[人工智能-深度学习-36]:卷积神经网络CNN - 简单地网络层数堆叠导致的问题分析(梯度消失梯度弥散梯度爆炸)与解决之道
Posted 文火冰糖的硅基工坊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[人工智能-深度学习-36]:卷积神经网络CNN - 简单地网络层数堆叠导致的问题分析(梯度消失梯度弥散梯度爆炸)与解决之道相关的知识,希望对你有一定的参考价值。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/120919308
目录
第1章 简单堆叠神经元导致参数量剧增的问题
1.1 网络层数增加大带来的好处
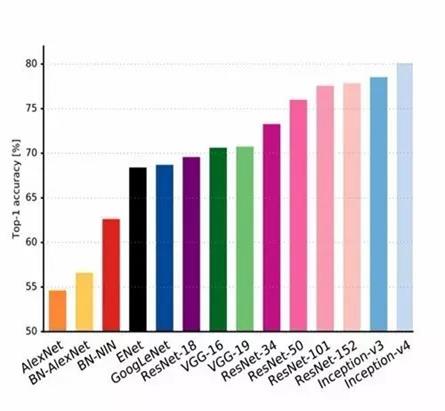
1.2 一个奇怪的现象
从LeNet网络到Inception-V4,其性能不断的提升, 网络的层数不断杂在增加。当网络增加到20层左右时研究人员发现:随着网络层数的增加,性能反而是下降的,如下图所示:
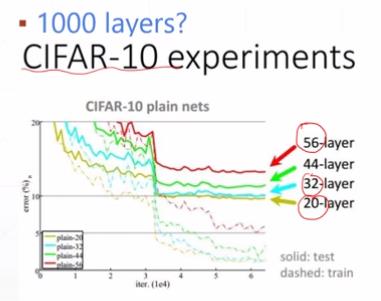
随着网络层数的增加,网络总体性能在下降!!!
1.3 网络层数增加带来的负面效果
随着网络层数的增加,出现几个数学现象:
(1)权重参与的数量巨量增加
(2)不同层的参数的分布特征不同。
(3)不同层的参数的变化率不同。
(4)不同层的参数对结果的影响不同,然后梯度迭代时的效果是相同。
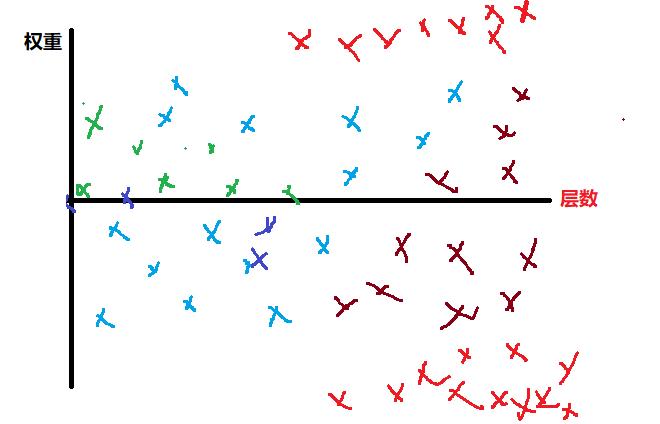
第2章 参数量剧增导致的训练问题
训练的过程就是梯度逐渐迭代的过程,反向传播的梯度计算是每一次的梯度计算要依赖于后一级的梯度。随着网络层数的增加,上述参数的变化,会导致深度学习、训练出现一些新的问题:
2.1 计算量的增加
(1)问题
权重参与的数量巨量增加,导致计算量的大幅度增加。
(2)接近办法
针对这个问题,可以通过GPU集群来解决,对于一个企业资源并不是很大的问题;
2.2 模型容易过拟合,泛化能力变差。
(1)问题
参数越多,拟合样本的能力越强,但样本本身也是误差的,且样本本身的表现形态也是多样的。
过渡的拟合,导致拟合出来的网络,过于注重样本的形态,而忽略了样本内在的特征和规律。
这就是过拟合,过拟合的结果就是模型泛化能力变差,无法发现模型内部的本质特征 。
(2)解决办法
可以通过采集海量数据,并配合Dropout正则化等方法也可以有效避免;
2.3 梯度异常
(1)梯度消失或梯度弥散:梯度接近于0
(2)梯度爆炸:梯度接近于无穷
2.4 loss异常
(1)网络回退:当增加网络深度,训练集loss反而会增大的现象。
第3章 梯度消失:参数的变化率接近与
3.1 什么是梯度消失和梯度弥散
简单的讲,就是某些网络层的梯度在没有拟合完成前,就已经降低解决于0,导致网络无法学习。
即在梯度的反向传播过程中,经过多层的梯度相乘,导致靠近输入神经元会比靠近输出的神经元的梯度成指数级衰减,甚至接近于0.
靠近输出层的hidden layer 梯度大,参数更新快,所以很快就会收敛;
而靠近输入层的hidden layer 梯度小,权重参数更新慢,几乎就和初始状态一样,随机分布(初始化成随机分布)。这种现象就是梯度弥散(vanishing gradient problem)。
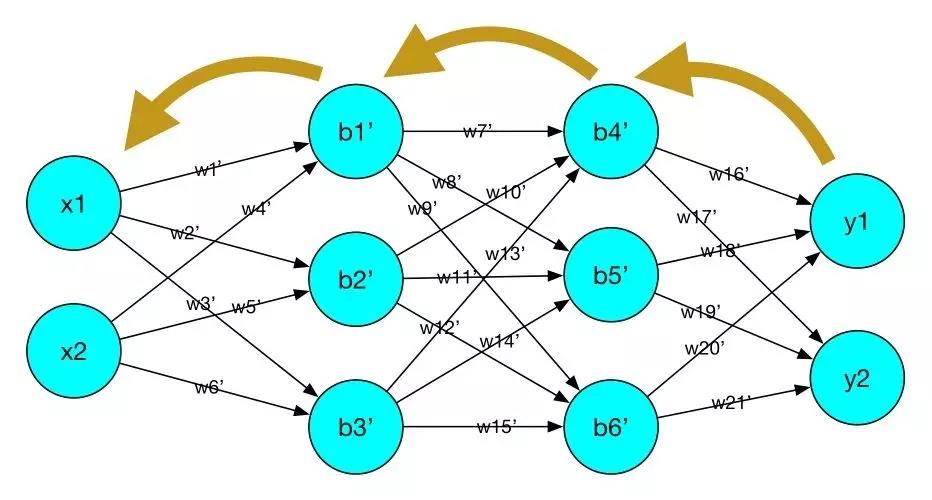
3.2 梯度的由来:反向传播的梯度下降来优化神经网络参数
反向传播的梯度下降来优化神经网络参数:
根据损失函数计算的误差,通过反向传播的方式,指导深度网络参数的更新优化。
3.3 采取反向传播的原因:
深层网络由许多线性层和非线性层堆叠而来,每一层非线性层都可以视为是一个非线性函数f(x)(非线性来自于非线性激活函数),因此整个深度网络可以视为是一个复合的非线性多元函数。
我们最终的目的是希望这个非线性函数很好的完成输入到输出之间的映射,也就是找到让损失函数取得极小值。
所以最终的问题就变成了一个寻找函数最小值的问题,在数学上,很自然的就会想到使用梯度下降来解决。
3.4 梯度消失会带来哪些影响
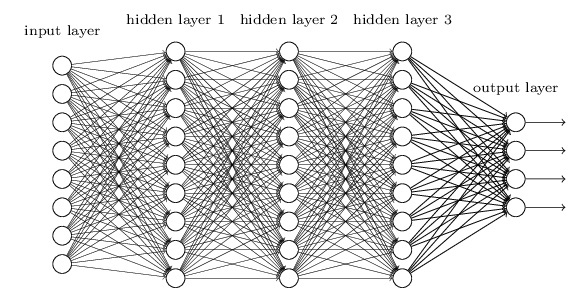
举个例子,对于一个含有三层隐藏层的简单神经网络来说,当梯度消失发生时:
接近于输出层的隐藏层,由于其梯度相对正常,所以权值更新时也就相对正常,
接近于输入层的隐藏层,由于梯度消失现象,会导致靠近输入层的隐藏层权值更新缓慢或者更新停滞。
这就导致在训练时,只等价于后面几层的浅层网络的学习。
3.5 梯度消失的原因
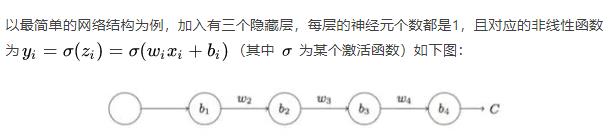

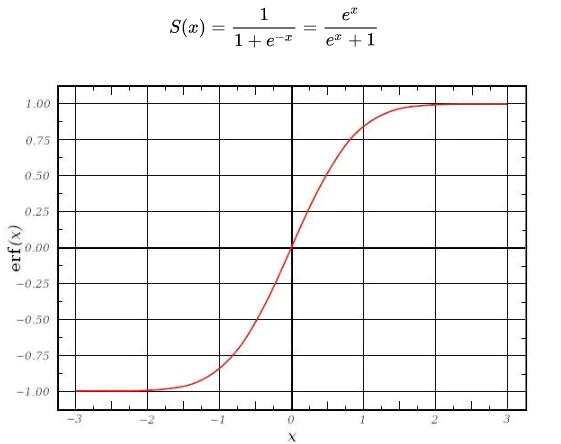
sigmod函数,导致神经元的被输出被限制在0和1区间。
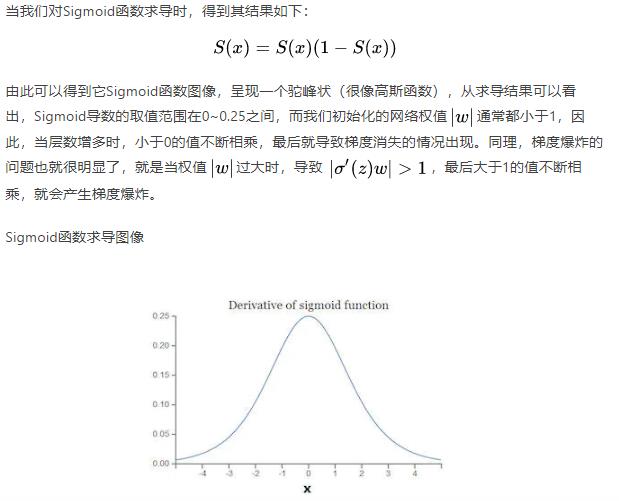
因此这种现象的根本原因,一方面来自于激活函数,另一个根本原因在于“链式求导”。这是深度学习的根基!!!
3.5 梯度消失的解决思路
- 重构深度学习的基石:链式求导,这有一定的难度。
- 降低网络的层数
- 优化网络的架构,避免梯度消失或梯度爆炸
- 优化激活函数
3.6 梯度消失的几个解决办法
梯度消失和梯度爆炸本质上是一样的,一个根本的因为是:
网络层数太深而引发的梯度反向传播中的连乘效应。
解决梯度消失、爆炸主要有以下几种方案案例:
(1)换用Relu、LeakyRelu、Elu等激活函数
ReLu:让激活函数的导数很定为1,不会出现梯度消失或梯度爆炸。
LeakyReLu:包含了ReLu的几乎所有优点,同时解决了ReLu中0区间带来的影响
ELU:和LeakyReLu一样,都是为了解决0区间问题,相对于来,elu计算更耗时一些(为什么)
(2)BN: BatchNormalization(归一化)
归一化,有类类似每个神经元对输出与的限制与放大。
通过归一化,确保每个神经元输出,都被重选放大或缩小,以规范的方式输出。
BN本质上是解决传播过程中的梯度消失或爆炸问题。
(3)逐层训练 + 整体finetunning
此方法来自Hinton在06年发表的论文上,其基本思想是:
每次训练一层隐藏层节点,将上一层隐藏层的输出作为输入,而本层的输出作为下一层的输入,这就是逐层预训练。
训练完成后,再对整个网络进行“微调(fine-tunning)”。
此方法相当于是找局部最优,然后整合起来寻找全局最优;
但是现在基本都是直接拿imagenet的预训练模型直接进行finetunning。
(4)改变网络结构
如残差ReNet网络结构、LSTM网络结构。后续单独讨论这些网络架构。
第4章 梯度爆炸:梯度接近于无穷
4.1 什么事梯度爆炸
梯度爆炸与梯度消失正好相反,是随着网络层数的增加,接近输入端的网络的梯度,经过多次相乘后,梯度得到了无线的放大。
4.2 梯度爆炸的原因
梯度爆炸的原因与梯度消失基本相同。
梯度的衰减是有连续乘法导致的,如果在连续乘法中出现连续的多个非常大的值,最后计算出的梯度就会很大。
相当于优化过程中,遇到断崖处时,会获得一个很大的梯度值,如果按照这个梯度值进行更新,那么这次迭代的步长就很大,可能会一下子飞出了合理的区域。
4.3 梯度爆炸的解决方法
与梯度消失相似,除此之外,梯度爆炸还有自身独特的解决办法:
(1)阈值法
其思想是设值一个剪切阈值,如果更新梯度时,梯度超过了这个阈值,那么就将其强制限制在这个范围之内。这样可以防止梯度爆炸。
第5章 网络退回现象
5.1 什么事网络回退线性
针对梯度弥散或爆炸,似乎可以通过Batch Normalization(归一化)的方法可以避免。
解决了梯度梯度消失和梯度爆炸后,貌似我们就可以无脑的增加网络的层数来获得更好的网络性能:准确率和泛化能力。但实验数据给了我们当头一棒。
随着网络层数的增加,发生了一个神奇的退化(degradation)的现象:
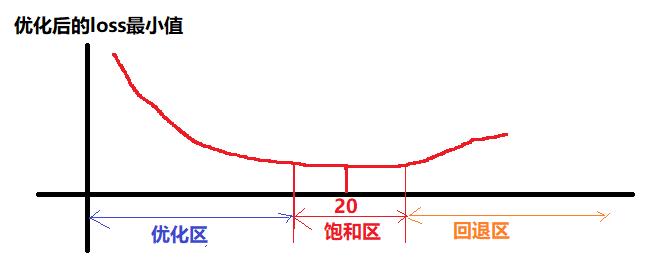
(1)优化区
一开始,当网络层数从0逐渐增多时,训练集的loss值,在训练学习后的值会逐渐下降。
(2)饱和区
当网络层数得到20层附近时,再通过增加网络层数,loss的减少就不明显了,甚至loss的减少接近于0,这个区称为loss的饱和区。
(3)回退区
当网络层数再增大时,loss不但不减少,反而会增大。这就称为“网络回退现象”,回退到较低网络层次的水平。
注意:这并不是过拟合,因为在过拟合中训练loss是一直减小的,甚至loss为0.
当网络退化时,深层网络只能达到浅层网络的水平,这样,通过增加网络层的深度的意义就不大了,反而是负面的了,因为增加网络的深度,会导致参数的增加、计算机的增加、网络传输的延时等,并没有带来错误率的下降和准确率的提升 。
5.2 管理层级与专有化、精细化分工
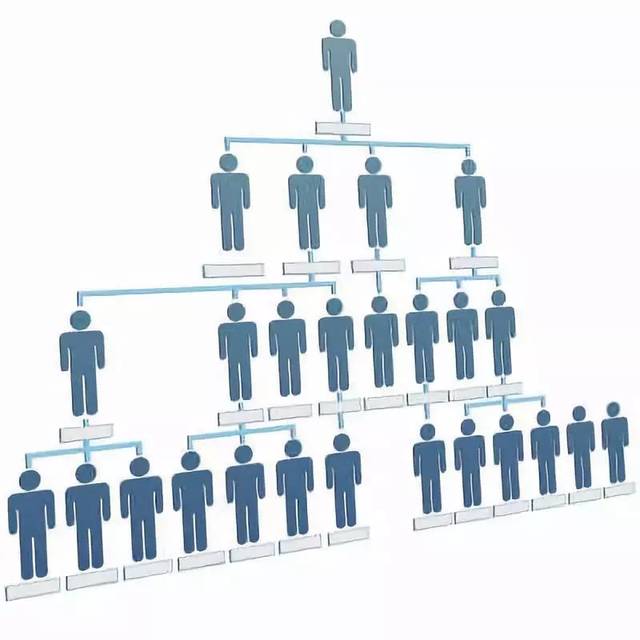
随着公司、国家规模的增长,管理层级也越来越大,区分的种类也越来越多,但并非层级越多越好,管理层级与公司的规模有一定的关系,当管理的层级超过一定的门限后,管理的效能是整体效能是下降的。神经网络也是一样。
5.3 神经网络退回现象背后的原理
从信息论的角度讲,由于DPI(数据处理不等式)的存在。在前向传输的过程中,随着层数的加深,抽象程度也在提升,共性在提升,个性在降低。共性的信息量是低的,共性程度越高的,信息量是越少的,个性程度越多的,描述个性的信息是越多的,也就说随着网络层数的增加,也就是Feature Map包含的信息量会逐层减少。因此,就不需要通过更多的神经元参数加以区分。
5.4 神经网络退回现象的解决办法
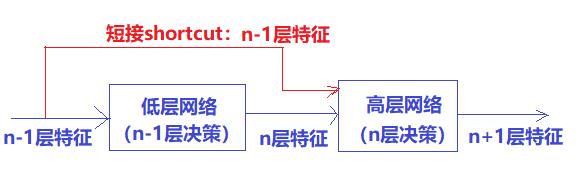
浅层网络具备更多的特征信息,如果我们把浅层(低层管理层)的特征传到高层(管理层),让高层根据这些信息进行决策(分类和特征提取),那么高层最后的效果应该至少不比浅层的网络效果差,最坏的情况是与低层更好的效果,更普遍的情况是,高层由于有更多、更抽象的特征信息,因此高层的决策效果会比低层更准确。
更抽象的讲,我们需要一种技术,确保保证了L+1层的网络一定比 L层包含更多的图像信息。
这就是ResNet shortcut网络结构的底层逻辑和内在思想!!!。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/120919308
以上是关于[人工智能-深度学习-36]:卷积神经网络CNN - 简单地网络层数堆叠导致的问题分析(梯度消失梯度弥散梯度爆炸)与解决之道的主要内容,如果未能解决你的问题,请参考以下文章