4.软件架构设计:大型网站技术架构与业务架构融合之道 --- 操作系统
Posted enlyhua
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了4.软件架构设计:大型网站技术架构与业务架构融合之道 --- 操作系统相关的知识,希望对你有一定的参考价值。
第4章 操作系统
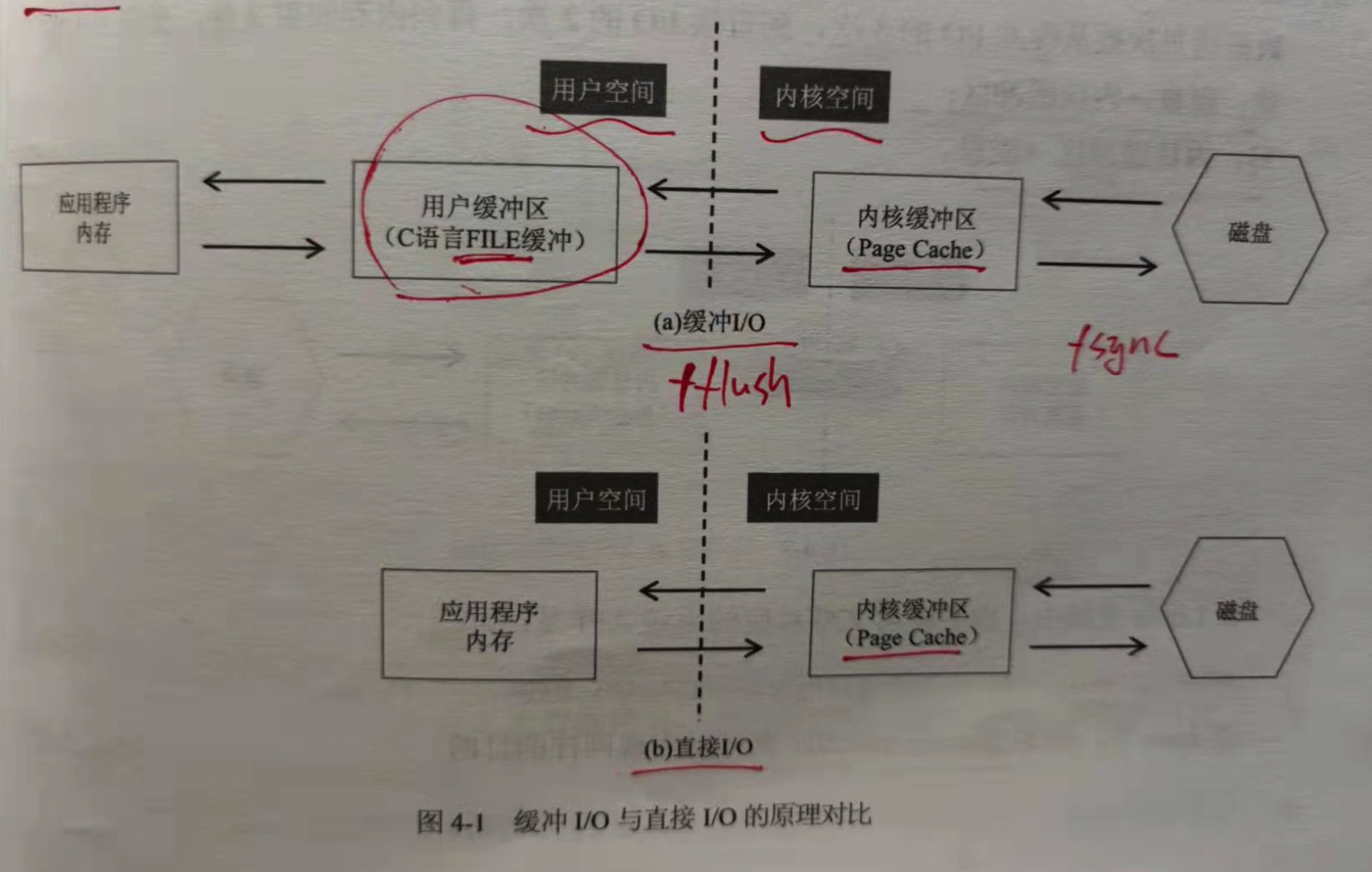
4.1 缓冲I/O和直接I/O
缓冲IO:缓冲IO是C语言提供的库函数,均以f打头;
fopen,fclose,fseek,fflush,fread,fwrite,fprintf,fscanf;
直接IO:是Linux系统的API,操作系统的API也是C语言写的;
open,close,lseek,fsync,read,write,pread,pwrite;
应用程序内存:是通常写代码用 malloc/free,new/delete 等分配出来的内存;
用户缓冲区:C语言FILE结构体里面 buffer;
内核缓冲区:Linux操作系统的Page Cache。为了加快磁盘IO,Linux系统会把磁盘上的数据以 Page为单位在操作系统的内存里,这里的Page是Linux
系统定义的一个逻辑概念,一般一个Page为4k。
对于缓冲IO,一般读操作会有3次数据拷贝,一个写操作,有反向的3次数据拷贝;
读:磁盘 => 内核缓冲区 => 用户缓冲区 => 应用程序内存;
写:应用程序内存 => 用户缓冲区 => 内核缓冲区 => 磁盘;
对于直接IO:一个读操作,会有2次数据拷贝,一个写操作,有反向的2次数据拷贝;
读:磁盘 => 内核缓冲区 => 应用程序内存;
写:应用程序内存 => 内核缓冲区 => 磁盘。
所谓的直接IO,其中直接的意思是指没有用户级缓冲,但操作系统本身的缓冲还是有的。
关于缓冲IO和直接IO,有几点需要特别说明:
1.fflush和fsync的区别。fflush是缓冲IO的一个API,它只是把数据从用户缓冲区刷到内核缓冲区,fsync则是把数据从内核缓冲区刷到磁盘。
这意味着无论是缓冲IO,还是直接IO,如果在写数据之后不调用fsync,此时系统断电重启,最新的部分数据就会丢失,因为数据还只是在内核缓冲
区中,操作系统还没来得及刷到磁盘。后面讲到数据库,数据一致性,这个fsync很重要。
2.对于直接IO,也有read/write和pread/pwrite两组不同的API。pread/pwrite在多线程读写同一个文件的时候很有用。
4.2 内存映射文件与零拷贝
4.2.1 内存映射文件
相比于直接IO,内存映射文件更进一步了。当用户空间不再有物理内存,直接拿应用程序的逻辑内存映射到Linux操作系统的内核缓冲区,应用程序
虽然读写的是自己的内存,但这个内存只是一个"逻辑地址",实际读写的是内核缓冲区。
数据拷贝从缓冲IO的3次,到直接IO的2次,再到内存映射文件的1次。
读:磁盘 => 内核缓冲区
写:内核缓冲区 => 磁盘
在Linux中,内存映射文件对应的系统API是:mmap()
4.2.2 零拷贝
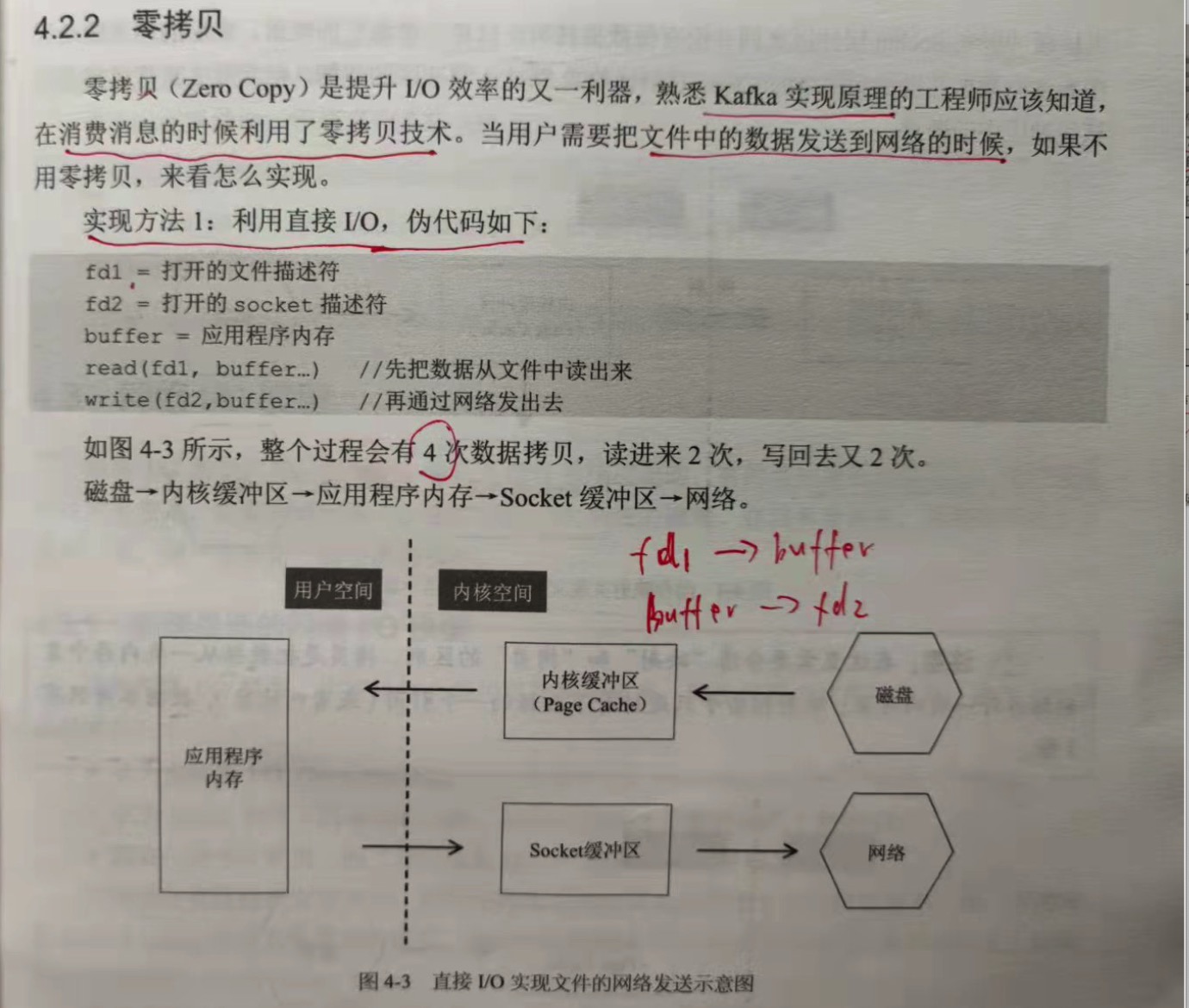
当用户需要把文件中的数据发送到网络的时候,如果不用零拷贝,实现方式有:
实现方法1:利用直接IO,伪代码如下:
fd1 = 打开的文件描述符
fd2 = 打开的socket描述符
buffer = 应用程序内存
read(fd1,buffer ...) // 先把数据从文件中读取出来
write(fd2,buffer ...) //再通过网络发送出去
整个过程会有4次数据拷贝,读进来2次,写回去2次。
磁盘 => 内核缓冲区 => 应用程序内存 => Socket缓冲区 => 网络
实现方法2:利用内存映射文件,伪代码如下:
fd1 = 打开的文件描述符
fd2 = 打开的socket描述符
buffer = 应用程序内存
mmap(fd1,buffer ...) //先把磁盘数据映射到buffer上
write(fd2,buffer ...) //再通过网络发送出去
整个过程会有3次数据拷贝,不再经过应用程序内存,直接在内核空间中从内核缓冲区拷贝到socket缓冲区。
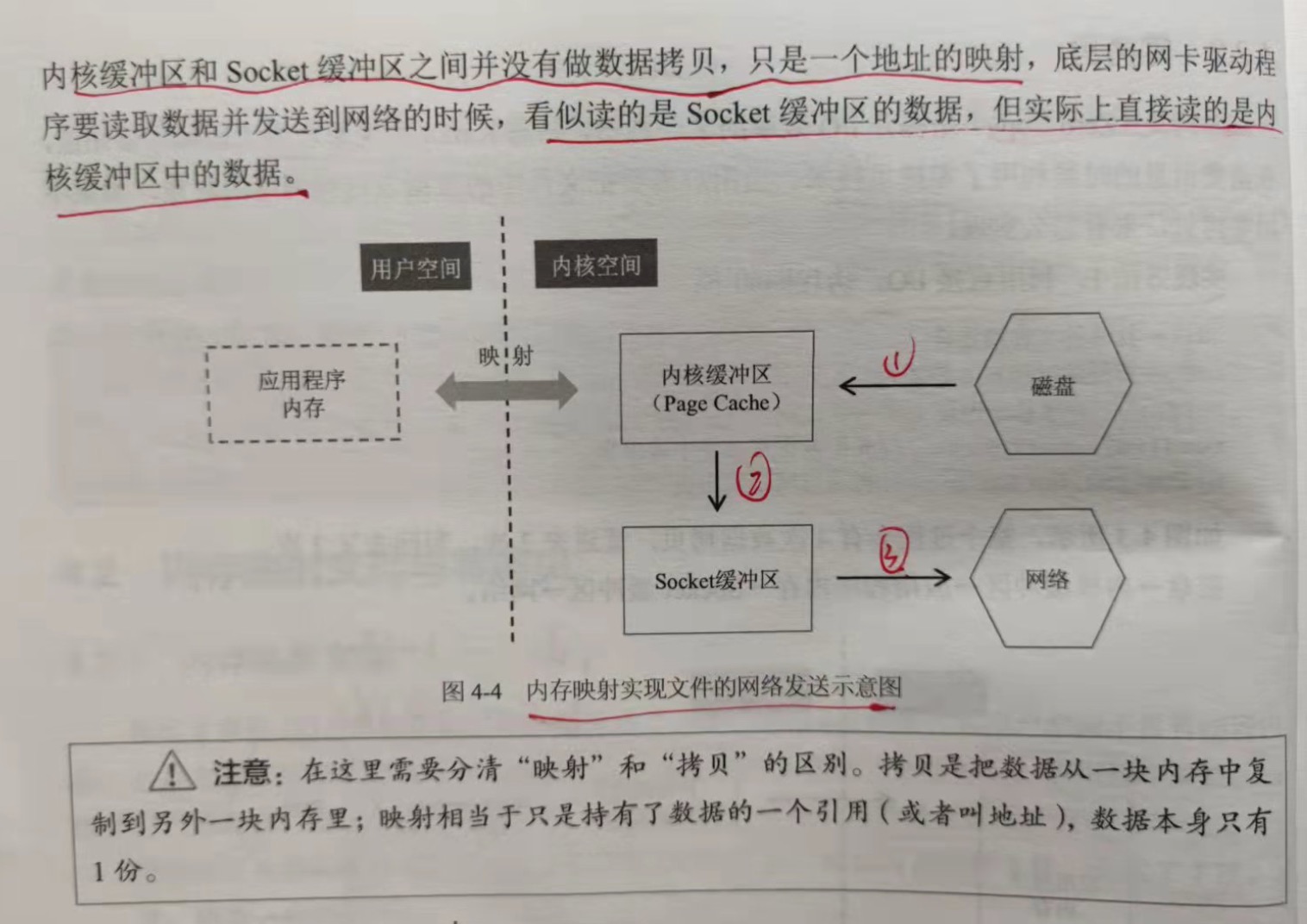
实现方法3:零拷贝
如果使用零拷贝,可能连内核缓冲区到socket缓冲区的拷贝也省略了。在内核缓冲区和socket缓冲区之间并没有做数据的拷贝,只是一个
地址的映射,底层的网卡驱动程序要读取数据并发送到网络的时候,看似读的是socket缓冲区的数据,实际上直接读的是内核缓冲区的数据。
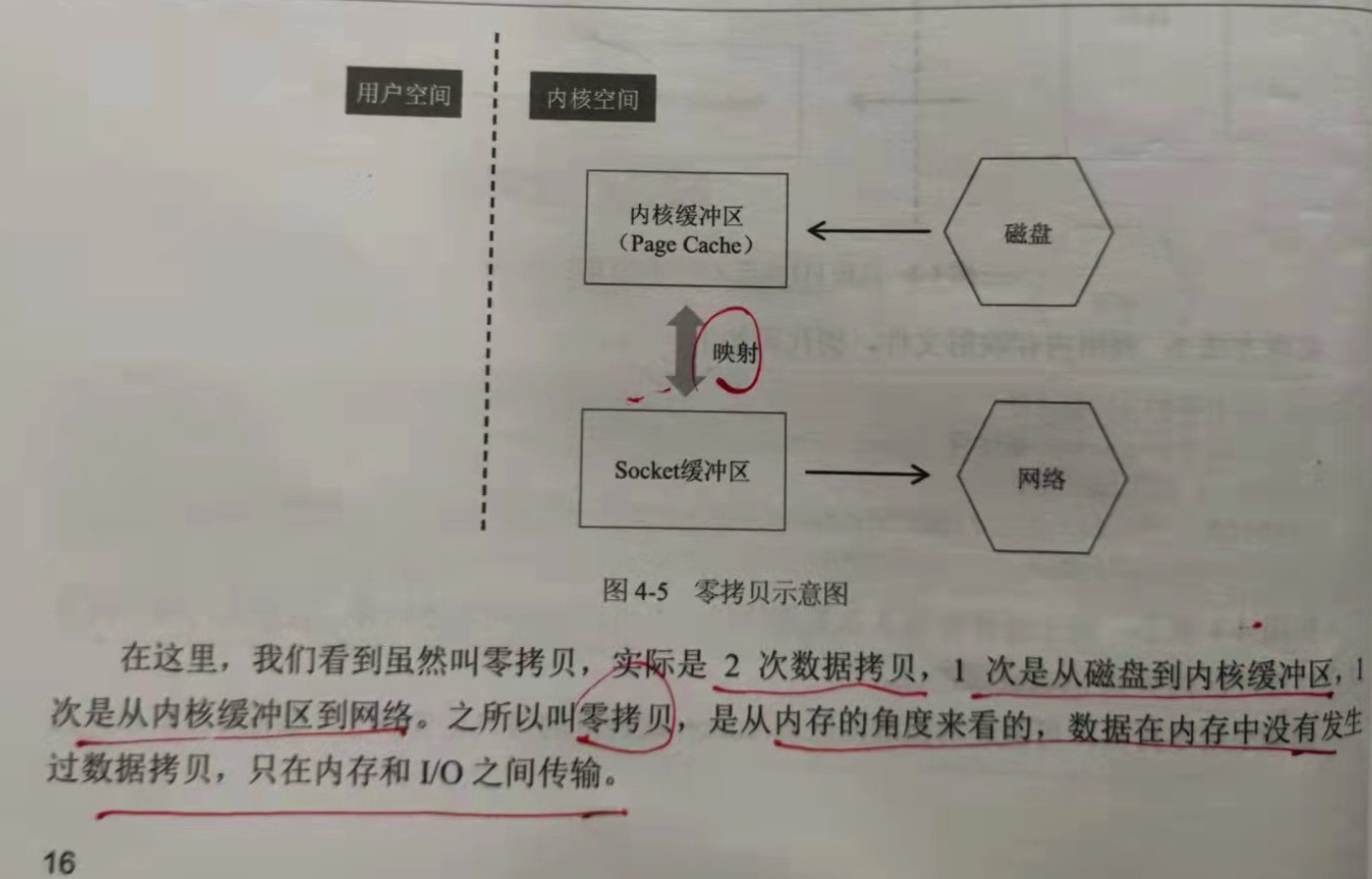
在这里,虽然叫零拷贝,实际是2次数据拷贝,1次是从磁盘到内核缓冲区,1次是从内核缓冲区到网络。之所以叫零拷贝,是从内存的角度来看,
数据在内存中没有发生过数据拷贝,只是在内存和IO之间传输。
在Linux系统中,API是:sendfile()。
4.3 网络I/O模型
4.3.1 实现层面的网络I/O模型
Linux 语境下面的IO模型:
1. 同步阻塞IO
就是Linux的read和write函数,在调用的时候会被阻塞,直到数据读取完成,或者写入成功。
2. 同步非阻塞IO
和同步阻塞IO的API是一样的,只是打开fd的时候会带有 O_NONBLOCK 参数。于是,当调用read和write函数的时候,如果没有准备好
数据,会立即返回,不会阻塞,然后让应用程序不断的去轮询。
3. IO多路复用
前面两种IO都只能用于简单的客户端开发。但对服务器程序来说,需要处理很多的fd(连接数可以达到几十万甚至百万)。如果都使用同步
阻塞IO,要处理这么多fd需要非常多的线程,每一个线程处理一个fd;如果使用非阻塞IO,要应用程序轮询这么大规模的fd。这两种办法都
不行,于是有了IO多路复用。
在Linux中,有三种IO多路复用的办法:select,poll,epoll。如 select(),该函数是阻塞调用,一次性把所有的fd传进去,当有fd
可读或者可写的时候,该函数会返回,返回结果也在这个函数的参数里面,告知应用程序哪些fd上面可读可写,然后下一步应用程序调用read和
write函数进行数据读写。
4. 异步IO
windows的异步IO是 IOCP。所谓异步IO是指读写都是由操作系统完成的,然后通过回调函数或者某种其他通信机制通知应用程序。
总结:
1.阻塞和非阻塞是从函数调用的角度来说的,而同步和异步是从"读写是谁完成的"角度来说的。
阻塞:如果读写没有就绪或者读写没有完成,则该函数一直等待。
非阻塞:函数立即返回,然后应用程序轮询。
同步:读写由应用程序完成。
异步:读写由操作系统完成,完成之后,通过回调或者事件通知应用程序。
2.按照这个定义可以知道,异步IO一定是非阻塞IO,不存在既是异步IO,又是阻塞IO的;同步IO可能是阻塞的,也可能是非阻塞的。归类后
总共有3种:同步阻塞IO,同步非阻塞IO,异步IO。
3.IO多路复用(select,poll,epoll)都是同步IO,因为read和write函数都是应用程序完成的,同时也是阻塞IO,因为select,poll,
epoll的调用都是阻塞的。
所以,当讲网络IO模型的时候,一定要注意讲的是操作系统层面的IO模型,还是上层的网络框架封装出来的IO模型(如asio,如Java的NIO,
在Linux平台,底层也是基于epoll)。
另外,对于异步IO一词,在操作系统的语境和上层应用的语境中,往往指代不一样。在操作系统的语境中,异步IO是指IOCP或者aio这种真正
的异步IO,epoll不被认为是异步IO;但在上层语境中,异步IO往往是指 JavaJDK或者网络框架(Netty)封装出来的概念,底层实现可能
epoll,也可能是真正的异步IO。
4.3.2 Reactor模式与Preactor模式
Reactor模式与Preactor模式,它们是网络框架的两种设计模式。
1.Reactor模式。主动模式。所谓主动模式,是指应用程序不断的轮询,询问操作系统或者网络框架,IO是否准备就绪。在Linux系统下的
select,poll,epoll就属于主动模式,需要应用程序中有一个循环一直轮询;Java中的NIO也属于这种模式。在这种模式下,实际的IO
操作还是应用程序执行。
2.Proactor模式。被动模式。应用程序把read和write函数操作全部交给操作系统或者网络框架,实际的IO操作由操作系统或者网络框架
完成,之后再回调应用程序。asio库就是典型的Proactor模式。
4.3.3 select、epoll的LT与ET
1.select
int select(int maxfdp1, fd_set* readfds, fd_set writefds, fd_set* execptfds, struct timeval* timeout);
说明:
1.因为fd是一个int值,所以fd_set其实是一个bit组数组,每1位表示一个fd是否有读写事件。
2.第一个参数是readfds或者writefds的下标的最大值+1。因为fd从0开始,+1才表示个数。
3.返回结果还是在readfds或者writefds里面,操作系统会重置所有bit位,告知应用程序到底哪个fd上面有事件,应用程序需要自己从0到
maxfds - 1遍历所有的fd,然后执行相应的read/write操作。
4.每次select调用返回后,下一次调用之前,要重新维护readfds和writefds。
2.poll
int poll(struct pollfd* fds, unsigned int nfds, int timeout);
struct pollfd {
int fd;
short events; //每个fd,两个bit数组,一个进去,一个出来
short revents;
};
从上面可以看出来,select,poll 每次调用都需要应用程序把fd的数组传进去,这个fd的数组每次都要在用户态和内核态之间传递,影响
效率。为了,epoll设计了"逻辑上的epfd"。epfd是一个数字,把fd数组关联到上面,然后每次向内核传递的是epfd这个数字。
3.epoll
//创建一个epoll句柄,size告诉内核监听的数目一共有多少。其中的size并不要求是准确的数字,只是告诉内核,计划监听多少个fd。实际
//通过epoll_ctl添加的fd数目可能大于这个值。
int epoll_create(int sieze);
//将一个fd增/删到epfd里,对应的事件也即读/写
int epoll_ctl(int epfd, int op, int fd, struct epoll_event* event);
//其中的maxevents也是可以自定义的,假如有100个fd,而maxevents只设置64,则其他fd上面的事件会在下次调用epoll_wait时返回
int epoll_wait(int epfd, struct_epoll_event* events, int maxevents, int timeout);
整个epoll的过程分为三个步骤:
1.事件注册
通过函数epoll_ctl实现。对服务器而言,是accept,read,write三种事件;对客户端而言,是connect,read,write。
2.轮询这3个事件是否就绪
通过函数epoll_wait实现。有事件发生,该函数就返回。
3.事件就绪,执行实际的IO操作
通过函数 accept/read/write实现。
事件就绪:
1.read事件就绪
远程有新数据来了,socket读写缓存区里有数据,需要调用read函数处理。
2.write事件就绪
是指本地的socket写缓冲区是否可写。如果写缓冲区没有满,则一直是可写的,write事件是就绪的,可以调用write函数。只有
当遇到发送大文件的场景,socket写缓冲区被占满时,write事件才不是就绪的状态。
3.accept事件就绪
有新的连接进入时,需要调用accept函数处理。
4.epoll的ET和LT模式
epoll里面有两种模式:LT(水平触发)和ET(边缘触发)。水平触发又称为条件触发,边缘触发又称为状态触发。
水平触发:
读缓冲区主要不为空,就会一直触发读事件;写缓冲区只要不满,就会一直触发写事件。
边缘触发:
读缓冲区的状态,从空转为非空的时候触发一次;写缓冲区的状态,从满转为非满的时候,触发一次。比如用户发送一个大文件,把
写缓冲区塞满后,之后缓冲区可以写了,就会发生一次从满到不满的切换。
关于LT和ET,有两种需要注意的问题:
1.对于LT模式,要避免"写的死循环"问题:写缓冲区为满的概率很小,即"写的条件"会一直满足,所以当用户注册了写事件却没有数据要写
的时候,它会一直触发,因此在LT模式下写完数据一定要取消写事件。
2.对于ET模式,"要避免 short read"问题。例如用户收到100个字节,它触发了1次,但用户只读取了50个字节,剩下的50个不读,它
也不会再次触发。因此在ET模式下,一定要把"读缓冲区"的数据一次性读完。
在实际开发中,一般倾向于用LT,这也是默认的模式。因为ET容易漏事件,一次触发如果没有处理好,就没有第二次机会。虽然LT重复触发看似
有少许的性能损耗,但代码写起来更安全。
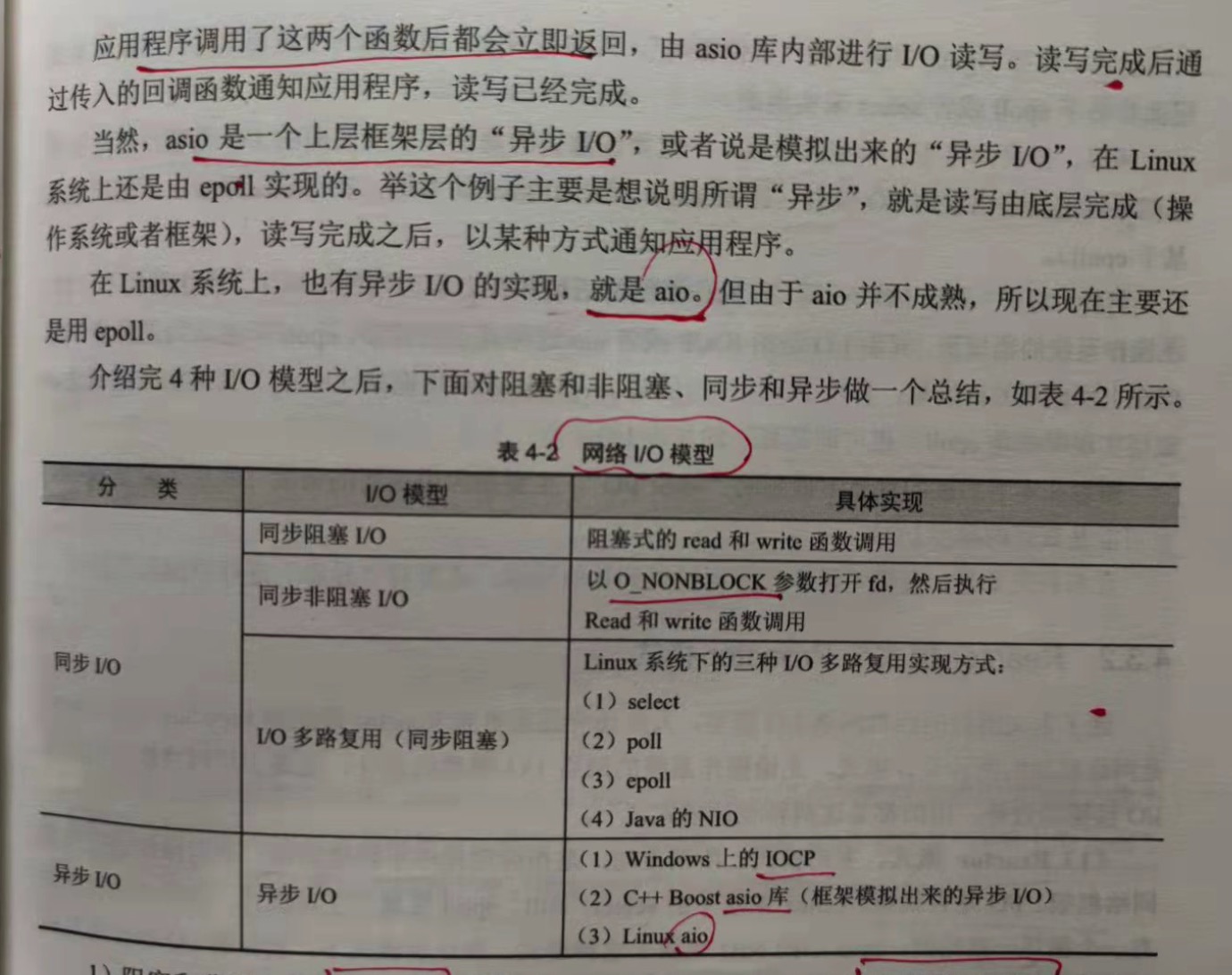
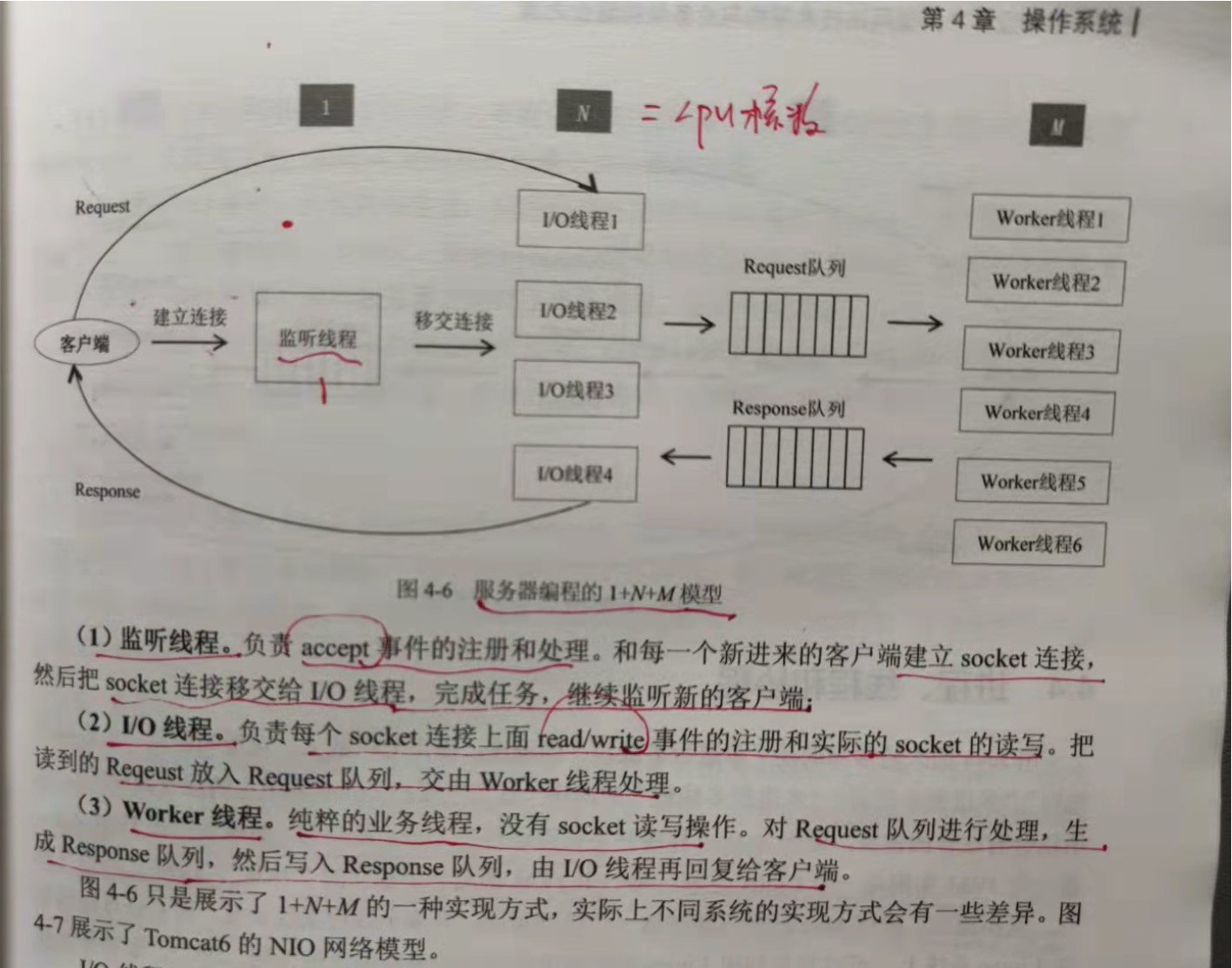
4.3.4 服务器编程的1 N M模型
在服务器的编程中,epoll 的编程步骤是由不同的线程负责的,即服务器编程的 1+N+M模型。
整个服务器有 1+N+M个线程,1个监听线程,N个IO线程,M个Worker线程。N的个数通常等于cpu核数,M的个数更具上层决定,通常有几百个。
1.监听线程
负责accept事件的注册和处理。和每一个新来的客户端建立socket连接,然后把socket连接转交给IO线程,完成任务,继续监听新的。
2.IO线程
负责每个socket连接上面read/write事件的注册和实际的socket读写。把读到的Request放入Request队列,交由Worker线程处理。
3.Worker线程
纯粹的业务线程,没有socket读写。对Request队列进行处理,生成Response队列,然后写入Response队列,由IO线程再回复给客户端。
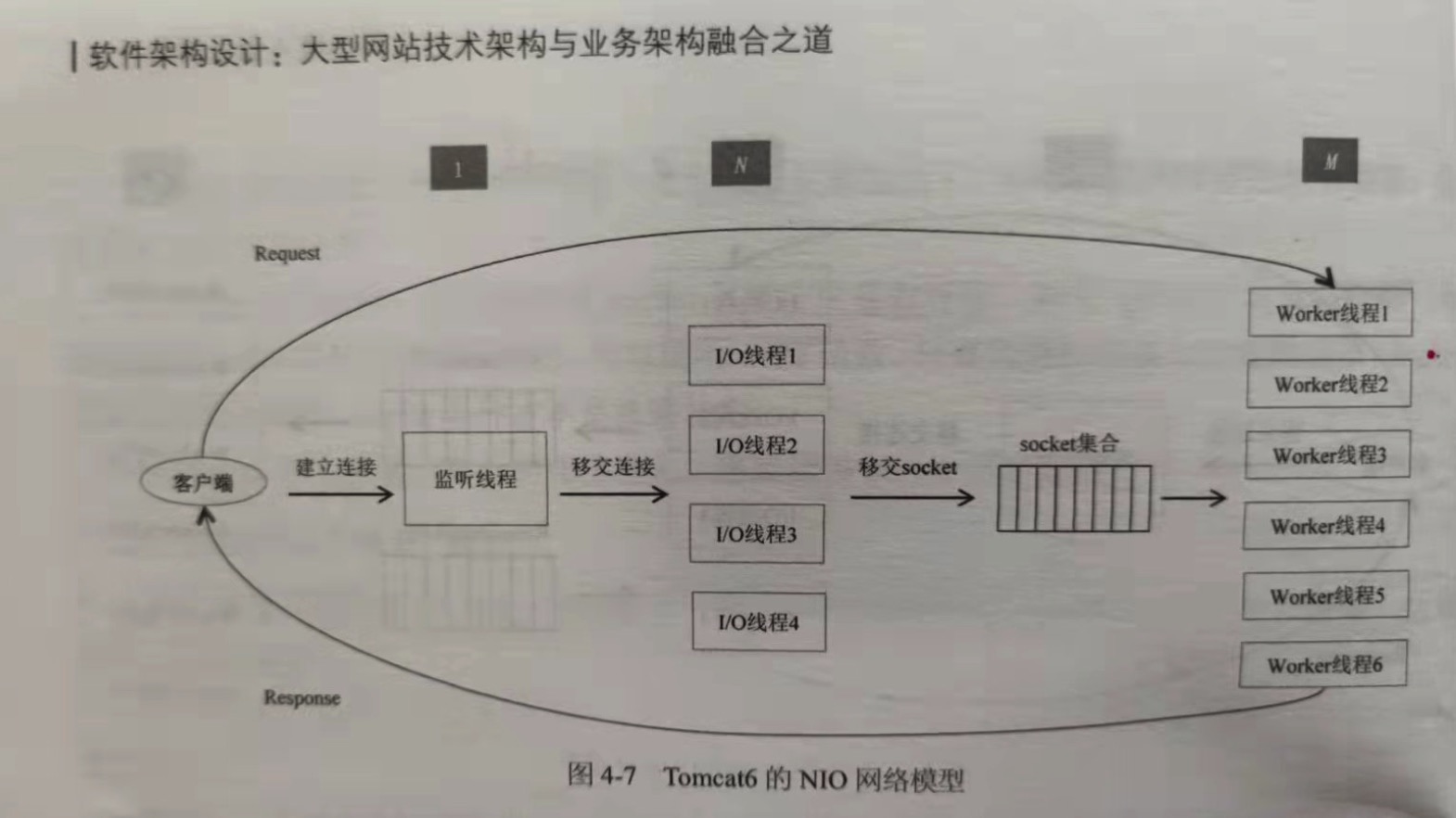
Tomcat6的NIO网络模型:
IO线程只负责read/write事件的注册和监听,执行了epoll里面的前面2个阶段,第三个阶段是在Worker线程里面做的。IO线程监听到一个
socket连接上有读事件,于是把socket转交给Worker线程,worker线程读出数据,处理完业务逻辑,直接返回给客户端。之所以可以这么做,是
因为IO线程已经检测到读事件就绪,所以当worker线程在读的时候不会等待。IO线程和worker线程之间交互,不再需要一来一回两个队列,直接
是一个socket集合。
4.4 进程、线程和协程
用Java的人通常写的是"单进程多线程"的程序;而用C++的人,可能写的是"单进程多线程","多进程单线程","多进程多线程"的程序。之所以会有这样的
差异,是因为Java程序并不是直接跑在Linux系统上的,而是运行在JVM之上,而一个JVM实例是Linux进程,每一个JVM都是一个独立的"沙盒",JVM之间互相
独立,互不通信。所以Java程序只能在这一个进程里面,开多个线程开发。而C++直接运行在Linux系统上,可以利用Linux系统提供的强大的进程间的通信机制
(IPC),很容易创造出多个进程,并实现进程间的通信。
1.为什么要多线程
多线程主要是为了应对IO密集型的应用。多线程能带来两方面的好处:
1.提供cpu利用率
2.提供IO吞吐
2.多进程
多线程存在两个问题:
1.线程间内存共享,要加线程锁;而加锁后会导致并发效率下降,同时复杂的加锁机制也导致将增加编码的难度;
2.过多的线程会造成线程间的上下文切换,导致效率低下。
在并发编程领域,有一个很重要的原则:"不要通过共享内存来实现通信,而应通过通信实现共享内存"。通俗点就是:"尽可能通过消息通信,而不是
共享内存来实现进程或线程之间的同步"。
进程是资源分配的基本单位,进程间不共享资源,通过管道或者socket方式通信(当然也可以共享内存),这种通信方式天生符合上面的并发设计原
则。而对于多线程,大家习惯于共享内存,然后通过加各种锁来实现同步。
除了锁的问题,多进程来带来的另外2个好处是:
1.一是减少了多线程在不同的cpu核间切换的开销;
2.多进程互相独立,意味着一个崩溃了,其他进程可以继续运行。
有了多进程之后,每个进程内部,可能是单线程,也可能是多线程,这往往取决于IO。
对于IO密集型的应用,要提高IO效率,则需要下面几种办法:
1.异步IO
异步化后,请求可以Pipeline处理,就不需要多线程了。但像mysql的JDBC提供的都是同步接口,不支持异步IO。
2.多线程
IO不支持异步,就只能开多个线程,每个线程都同步的调用IO,实际上是用多线程模拟了异步IO。如web应用服务器调用redis/mysql。
3.多协程
3.多协程
多线程除锁之外,还有一个问题是线程太多,切换的开销很大。虽然线程切换的开销比进程切换的开销已经小了很多,但还是不够。以
tomcat为例,在通常配置的服务器最多只能开几百个线程。如果再多,则线程切换的开销太大,并发效率反而会下降。这意味着tomcat最多
能并发的接受几百个请求。但如果是协程的话,可以开几万个。协程相比线程有两个关键特点:
a) 更好的利用cpu。线程的调度是操作系统完成的,应用程序干预不了,协程可以由应用程序自己调度。
b) 更好的利用内存。协程的堆栈大小不是固定的,用多少申请多少,内存利用率更高。
4.5 无锁(内存屏障与CAS)
4.5.1 内存屏障
Linux 内核的 kfifo.c 源码实现了无锁。核心的要点是:
1.读可以多线程,写必须是单线程,也称为 Single-Writer Principle。如果是多线程写,则做不到无锁。
2.在上面的基础上,使用了内存屏障。也就是 smp_wmb()调用。从用法来说,内存屏障是在两行代码之间插入一个栅栏,如下所示:
代码第1行
代码第2行
内存屏障
代码第3行
代码第4行
在第2行代码和第3行代码之间插入一个内存屏障,这样前2行代码就不会跑到后2行代码的后面执行。虽然第1行,第2行之间可能被重排序;
第3行和第4行可能被重排序,但第1行,第2行不会跑到第3行后面去。
所谓的重排序,通俗的讲,就是cpu不会按照开发者的代码顺序来执行。
基于内存屏障,有了Java中的 volatile 关键字,再加上单线程写的原则,就有了Java中无锁并发框架 --- Disruptor,其核心就是 "
一写多读,完全无锁"。
4.5.2 CAS
如果是多线程写,则内存屏障也不够用了,这时要用到CAS。CAS是cpu层面提供的一个硬件原子指令,实现对同一个值的Compare和Set两个
操作的原子化。
基于CAS,上层可以实现 乐观锁,无锁队列,无锁栈,无锁链表。





























以上是关于4.软件架构设计:大型网站技术架构与业务架构融合之道 --- 操作系统的主要内容,如果未能解决你的问题,请参考以下文章