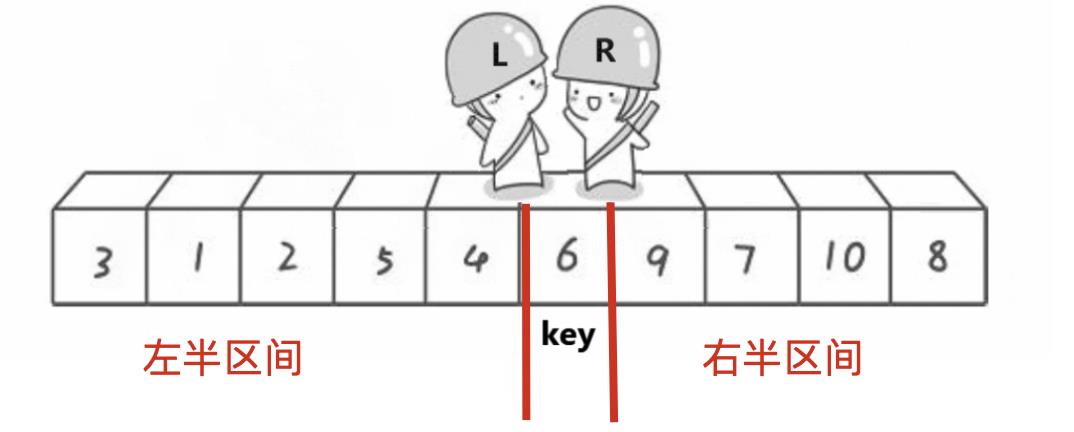
cur走,遇到小的prev就和cur交换,遇到大的就前进,这样key也可以到达他的所属位置
图解
代码:
void FBPointer(int *arr,int front ,int end)
{
int key=*arr;
int* prev=arr;
int* cur=arr+1;
while(end--)
{
if(*cur<key)
{
Swap(cur,prev++);//小就交换
}
cur++;
}
}
但是一趟显然不够那咋办呢,上面说了哟分治算法(大事化小,一直化到不可在化的子问题),那么就是递归了
那控制排序的逻辑是这样的,以key为中心,分左半区间和右半区间
先排左半区间,在排右半区间,且他排序会和上重复上面的思路找key分左区间与右区间
代码
void QuickSort(int *arr,int front ,int end)//控制区间
{
//
if(front>=end)
{
return ;
}
int key=hoare(arr,front,end);
//区间[front key-1][key+1 end]
QuickSort(arr,front,key-1);
QuickSort(arr,key+1,end);
}
致命缺陷与优化
三目取中
应为是有序导致的那么就我就把他打乱不就好了,这就是他的作用他的基本逻辑就是取头,中间,末尾,三个元素中不大不小的那个做key
void Middle_key(int *arr,int front ,int middle,int end)
{
if(arr[front]>arr[end])//头>尾
{
if(arr[front]<arr[middle])//头<中
{
return;
}
}
else if(arr[end]>arr[front])//尾>头
{
if(arr[end]<arr[middle])//尾<中
{
Swap(&arr[end],&arr[end]);
return;
}
}
else
{
Swap(&arr[end],&arr[middle]);//key
}
}
归并排序
他本质是用了分治的思想(把大问题拆分成小问题,在吧子问题查分成子问题,直到不可拆分),且他空间复杂度是O(N)
动图演示:
他先分成一组一组的区间,直到分到不可在分的时候回溯比较,然后考回原数组如此重复即可达到有序,本质是二叉树的后续遍历
void RMergerSort(int *arr,int *sort,int front,int end )
{
if(front>=end)
{
return;
}
int middle=(front+end)/2;
//分治,把他分成不可分割的子问题
RMergerSort(arr,sort,front,middle);
RMergerSort(arr,sort,middle+1,end);
int began1=front,end1=middle;
int began2=middle+1,end2=end;
int index=front;
while(began1<=end1&&began2<=end2)//排序
{
if(arr[began1]<arr[began2])
{
sort[index]=arr[began1++];
}
else
{
sort[index]=arr[began2++];
}
index++;
}
while(began1<=end1)//这段数据是否有数据
{
sort[index++]=arr[began1++];
}
while(began2<=end2)//这段数据是否有数据
{
sort[index++]=arr[began2++];
}
for(int i=0;i<=end;i++)//考回原数组
{
arr[i]=sort[i];
}
}
以上是关于数据结构 排序的主要内容,如果未能解决你的问题,请参考以下文章