Binder | 对象的生命周期
Posted 冬天的毛毛雨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Binder | 对象的生命周期相关的知识,希望对你有一定的参考价值。
本文分析基于android S(12)
前言
当我们使用AIDL接口时,拿到的对象本质上属于Stub.Proxy类。通过Binder通信,便可以将数据传输给Server进程中的Stub对象(继承于Binder类)。然而这些只是冰山一角,在水面以下还隐藏着许多其他对象。有了它们,通信才能够建立。我们以ApplicationThread为例,通信发起方拿到的是IApplicationThread.Stub.Proxy对象,数据最终到达的是ApplicationThread对象(ApplicationThread继承于IApplicationThread.Stub类)。下图展示了整个通信链路建立时需要创建的不同对象,总共有9个。
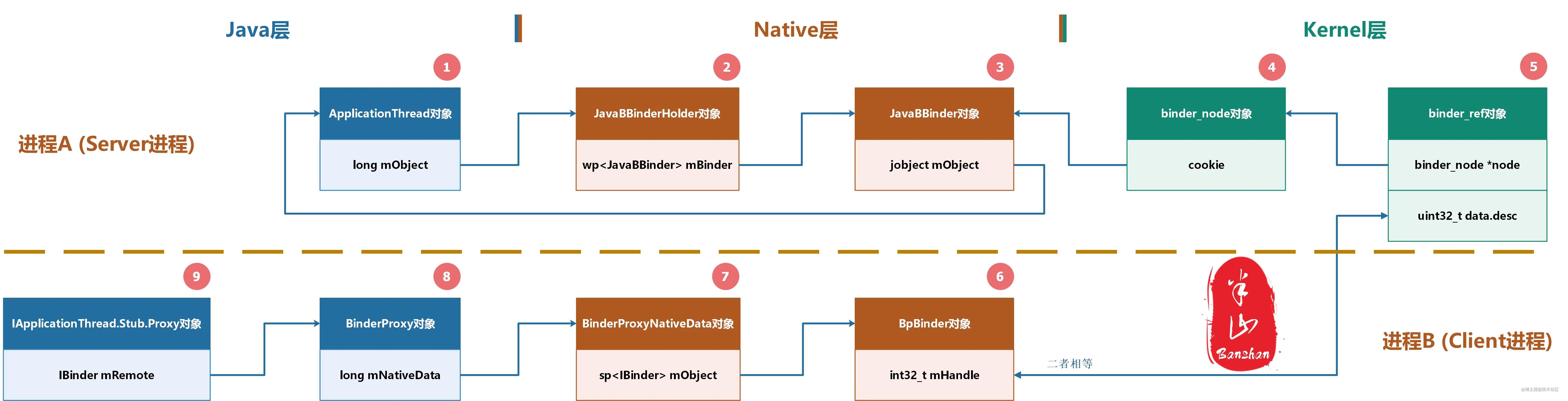
图中的序号表示的是这些对象的创建顺序,第一个出现的是Stub对象(也可称为Binder对象,因为它的父类是Binder,根据多态原则我们可以将它转为Binder对象)。Binder对象构造时会顺带创建Native层的JavaBBinderHolder对象,这样我们便拥有了1、2两个对象。而后续3~9这些对象只有当我们将Binder对象作为数据传输给对端进程后才能创建出来。通信链路建立以后,即便Binder对象在本进程内没有被任何其他Java对象引用,它也不应该被回收,因为它随时会收到来自其他进程的通信数据。这种关系可以被形容为:Server进程的Binder对象被Client进程的BinderProxy对象引用了。请记住这句话,它是本文思想的核心。只有当其他进程中对应的Proxy对象都被GC回收以后,Binder对象不再可能接收新的通信数据时,它才可以被回收,如下图所示。
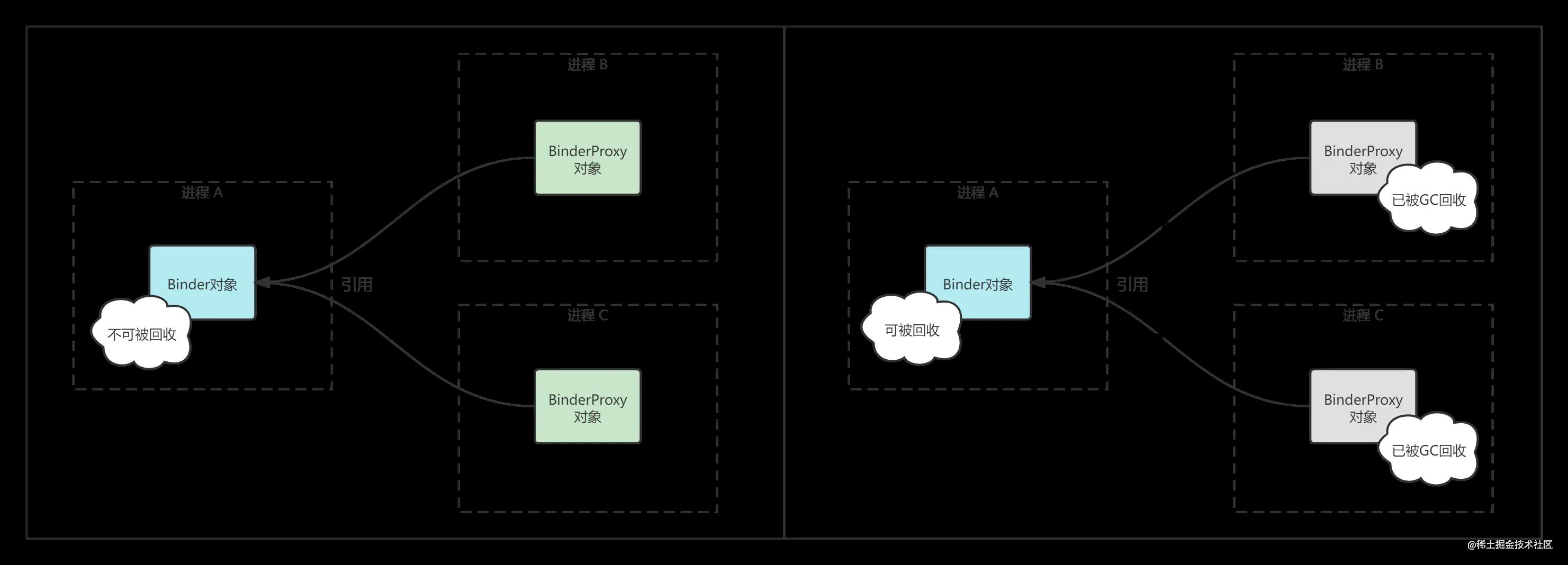
为了建立这种跨进程的引用关系,我们需要一些复杂的过程和中间变量的配合。一旦了解了这种引用关系的内部细节,我们便可以知道这些对象的生命周期是如何管理的。理解生命周期,其实核心回答的就是两个问题:
- Binder对象如何保证在BinderProxy对象存在时不被回收?
- Binder对象如何在所有BinderProxy消亡时被回收?
带着这些问题,接下来我们将要深入细节,看看Android到底是如何管理这些对象的生命周期的。
1. Server进程
1.1 Binder对象
整个过程始于Binder对象的创建。
public Binder(@Nullable String descriptor) {
mObject = getNativeBBinderHolder();
NoImagePreloadHolder.sRegistry.registerNativeAllocation(this, mObject);
mDescriptor = descriptor;
}
Binder的构造方法中做了三件事:
getNativeBBinderHolder在Native层创建了一个新的JavaBBinderHolder对象,并将它的地址返回给mObject字段。registerNativeAllocation用于管理与Java对象有关的native内存。- 将AIDL接口名称记录在mDescriptor中。
此时创建的Binder对象还只是一个普通的Java对象,如果不将它作为Binder数据(Binder通信既可以传输普通数据,也可以传输Binder类实例化后的对象)传输给其他进程,那么后续的JavaBBinder对象、binder_node对象都不会创建,它也就不会具备跨进程通信的能力。
通过new方式创建出来的JavaBBinderHolder对象并没有通过强弱指针(智能指针)进行管理,而是将地址寄存在Binder对象的字段中,因此它的回收也只能由Binder对象发起。
根据NativeAllocationRegistry机制可知,Binder对象被GC回收时会调用Binder_destroy函数,这样JavaBBinderHolder对象也就被销毁了。
static void Binder_destroy(void* rawJbh)
{
JavaBBinderHolder* jbh = (JavaBBinderHolder*) rawJbh;
ALOGV("Java Binder: deleting holder %p", jbh);
delete jbh;
}
1.2 JavaBBinder对象
当我们将Binder对象作为数据传输给对端进程时,首先需要将它装入Parcel对象,这就好比数据打包。Java层的writeStrongBinder方法会进入到Native层,其中会有两个关键的步骤,一个是ibinderForJavaObject函数,另一个是parcel->writeStrongBinder函数。
static void android_os_Parcel_writeStrongBinder(JNIEnv* env, jclass clazz, jlong nativePtr, jobject object)
{
Parcel* parcel = reinterpret_cast<Parcel*>(nativePtr);
if (parcel != NULL) {
const status_t err = parcel->writeStrongBinder(ibinderForJavaObject(env, object)); //object即为Binder对象
if (err != NO_ERROR) {
signalExceptionForError(env, clazz, err);
}
}
}
ibinderForJavaObject函数会根据Java对象生成Native层的JavaBBinder对象。在构造JavaBBinder对象时,我们会通过env->NewGlobalRef的方式将Binder对象加入到art::globals_列表中,这样Binder对象在每次GC时都会被标记为GC Root,也便无法被回收。通过这种方式,我们将Java层的Binder对象和Native层的JavaBBinder对象进行了深度捆绑,只有当JavaBBinder对象销毁时,Binder对象才能从art::globals_中清除,重新恢复自由身后他就可以被回收了。
JavaBBinder(JNIEnv* env, jobject /* Java Binder */ object)
: mVM(jnienv_to_javavm(env)), mObject(env->NewGlobalRef(object))
{
ALOGV("Creating JavaBBinder %p\\n", this);
gNumLocalRefsCreated.fetch_add(1, std::memory_order_relaxed);
gcIfManyNewRefs(env);
}
ibinderForJavaObject函数的返回值为sp类型。这里的sp表示"strong pointer",它是Android中单独实现的一套智能指针系统,切勿和C++中的shared_ptr混淆。sp是一个模板类,其中作为模板的类必须继承自RefBase,比如这里的IBinder就继承了RefBase。sp通过引用计数的方式来管理所指向的C++对象,这里的话是管理新创建的JavaBBinder对象。关于RefBase的详细知识不是本文的重点,因此这里介绍一个参考文章,供没有背景知识的同学参考。
sp<IBinder> ibinderForJavaObject(JNIEnv* env, jobject obj)
{
...
// Instance of Binder?
if (env->IsInstanceOf(obj, gBinderOffsets.mClass)) {
JavaBBinderHolder* jbh = (JavaBBinderHolder*)
env->GetLongField(obj, gBinderOffsets.mObject);
return jbh->get(env, obj);
}
...
}
sp<JavaBBinder> get(JNIEnv* env, jobject obj)
{
AutoMutex _l(mLock);
sp<JavaBBinder> b = mBinder.promote();
if (b == NULL) {
b = new JavaBBinder(env, obj); //b被赋值时,JavaBBinder对象的强引用计数+1,此时该值为1
...
}
return b;
}
当JavaBBinder对象的强引用计数减为0时,JavaBBinder便会被销毁,这就是Android中智能指针的基本逻辑。sp对象的创建会增加JavaBBinder的强引用计数(+1),sp对象的销毁会减少JavaBBinder的强引用计数(-1)。因此上述get函数中JavaBBinder对象的强引用计数值呈现出如下规律:
b = new JavaBBinder(env, obj)会对JavaBBinder对象的强引用计数值+1,于是该值为1。return b会根据局部变量b创建一个sp类型的返回值,这里采用的是拷贝构造,因此JavaBBinder的强引用计数值+1,于是该值为2。- 函数返回,局部变量b销毁,JavaBBinder的强引用计数值-1,于是该值为1。
ibinderForJavaObject返回后,返回值将作为参数继续进入到parcel->writeStrongBinder函数。
status_t Parcel::writeStrongBinder(const sp<IBinder>& val)
{
return flattenBinder(val);
}
status_t Parcel::flattenBinder(const sp<IBinder>& binder)
{
...
flat_binder_object obj;
if (binder != nullptr) {
BBinder *local = binder->localBinder();
if (!local) {
...
} else {
...
obj.hdr.type = BINDER_TYPE_BINDER;
obj.binder = reinterpret_cast<uintptr_t>(local->getWeakRefs());
obj.cookie = reinterpret_cast<uintptr_t>(local);
}
}
...
status_t status = writeObject(obj, false);
return finishFlattenBinder(binder);
}
flattenBinder会根据JavaBBinder对象构造一个flat_binder_object对象,并将其写入Parcel。而作为参数的sp对象binder在函数返回后将不复存在,因此指向的JavaBBinder对象强引用计数值将会继续减1。根据上文可知,此时JavaBBinder对象的强引用计数值为1,如果flattenBinder里没有其他地方增加JavaBBinder对象的强引用计数值,那么函数返回后,强引用计数值归零,JavaBBinder对象将会被销毁。而这显然是不符合预期的。
等等,让我们站在宏观的角度来重新思考这个问题。
当我们将构造后的flat_binder_object对象写入Parcel,意味着该Parcel对象隐式地引用了JavaBBinder对象,因此它需要保证自己在使用flat_binder_object对象的过程中,JavaBBinder对象不被销毁。基于这个逻辑的判断,flattenBinder中调用writeObject将flat_binder_object对象写入Parcel的过程里一定会增加JavaBBinder的强引用计数。下面我们来看看代码的设计是否符合我们逻辑的推断。
status_t Parcel::writeObject(const flat_binder_object& val, bool nullMetaData)
{
...
// Need to write meta-data?
if (nullMetaData || val.binder != 0) {
mObjects[mObjectsSize] = mDataPos;
acquire_object(ProcessState::self(), val, this, &mOpenAshmemSize);
mObjectsSize++;
}
...
}
static void acquire_object(const sp<ProcessState>& proc,
const flat_binder_object& obj, const void* who, size_t* outAshmemSize)
{
switch (obj.hdr.type) {
case BINDER_TYPE_BINDER:
if (obj.binder) {
LOG_REFS("Parcel %p acquiring reference on local %p", who, obj.cookie);
reinterpret_cast<IBinder*>(obj.cookie)->incStrong(who);
}
return;
...
}
果然,当传输的是JavaBBinder对象时,writeObject会调用acquire_object来增加JavaBBinder对象的强引用计数(通过incStrong函数)。这样一来,flattenBinder函数返回后JavaBBinder对象也就不会被销毁了。
那么acquire_object里增加的强引用计数何时再减掉呢?答案自然是Parcel对象回收的时候。事实上,Parcel对象在通信链路的建立过程中只是二传手的角色,它只能保证JavaBBinder一直存活到对端进程创建出BinderProxy对象的时候,而后续JavaBBinder的生命就交给了对端进程。
下面我们来看一个典型的AIDL gnerated方法。
@Override
public void registerRemoteAnimations(android.os.IBinder token, android.view.RemoteAnimationDefinition definition) throws android.os.RemoteException
{
android.os.Parcel _data = android.os.Parcel.obtain();
android.os.Parcel _reply = android.os.Parcel.obtain();
try {
_data.writeInterfaceToken(DESCRIPTOR);
_data.writeStrongBinder(token); //第一步是将Binder对象写入Parcel中,会调用acquire_object增加JavaBBinder的强引用计数
if ((definition!=null)) {
_data.writeInt(1);
definition.writeToParcel(_data, 0);
}
else {
_data.writeInt(0);
}
mRemote.transact(Stub.TRANSACTION_registerRemoteAnimations, _data, _reply, 0); //第二步是进行binder通信
_reply.readException();
}
finally {
_reply.recycle();
_data.recycle(); //第三步是回收Parcel对象,进而会调用release_object减少JavaBBinder的强引用计数
}
}
大体过程可以分为三步:
_data.writeStrongBinder将Binder对象写入Parcel,其内部会将JavaBBinder写入Parcel(native),并同时增加JavaBBinder的强引用计数。mRemote.transact将Binder对象传输给对端进程,对端进程接收到数据后会创建相应的BinderProxy对象。_data.recycle回收Parcel对象,同时减少JavaBBinder的强引用计数。
如果希望通信链路在_data.recycle后不被破坏,那么必须要在mRemote.transact里增加JavaBBinder的强引用计数,这实际上也是将JavaBBinder的生命交由BinderProxy管理的过程。接下来,让我们深入到驱动里去一探究竟。
1.3 binder_node对象
进入Binder驱动后,binder_transaction函数会遍历本次传输的所有Binder对象。接着最关键的一步是binder_translate_binder,它会根据flat_binder_object生成内核空间中相应的binder_node和binder_ref对象,并将BINDER_TYPE_BINDER的类型更改为BINDER_TYPE_HANDLE,表明我们虽然传输的是一个Binder对象,但是对端拿到的将是Proxy对象。
case BINDER_TYPE_BINDER:
case BINDER_TYPE_WEAK_BINDER: {
struct flat_binder_object *fp;
fp = to_flat_binder_object(hdr);
ret = binder_translate_binder(fp, t, thread);
...
} break;
binder_translate_binder首先会通过binder_new_node创建一个新的binder_node对象,紧接着调用binder_inc_ref_for_node去创建binder_ref对象。
static int binder_translate_binder(struct flat_binder_object *fp,
struct binder_transaction *t,
struct binder_thread *thread)
{
struct binder_node *node;
struct binder_proc *proc = thread->proc;
struct binder_proc *target_proc = t->to_proc;
struct binder_ref_data rdata;
int ret = 0;
node = binder_get_node(proc, fp->binder);
if (!node) {
node = binder_new_node(proc, fp);
if (!node)
return -ENOMEM;
}
...
ret = binder_inc_ref_for_node(target_proc, node,
fp->hdr.type == BINDER_TYPE_BINDER,
&thread->todo, &rdata);
...
}
binder_inc_ref_for_node里会做两件事,一是生成对端进程的binder_ref对象,通过它能够找到刚刚创建的binder_node对象;二是调用binder_inc_ref_olocked来管理binder_node和binder_ref对象的生命周期。
static int binder_inc_ref_for_node(struct binder_proc *proc,
struct binder_node *node,
bool strong,
struct list_head *target_list,
struct binder_ref_data *rdata)
{
struct binder_ref *ref;
struct binder_ref *new_ref = NULL;
int ret = 0;
binder_proc_lock(proc);
ref = binder_get_ref_for_node_olocked(proc, node, NULL);
if (!ref) {
binder_proc_unlock(proc);
new_ref = kzalloc(sizeof(*ref), GFP_KERNEL);
if (!new_ref)
return -ENOMEM;
binder_proc_lock(proc);
ref = binder_get_ref_for_node_olocked(proc, node, new_ref);
}
ret = binder_inc_ref_olocked(ref, strong, target_list);
}
binder_inc_ref_olocked里既增加binder_ref对象的strong值,也会进一步调用binder_inc_node增加相应binder_node对象的引用值。binder_ref对象的strong不为0,表示它被人引用无法被销毁。这里之所以增加,是因为接下来type为BINDER_TYPE_HANDLE的数据会写入binder buffer,因此binder buffer会引用binder_ref对象。
static int binder_inc_ref_olocked(struct binder_ref *ref, int strong,
struct list_head *target_list)
{
int ret;
if (strong) {
if (ref->data.strong == 0) {
ret = binder_inc_node(ref->node, 1, 1, target_list);
if (ret)
return ret;
}
ref->data.strong++;
} else {
if (ref->data.weak == 0) {
ret = binder_inc_node(ref->node, 0, 1, target_list);
if (ret)
return ret;
}
ref->data.weak++;
}
return 0;
}
binder_inc_node_nilocked里会做两件事,一是增加binder_node对象的internal_strong_refs值 ,另一个是往thread的todo列表中新增一个BINDER_WORK_NODE的任务。binder_node里的引用字段有些复杂,主要是名称具有歧义。其主要使用的字段有internal_strong_refs和local_strong_refs,前者表明binder_node对象被一个binder_ref对象所引用,进一步引申的含义是binder_node对象被另一个进程所引用;后者表明binder_node对象被本进程所引用,它不一定指具体的持有关系,而是在本进程执行某些任务时,binder_node对象不能被释放。
static int binder_inc_node_nilocked(struct binder_node *node, int strong,
int internal,
struct list_head *target_list)
{
struct binder_proc *proc = node->proc;
if (strong) {
if (internal) {
node->internal_strong_refs++;
} else
node->local_strong_refs++;
if (!node->has_strong_ref && target_list) {
struct binder_thread *thread = container_of(target_list,
struct binder_thread, todo);
binder_dequeue_work_ilocked(&node->work);
BUG_ON(&thread->todo != target_list);
binder_enqueue_deferred_thread_work_ilocked(thread,
&node->work);
}
这个被加入到thread todo列表中的任务是一个延迟任务,但不管是同步通信还是异步通信,它们都会在transact结束前完成。
BINDER_WORK_NODE任务处理时会做两件事:
- node的has_weak_ref和has_strong_ref设置为true,pending_weak_ref和pending_strong_ref设置为1,local_weak_refs和local_strong_refs均自增。
- 给用户空间返回BR_INCREFS和BR_ACQUIRE。
那么如何去理解这两件事呢?
首先,给用户空间返回的指令会让用户空间去增加JavaBBinder对象的强引用计数和弱引用计数,保证JavaBBinder在有其他进程引用时不会被销毁。而pending_weak_ref/pending_strong_ref/local_weak_refs/local_strong_refs之所以被置上,均是在等待用户空间操作的完成。当用户空间完成增加引用计数的操作后,会重新回到内核空间,带回BC_INCREFS_DONE和BC_ACQUIRE_DONE的指令,将之前的四个值复位,表明用户空间已经完成这项任务。
case BINDER_WORK_NODE: {
struct binder_node *node = container_of(w, struct binder_node, work);
int strong, weak;
binder_uintptr_t node_ptr = node->ptr;
binder_uintptr_t node_cookie = node->cookie;
int node_debug_id = node->debug_id;
int has_weak_ref;
int has_strong_ref;
void __user *orig_ptr = ptr;
strong = node->internal_strong_refs ||
node->local_strong_refs;
weak = !hlist_empty(&node->refs) ||
node->local_weak_refs ||
node->tmp_refs || strong;
has_strong_ref = node->has_strong_ref;
has_weak_ref = node->has_weak_ref;
if (weak && !has_weak_ref) {
node->has_weak_ref = 1;
node->pending_weak_ref = 1;
node->local_weak_refs++;
}
if (strong && !has_strong_ref) {
node->has_strong_ref = 1;
node->pending_strong_ref = 1;
node->local_strong_refs++;
}
if (weak && !has_weak_ref)
ret = binder_put_node_cmd(
proc, thread, &ptr, node_ptr,
node_cookie, node_debug_id,
BR_INCREFS, "BR_INCREFS");
if (!ret && strong && !has_strong_ref)
ret = binder_put_node_cmd(
proc, thread, &ptr, node_ptr,
node_cookie, node_debug_id,
BR_ACQUIRE, "BR_ACQUIRE");
这样一来,我们就可以保证_data.recycle结束后,JavaBBinder对象依然不被销毁的效果了。至此,本进程的工作就已经完成了。
让我们来梳理一下各个对象的依赖关系。
- Java层的Binder对象回收时,Native层的JavaBBinderHolder对象才能被销毁。
- Native层的JavaBBinder对象被销毁时,Java层的Binder对象才能从全局引用表中出来,也才能够被GC回收。
- Kernel层的binder_node对象的internal_strong_refs和local_strong_refs值均减为0时,Native层的JavaBBinder对象的强引用计数才能归零,也才能被销毁。
所以对于本进程而言,这些对象的销毁关系仿佛像多米诺骨牌一样,只有前面的倒下,后面的才能够顺次倒下。根据上述依赖关系可知,如果想要销毁这些对象,首先要做的就是将binder_node对象的internal_strong_refs和local_strong_refs的值减为0(local_strong_refs通常为0)。而internal_strong_refs其实记录的就是有多少个进程引用了该Binder对象。
2. Client进程
此时的binder_ref对象已经创建,ref->data.strong的值为1,表明binder buffer正在引用它。当Client进程接收到通信请求后,会先调用IPCThreadState::executeCommand方法。这里会先创建一个局部的Parcel对象buffer,来接收binder buffer中的数据。一旦buffer销毁后,binder buffer也将被释放,而此前给binder_ref对象增加的strong值也将减回去。
case BR_TRANSACTION:
{
...
Parcel buffer;
buffer.ipcSetDataReference(
reinterpret_cast<const uint8_t*>(tr.data.ptr.buffer),
tr.data_size,
reinterpret_cast<const binder_size_t*>(tr.data.ptr.offsets),
tr.offsets_size/sizeof(binder_size_t), freeBuffer);
以上是关于Binder | 对象的生命周期的主要内容,如果未能解决你的问题,请参考以下文章